 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLaplace Inference for Multi-fidelity Gaussian Process Classification
Paper and Code

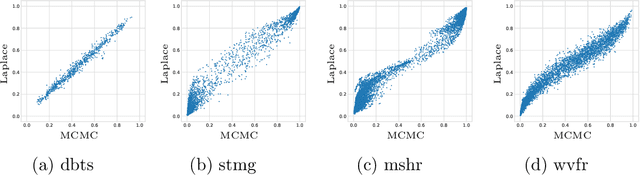


In this paper we address a classification problem where two sources of labels with different levels of fidelity are available. Our approach is to combine data from both sources by applying a co-kriging schema on latent functions, which allows the model to account item-dependent labeling discrepancy. We provide an extension for Laplace inference for Gaussian process classification, that takes into account multi-fidelity data. We evaluate the proposed method on real and synthetic datasets and show that it is more resistant to different levels of discrepancy between sources, than other approaches for data fusion. Our method can provide accuracy/cost trade-off for a number of practical tasks such as crowd-sourced data annotation and feasibility regions construction in engineering design.