 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Differentiable Language Model Adversarial Attack on Text Classifiers
Jul 23, 2021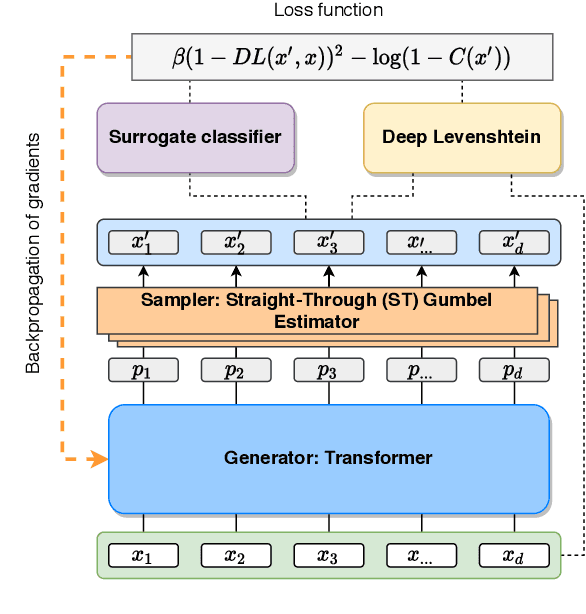
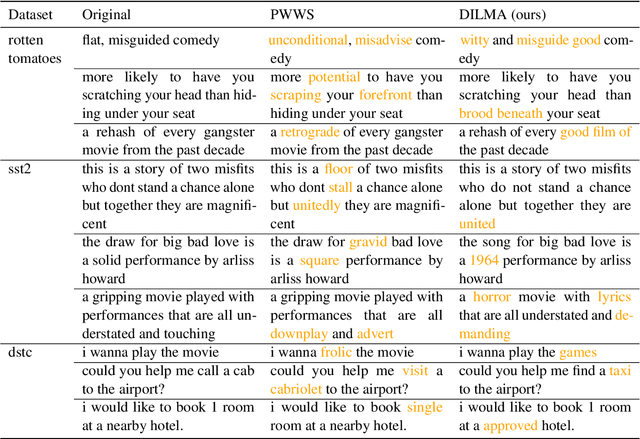
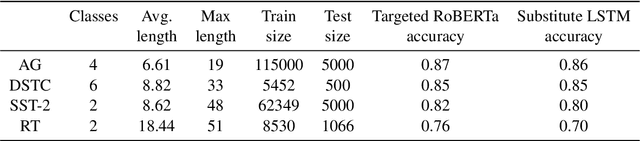
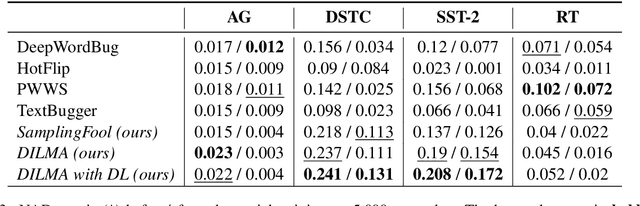
Robustness of huge Transformer-based models for natural language processing is an important issue due to their capabilities and wide adoption. One way to understand and improve robustness of these models is an exploration of an adversarial attack scenario: check if a small perturbation of an input can fool a model. Due to the discrete nature of textual data, gradient-based adversarial methods, widely used in computer vision, are not applicable per~se. The standard strategy to overcome this issue is to develop token-level transformations, which do not take the whole sentence into account. In this paper, we propose a new black-box sentence-level attack. Our method fine-tunes a pre-trained language model to generate adversarial examples. A proposed differentiable loss function depends on a substitute classifier score and an approximate edit distance computed via a deep learning model. We show that the proposed attack outperforms competitors on a diverse set of NLP problems for both computed metrics and human evaluation. Moreover, due to the usage of the fine-tuned language model, the generated adversarial examples are hard to detect, thus current models are not robust. Hence, it is difficult to defend from the proposed attack, which is not the case for other attacks.
Adversarial Attacks on Deep Models for Financial Transaction Records
Jun 15, 2021
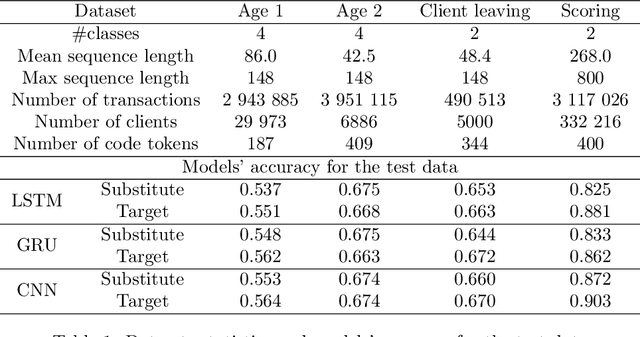
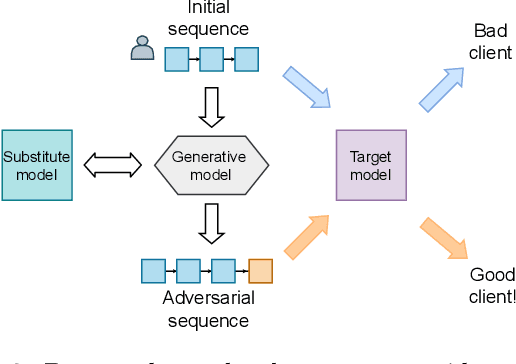
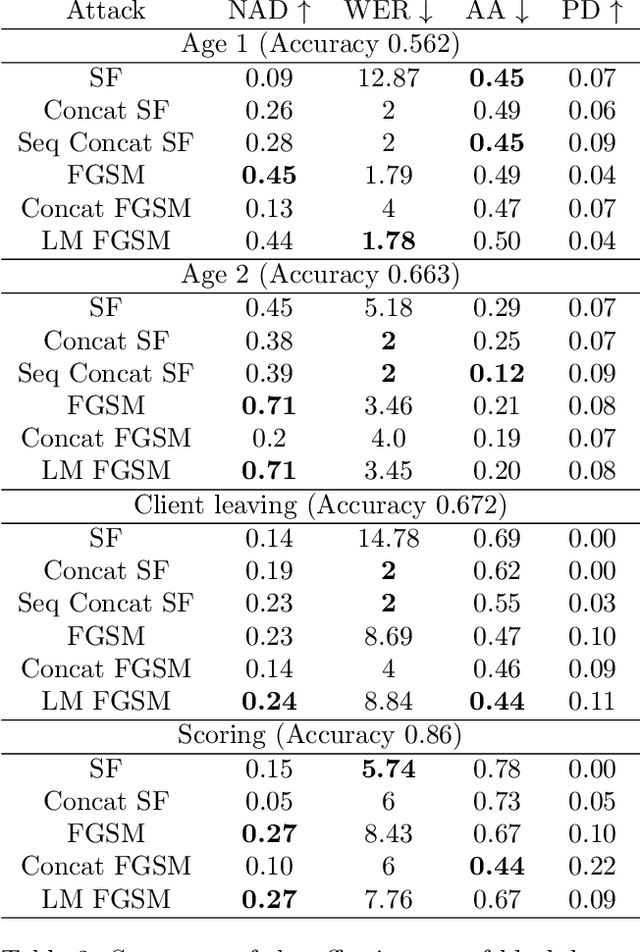
Machine learning models using transaction records as inputs are popular among financial institutions. The most efficient models use deep-learning architectures similar to those in the NLP community, posing a challenge due to their tremendous number of parameters and limited robustness. In particular, deep-learning models are vulnerable to adversarial attacks: a little change in the input harms the model's output. In this work, we examine adversarial attacks on transaction records data and defences from these attacks. The transaction records data have a different structure than the canonical NLP or time series data, as neighbouring records are less connected than words in sentences, and each record consists of both discrete merchant code and continuous transaction amount. We consider a black-box attack scenario, where the attack doesn't know the true decision model, and pay special attention to adding transaction tokens to the end of a sequence. These limitations provide more realistic scenario, previously unexplored in NLP world. The proposed adversarial attacks and the respective defences demonstrate remarkable performance using relevant datasets from the financial industry. Our results show that a couple of generated transactions are sufficient to fool a deep-learning model. Further, we improve model robustness via adversarial training or separate adversarial examples detection. This work shows that embedding protection from adversarial attacks improves model robustness, allowing a wider adoption of deep models for transaction records in banking and finance.
Gradient-based adversarial attacks on categorical sequence models via traversing an embedded world
Mar 09, 2020

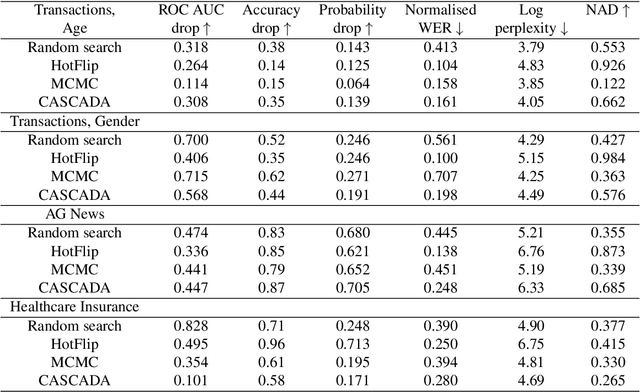

An adversarial attack paradigm explores various scenarios for vulnerability of machine and especially deep learning models: we can apply minor changes to the model input to force a classifier's failure for a particular example. Most of the state of the art frameworks focus on adversarial attacks for images and other structured model inputs. The adversarial attacks for categorical sequences can also be harmful if they are successful. However, successful attacks for inputs based on categorical sequences should address the following challenges: (1) non-differentiability of the target function, (2) constraints on transformations of initial sequences, and (3) diversity of possible problems. We handle these challenges using two approaches. The first approach adopts Monte-Carlo methods and allows usage in any scenario, the second approach uses a continuous relaxation of models and target metrics, and thus allows using general state of the art methods on adversarial attacks with little additional effort. Results for money transactions, medical fraud, and NLP datasets suggest the proposed methods generate reasonable adversarial sequences that are close to original ones, but fool machine learning models even for blackbox adversarial attacks.