 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradient-based adversarial attacks on categorical sequence models via traversing an embedded world
Mar 09, 2020

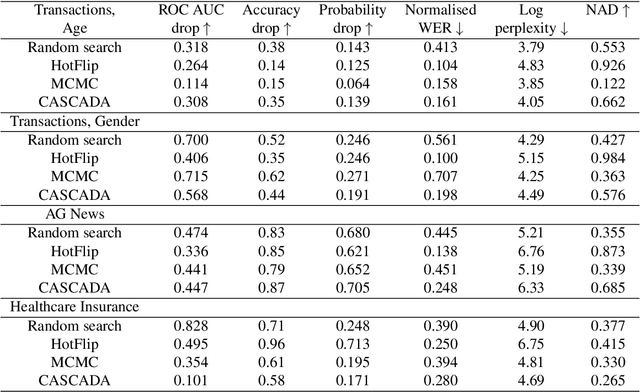

An adversarial attack paradigm explores various scenarios for vulnerability of machine and especially deep learning models: we can apply minor changes to the model input to force a classifier's failure for a particular example. Most of the state of the art frameworks focus on adversarial attacks for images and other structured model inputs. The adversarial attacks for categorical sequences can also be harmful if they are successful. However, successful attacks for inputs based on categorical sequences should address the following challenges: (1) non-differentiability of the target function, (2) constraints on transformations of initial sequences, and (3) diversity of possible problems. We handle these challenges using two approaches. The first approach adopts Monte-Carlo methods and allows usage in any scenario, the second approach uses a continuous relaxation of models and target metrics, and thus allows using general state of the art methods on adversarial attacks with little additional effort. Results for money transactions, medical fraud, and NLP datasets suggest the proposed methods generate reasonable adversarial sequences that are close to original ones, but fool machine learning models even for blackbox adversarial attacks.