 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine Translation Models Stand Strong in the Face of Adversarial Attacks
Sep 10, 2023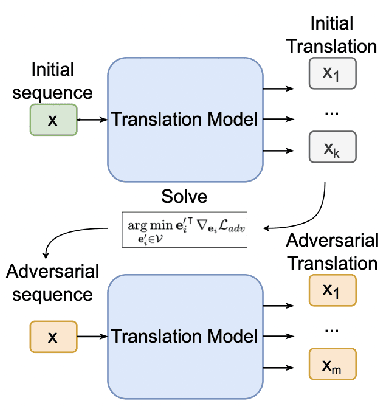
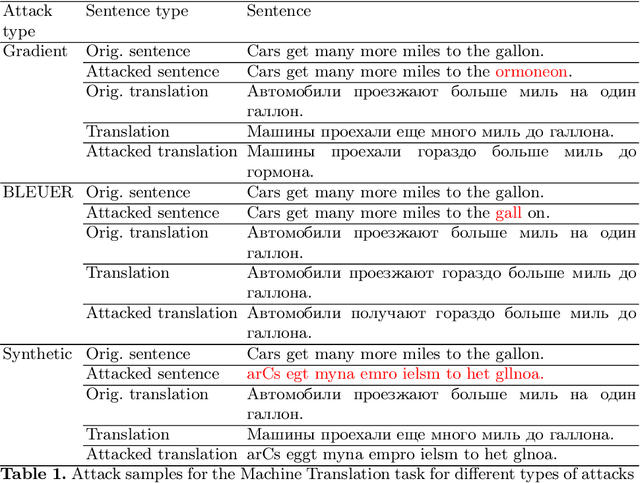
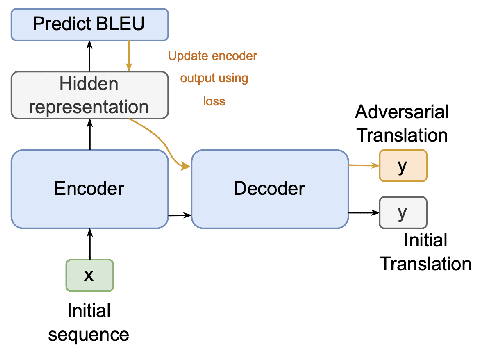
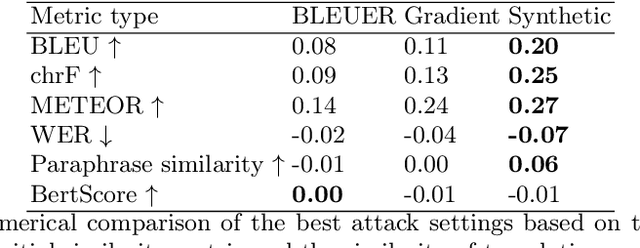
Adversarial attacks expose vulnerabilities of deep learning models by introducing minor perturbations to the input, which lead to substantial alterations in the output. Our research focuses on the impact of such adversarial attacks on sequence-to-sequence (seq2seq) models, specifically machine translation models. We introduce algorithms that incorporate basic text perturbation heuristics and more advanced strategies, such as the gradient-based attack, which utilizes a differentiable approximation of the inherently non-differentiable translation metric. Through our investigation, we provide evidence that machine translation models display robustness displayed robustness against best performed known adversarial attacks, as the degree of perturbation in the output is directly proportional to the perturbation in the input. However, among underdogs, our attacks outperform alternatives, providing the best relative performance. Another strong candidate is an attack based on mixing of individual characters.
Template-based Approach to Zero-shot Intent Recognition
Jun 22, 2022
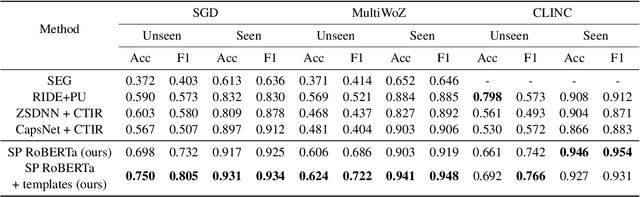
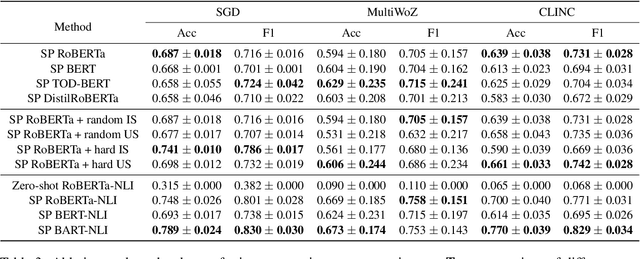
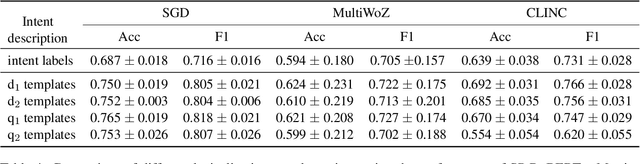
The recent advances in transfer learning techniques and pre-training of large contextualized encoders foster innovation in real-life applications, including dialog assistants. Practical needs of intent recognition require effective data usage and the ability to constantly update supported intents, adopting new ones, and abandoning outdated ones. In particular, the generalized zero-shot paradigm, in which the model is trained on the seen intents and tested on both seen and unseen intents, is taking on new importance. In this paper, we explore the generalized zero-shot setup for intent recognition. Following best practices for zero-shot text classification, we treat the task with a sentence pair modeling approach. We outperform previous state-of-the-art f1-measure by up to 16\% for unseen intents, using intent labels and user utterances and without accessing external sources (such as knowledge bases). Further enhancement includes lexicalization of intent labels, which improves performance by up to 7\%. By using task transferring from other sentence pair tasks, such as Natural Language Inference, we gain additional improvements.
A Single Example Can Improve Zero-Shot Data Generation
Aug 16, 2021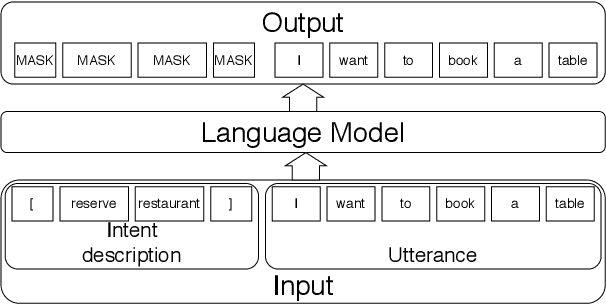
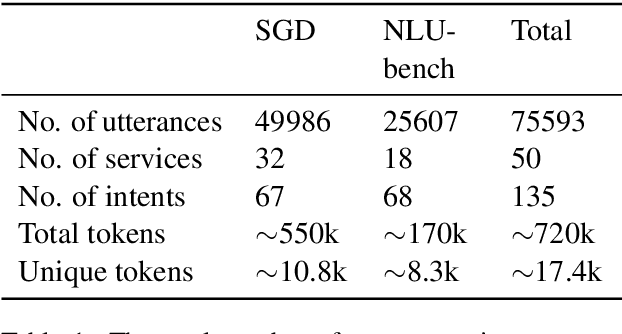
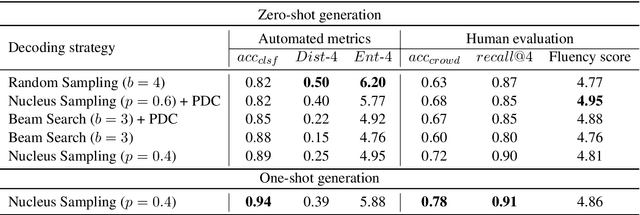
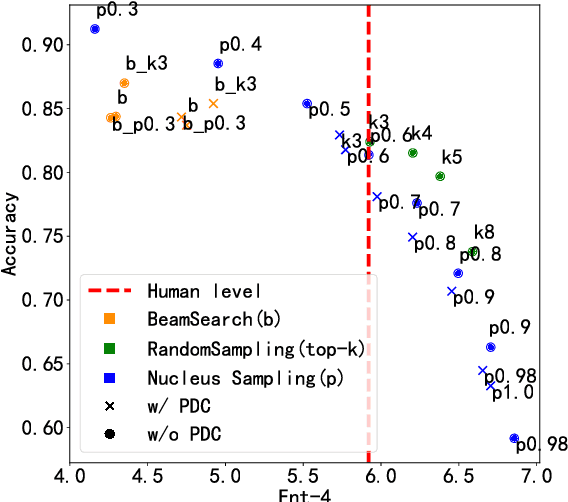
Sub-tasks of intent classification, such as robustness to distribution shift, adaptation to specific user groups and personalization, out-of-domain detection, require extensive and flexible datasets for experiments and evaluation. As collecting such datasets is time- and labor-consuming, we propose to use text generation methods to gather datasets. The generator should be trained to generate utterances that belong to the given intent. We explore two approaches to generating task-oriented utterances. In the zero-shot approach, the model is trained to generate utterances from seen intents and is further used to generate utterances for intents unseen during training. In the one-shot approach, the model is presented with a single utterance from a test intent. We perform a thorough automatic, and human evaluation of the dataset generated utilizing two proposed approaches. Our results reveal that the attributes of the generated data are close to original test sets, collected via crowd-sourcing.
A Differentiable Language Model Adversarial Attack on Text Classifiers
Jul 23, 2021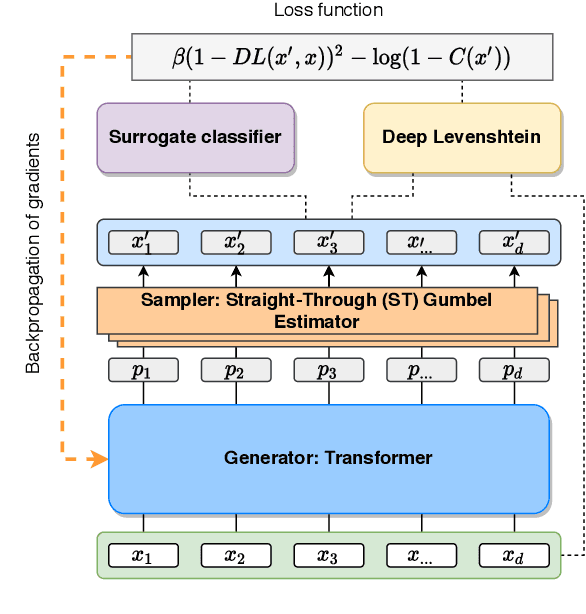
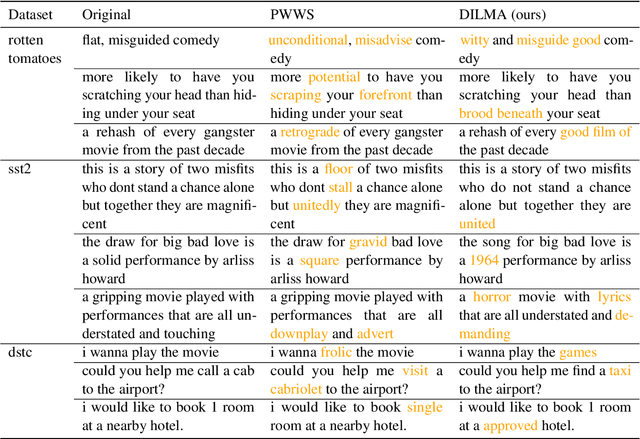
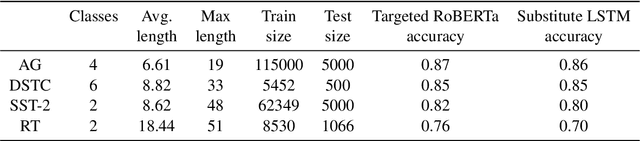
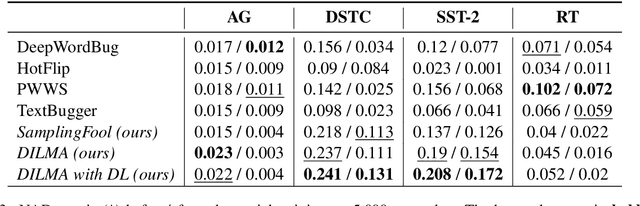
Robustness of huge Transformer-based models for natural language processing is an important issue due to their capabilities and wide adoption. One way to understand and improve robustness of these models is an exploration of an adversarial attack scenario: check if a small perturbation of an input can fool a model. Due to the discrete nature of textual data, gradient-based adversarial methods, widely used in computer vision, are not applicable per~se. The standard strategy to overcome this issue is to develop token-level transformations, which do not take the whole sentence into account. In this paper, we propose a new black-box sentence-level attack. Our method fine-tunes a pre-trained language model to generate adversarial examples. A proposed differentiable loss function depends on a substitute classifier score and an approximate edit distance computed via a deep learning model. We show that the proposed attack outperforms competitors on a diverse set of NLP problems for both computed metrics and human evaluation. Moreover, due to the usage of the fine-tuned language model, the generated adversarial examples are hard to detect, thus current models are not robust. Hence, it is difficult to defend from the proposed attack, which is not the case for other attacks.