 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCalibration-Reasoning Framework for Descriptive Speech Quality Assessment
Mar 10, 2026Explainable speech quality assessment requires moving beyond Mean Opinion Scores (MOS) to analyze underlying perceptual dimensions. To address this, we introduce a novel post-training method that tailors the foundational Audio Large Language Model for multidimensional reasoning, detection and classification of audio artifacts. First, a calibration stage aligns the model to predict predefined perceptual dimensions. Second, a reinforcement learning stage leverages Group Relative Policy Optimization (GRPO) with dimension-specific rewards to heavily enhance accuracy of descriptions and temporal localization of quality issues. With this approach we reach state-of-the-art results of 0.71 mean PCC score on the multidimensional QualiSpeech benchmark and 13% improvement in MOS prediction driven by RL-based reasoning. Furthermore, our fine-grained GRPO rewards substantially advance the model's ability to pinpoint and classify audio artifacts in time.
Effective Interplay between Sparsity and Quantization: From Theory to Practice
May 31, 2024



The increasing size of deep neural networks necessitates effective model compression to improve computational efficiency and reduce their memory footprint. Sparsity and quantization are two prominent compression methods that have individually demonstrated significant reduction in computational and memory footprints while preserving model accuracy. While effective, the interplay between these two methods remains an open question. In this paper, we investigate the interaction between these two methods and assess whether their combination impacts final model accuracy. We mathematically prove that applying sparsity before quantization is the optimal sequence for these operations, minimizing error in computation. Our empirical studies across a wide range of models, including OPT and Llama model families (125M-8B) and ViT corroborate these theoretical findings. In addition, through rigorous analysis, we demonstrate that sparsity and quantization are not orthogonal; their interaction can significantly harm model accuracy, with quantization error playing a dominant role in this degradation. Our findings extend to the efficient deployment of large models in resource-limited compute platforms and reduce serving cost, offering insights into best practices for applying these compression methods to maximize efficacy without compromising accuracy.
Machine Translation Models Stand Strong in the Face of Adversarial Attacks
Sep 10, 2023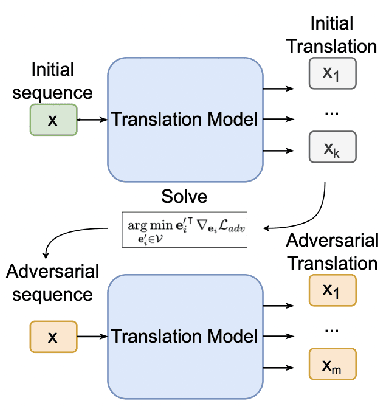
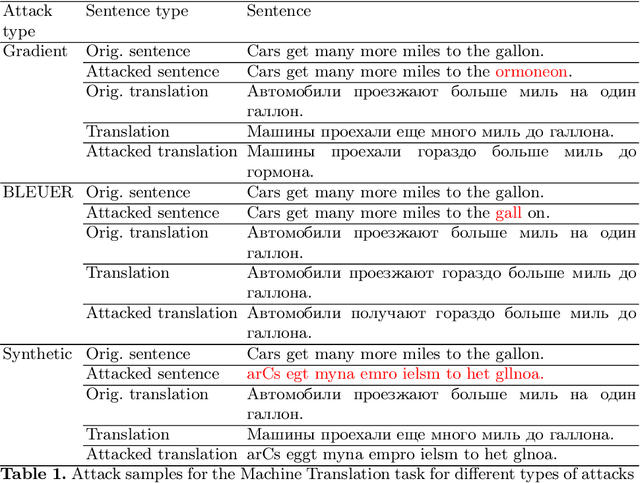
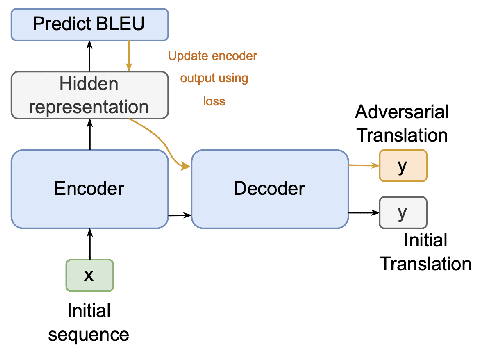
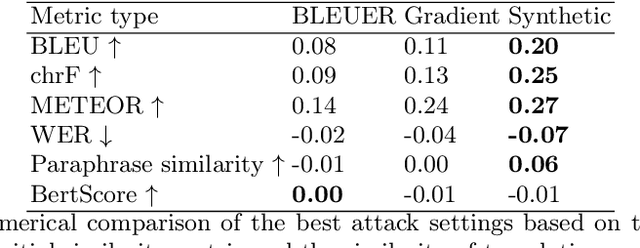
Adversarial attacks expose vulnerabilities of deep learning models by introducing minor perturbations to the input, which lead to substantial alterations in the output. Our research focuses on the impact of such adversarial attacks on sequence-to-sequence (seq2seq) models, specifically machine translation models. We introduce algorithms that incorporate basic text perturbation heuristics and more advanced strategies, such as the gradient-based attack, which utilizes a differentiable approximation of the inherently non-differentiable translation metric. Through our investigation, we provide evidence that machine translation models display robustness displayed robustness against best performed known adversarial attacks, as the degree of perturbation in the output is directly proportional to the perturbation in the input. However, among underdogs, our attacks outperform alternatives, providing the best relative performance. Another strong candidate is an attack based on mixing of individual characters.
Uncertainty Estimation of Transformers' Predictions via Topological Analysis of the Attention Matrices
Aug 22, 2023Determining the degree of confidence of deep learning model in its prediction is an open problem in the field of natural language processing. Most of the classical methods for uncertainty estimation are quite weak for text classification models. We set the task of obtaining an uncertainty estimate for neural networks based on the Transformer architecture. A key feature of such mo-dels is the attention mechanism, which supports the information flow between the hidden representations of tokens in the neural network. We explore the formed relationships between internal representations using Topological Data Analysis methods and utilize them to predict model's confidence. In this paper, we propose a method for uncertainty estimation based on the topological properties of the attention mechanism and compare it with classical methods. As a result, the proposed algorithm surpasses the existing methods in quality and opens up a new area of application of the attention mechanism, but requires the selection of topological features.