 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffective Interplay between Sparsity and Quantization: From Theory to Practice
May 31, 2024



The increasing size of deep neural networks necessitates effective model compression to improve computational efficiency and reduce their memory footprint. Sparsity and quantization are two prominent compression methods that have individually demonstrated significant reduction in computational and memory footprints while preserving model accuracy. While effective, the interplay between these two methods remains an open question. In this paper, we investigate the interaction between these two methods and assess whether their combination impacts final model accuracy. We mathematically prove that applying sparsity before quantization is the optimal sequence for these operations, minimizing error in computation. Our empirical studies across a wide range of models, including OPT and Llama model families (125M-8B) and ViT corroborate these theoretical findings. In addition, through rigorous analysis, we demonstrate that sparsity and quantization are not orthogonal; their interaction can significantly harm model accuracy, with quantization error playing a dominant role in this degradation. Our findings extend to the efficient deployment of large models in resource-limited compute platforms and reduce serving cost, offering insights into best practices for applying these compression methods to maximize efficacy without compromising accuracy.
Accuracy Boosters: Epoch-Driven Mixed-Mantissa Block Floating-Point for DNN Training
Nov 22, 2022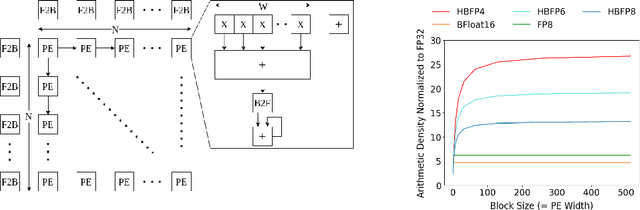
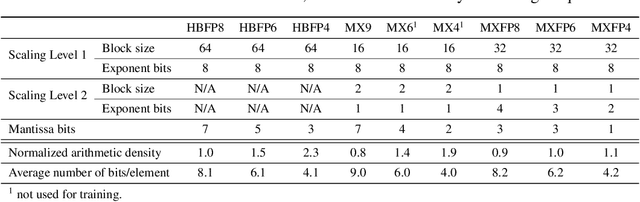
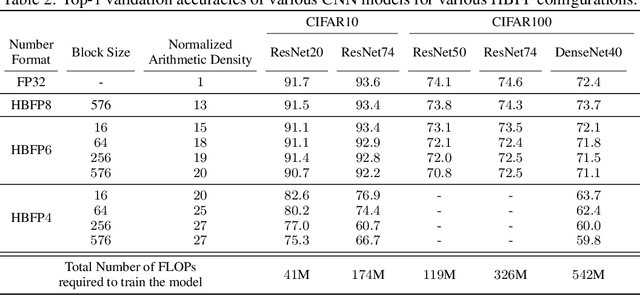
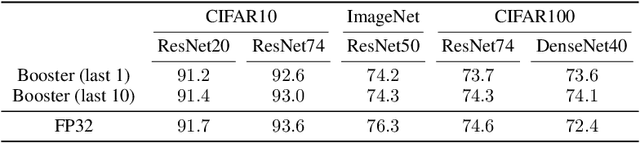
The unprecedented growth in DNN model complexity, size and the amount of training data have led to a commensurate increase in demand for computing and a search for minimal encoding. Recent research advocates Hybrid Block Floating-Point (HBFP) as a technique that minimizes silicon provisioning in accelerators by converting the majority of arithmetic operations in training to 8-bit fixed-point. In this paper, we perform a full-scale exploration of the HBFP design space including minimal mantissa encoding, varying block sizes, and mixed mantissa bit-width across layers and epochs. We propose Accuracy Boosters, an epoch-driven mixed-mantissa HBFP that uses 6-bit mantissa only in the last epoch and converts $99.7\%$ of all arithmetic operations in training to 4-bit mantissas. Accuracy Boosters enable reducing silicon provisioning for an HBFP training accelerator by $16.98\times$ as compared to FP32, while preserving or outperforming FP32 accuracy.