 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffective Interplay between Sparsity and Quantization: From Theory to Practice
May 31, 2024



The increasing size of deep neural networks necessitates effective model compression to improve computational efficiency and reduce their memory footprint. Sparsity and quantization are two prominent compression methods that have individually demonstrated significant reduction in computational and memory footprints while preserving model accuracy. While effective, the interplay between these two methods remains an open question. In this paper, we investigate the interaction between these two methods and assess whether their combination impacts final model accuracy. We mathematically prove that applying sparsity before quantization is the optimal sequence for these operations, minimizing error in computation. Our empirical studies across a wide range of models, including OPT and Llama model families (125M-8B) and ViT corroborate these theoretical findings. In addition, through rigorous analysis, we demonstrate that sparsity and quantization are not orthogonal; their interaction can significantly harm model accuracy, with quantization error playing a dominant role in this degradation. Our findings extend to the efficient deployment of large models in resource-limited compute platforms and reduce serving cost, offering insights into best practices for applying these compression methods to maximize efficacy without compromising accuracy.
Accuracy Boosters: Epoch-Driven Mixed-Mantissa Block Floating-Point for DNN Training
Nov 22, 2022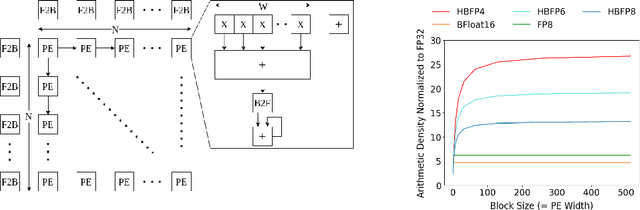
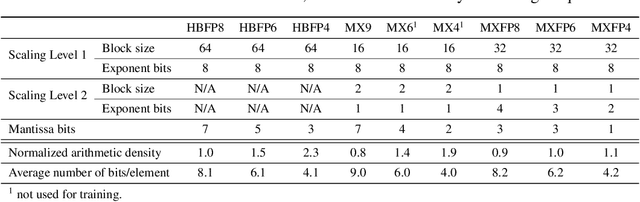
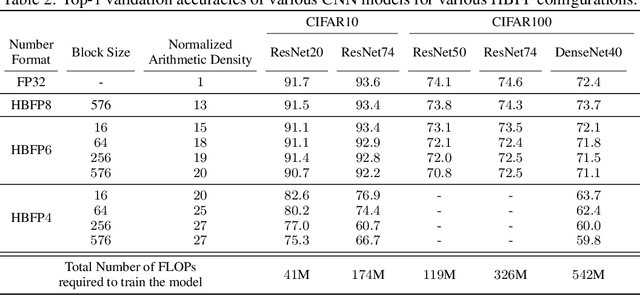
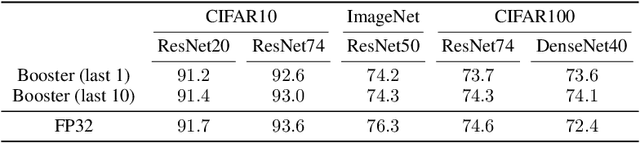
The unprecedented growth in DNN model complexity, size and the amount of training data have led to a commensurate increase in demand for computing and a search for minimal encoding. Recent research advocates Hybrid Block Floating-Point (HBFP) as a technique that minimizes silicon provisioning in accelerators by converting the majority of arithmetic operations in training to 8-bit fixed-point. In this paper, we perform a full-scale exploration of the HBFP design space including minimal mantissa encoding, varying block sizes, and mixed mantissa bit-width across layers and epochs. We propose Accuracy Boosters, an epoch-driven mixed-mantissa HBFP that uses 6-bit mantissa only in the last epoch and converts $99.7\%$ of all arithmetic operations in training to 4-bit mantissas. Accuracy Boosters enable reducing silicon provisioning for an HBFP training accelerator by $16.98\times$ as compared to FP32, while preserving or outperforming FP32 accuracy.
Scale-out Systolic Arrays
Mar 22, 2022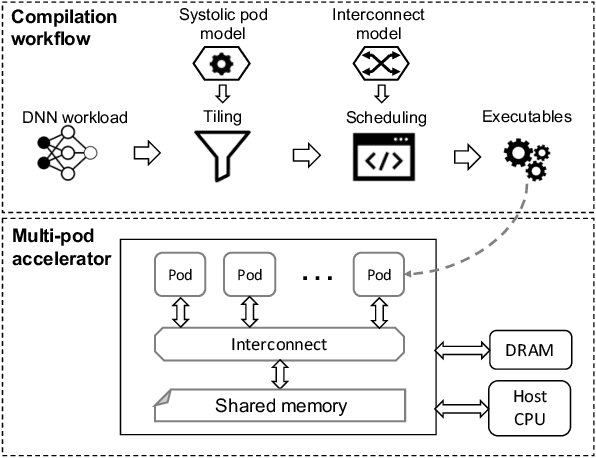
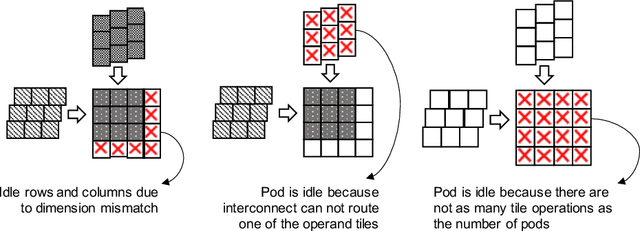
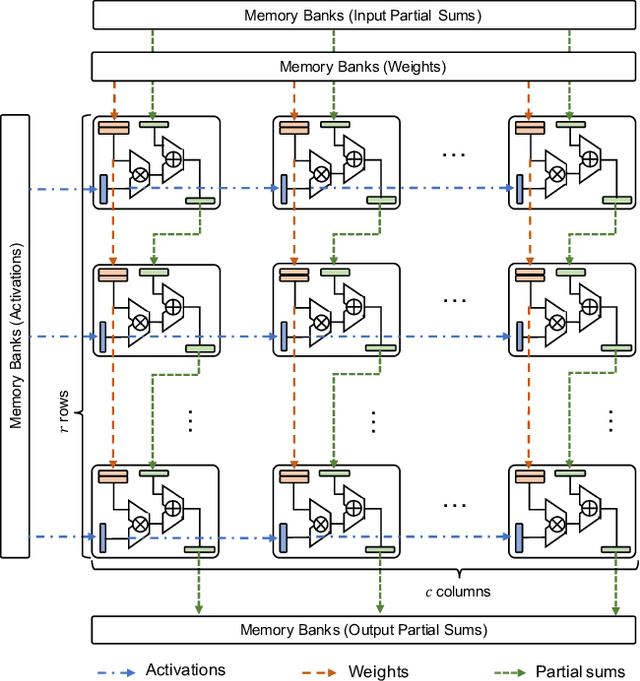
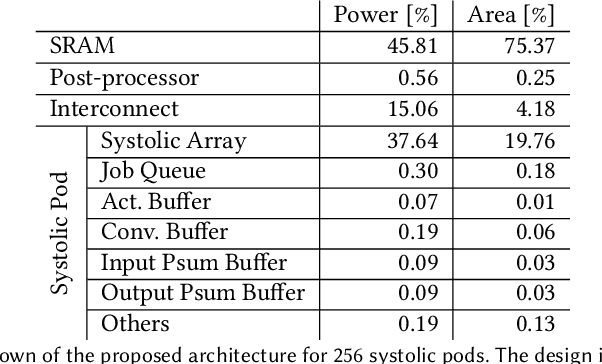
Multi-pod systolic arrays are emerging as the architecture of choice in DNN inference accelerators. Despite their potential, designing multi-pod systolic arrays to maximize effective throughput/Watt (i.e., throughput/Watt adjusted when accounting for array utilization) poses a unique set of challenges. In this work, we study three key pillars in multi-pod systolic array designs, namely array granularity, interconnect, and tiling. We identify optimal array granularity across workloads and show that state-of-the-art commercial accelerators use suboptimal array sizes for single-tenancy workloads. We, then evaluate the bandwidth/latency trade-offs in interconnects and show that Butterfly networks offer a scalable topology for accelerators with a large number of pods. Finally, we introduce a novel data tiling scheme with custom partition size to maximize utilization in optimally sized pods. We propose Scale-out Systolic Arrays, a multi-pod inference accelerator for both single- and multi-tenancy based on these three pillars. We show that SOSA exhibits scaling of up to 600 TeraOps/s in effective throughput for state-of-the-art DNN inference workloads, and outperforms state-of-the-art multi-pod accelerators by a factor of 1.5x.
Training DNNs with Hybrid Block Floating Point
May 28, 2018

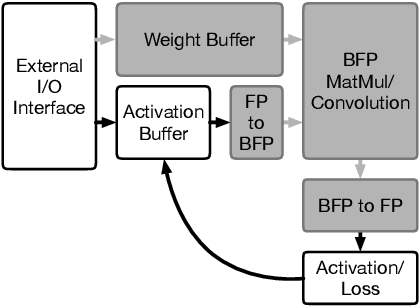

The wide adoption of DNNs has given birth to unrelenting computing requirements, forcing datacenter operators to adopt domain-specific accelerators to train them. These accelerators typically employ densely packed full precision floating-point arithmetic to maximize performance per area. Ongoing research efforts seek to further increase that performance density by replacing floating-point with fixed-point arithmetic. However, a significant roadblock for these attempts has been fixed point's narrow dynamic range, which is insufficient for DNN training convergence. We identify block floating point~(BFP) as a promising alternative representation since it exhibits wide dynamic range and enables the majority of DNN operations to be performed with fixed-point logic. Unfortunately, BFP alone introduces several limitations that preclude its direct applicability. In this work, we introduce HBFP, a hybrid BFP-FP approach, which performs all dot products in BFP and other operations in floating point. HBFP delivers the best of both worlds: the high accuracy of floating point at the superior hardware density of fixed point. For a wide variety of models, we show that HBFP matches floating point's accuracy while enabling hardware implementations that deliver up to 8.5x higher throughput.