 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccuracy Boosters: Epoch-Driven Mixed-Mantissa Block Floating-Point for DNN Training
Nov 22, 2022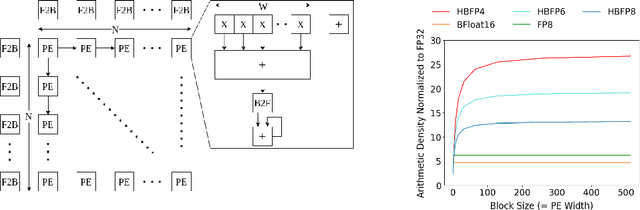
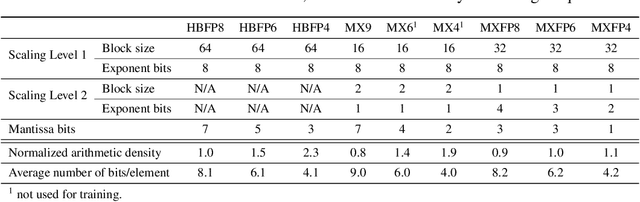
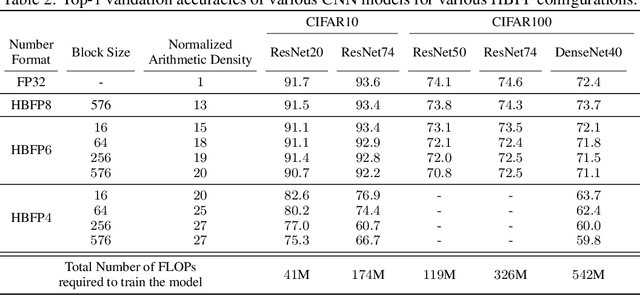
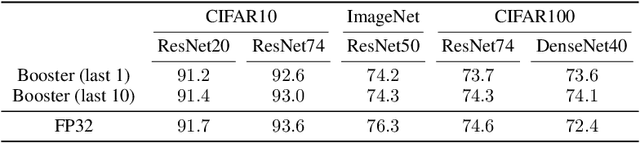
The unprecedented growth in DNN model complexity, size and the amount of training data have led to a commensurate increase in demand for computing and a search for minimal encoding. Recent research advocates Hybrid Block Floating-Point (HBFP) as a technique that minimizes silicon provisioning in accelerators by converting the majority of arithmetic operations in training to 8-bit fixed-point. In this paper, we perform a full-scale exploration of the HBFP design space including minimal mantissa encoding, varying block sizes, and mixed mantissa bit-width across layers and epochs. We propose Accuracy Boosters, an epoch-driven mixed-mantissa HBFP that uses 6-bit mantissa only in the last epoch and converts $99.7\%$ of all arithmetic operations in training to 4-bit mantissas. Accuracy Boosters enable reducing silicon provisioning for an HBFP training accelerator by $16.98\times$ as compared to FP32, while preserving or outperforming FP32 accuracy.
Scale-out Systolic Arrays
Mar 22, 2022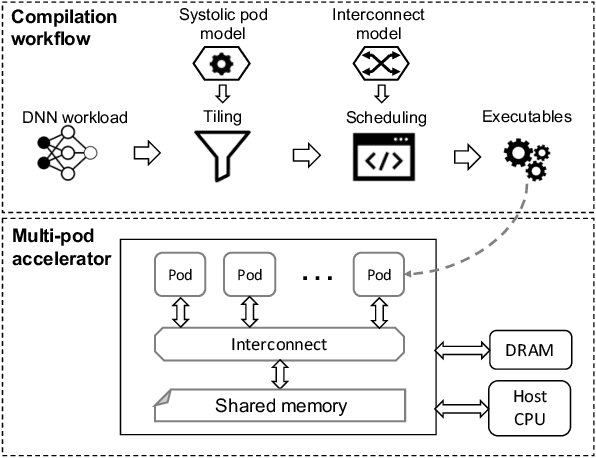
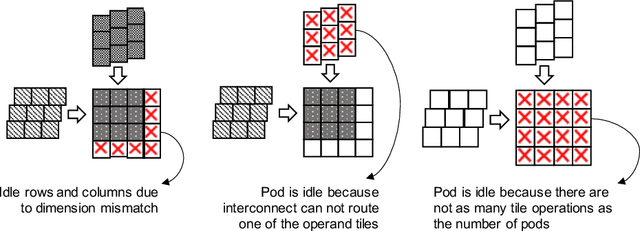
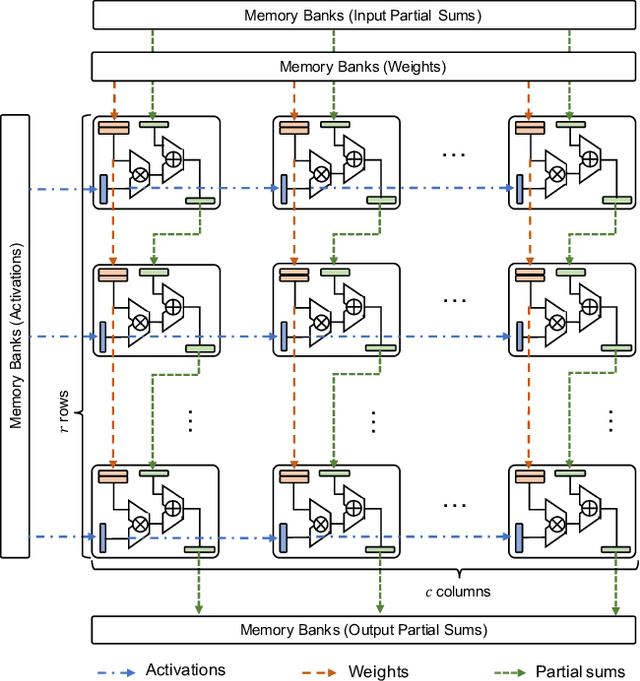
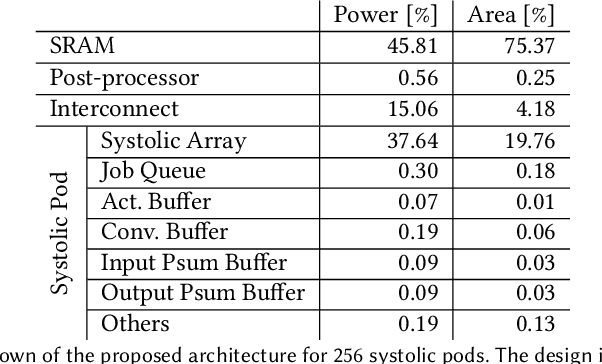
Multi-pod systolic arrays are emerging as the architecture of choice in DNN inference accelerators. Despite their potential, designing multi-pod systolic arrays to maximize effective throughput/Watt (i.e., throughput/Watt adjusted when accounting for array utilization) poses a unique set of challenges. In this work, we study three key pillars in multi-pod systolic array designs, namely array granularity, interconnect, and tiling. We identify optimal array granularity across workloads and show that state-of-the-art commercial accelerators use suboptimal array sizes for single-tenancy workloads. We, then evaluate the bandwidth/latency trade-offs in interconnects and show that Butterfly networks offer a scalable topology for accelerators with a large number of pods. Finally, we introduce a novel data tiling scheme with custom partition size to maximize utilization in optimally sized pods. We propose Scale-out Systolic Arrays, a multi-pod inference accelerator for both single- and multi-tenancy based on these three pillars. We show that SOSA exhibits scaling of up to 600 TeraOps/s in effective throughput for state-of-the-art DNN inference workloads, and outperforms state-of-the-art multi-pod accelerators by a factor of 1.5x.