 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDon't be so Stief! Learning KV Cache low-rank approximation over the Stiefel manifold
Jan 29, 2026Key--value (KV) caching enables fast autoregressive decoding but at long contexts becomes a dominant bottleneck in High Bandwidth Memory (HBM) capacity and bandwidth. A common mitigation is to compress cached keys and values by projecting per-head matrixes to a lower rank, storing only the projections in the HBM. However, existing post-training approaches typically fit these projections using SVD-style proxy objectives, which may poorly reflect end-to-end reconstruction after softmax, value mixing, and subsequent decoder-layer transformations. For these reasons, we introduce StiefAttention, a post-training KV-cache compression method that learns \emph{orthonormal} projection bases by directly minimizing \emph{decoder-layer output reconstruction error}. StiefAttention additionally precomputes, for each layer, an error-rank profile over candidate ranks, enabling flexible layer-wise rank allocation under a user-specified error budget. Noteworthy, on Llama3-8B under the same conditions, StiefAttention outperforms EigenAttention by $11.9$ points on C4 perplexity and $5.4\%$ on 0-shot MMLU accuracy at iso-compression, yielding lower relative error and higher cosine similarity with respect to the original decoder-layer outputs.
PRESERVE: Prefetching Model Weights and KV-Cache in Distributed LLM Serving
Jan 14, 2025



Large language models (LLMs) are widely used across various applications, but their substantial computational requirements pose significant challenges, particularly in terms of HBM bandwidth bottlenecks and inter-device communication overhead. In this paper, we present PRESERVE, a novel prefetching framework designed to optimize LLM inference by overlapping memory reads for model weights and KV-cache with collective communication operations. Through extensive experiments conducted on commercial AI accelerators, we demonstrate up to 1.6x end-to-end speedup on state-of-the-art, open-source LLMs. Additionally, we perform a design space exploration that identifies the optimal hardware configuration for the proposed method, showing a further 1.25x improvement in performance per cost by selecting the optimal L2 cache size. Our results show that PRESERVE has the potential to mitigate the memory bottlenecks and communication overheads, offering a solution to improve the performance and scalability of the LLM inference systems.
Flexible Channel Dimensions for Differentiable Architecture Search
Jun 13, 2023Finding optimal channel dimensions (i.e., the number of filters in DNN layers) is essential to design DNNs that perform well under computational resource constraints. Recent work in neural architecture search aims at automating the optimization of the DNN model implementation. However, existing neural architecture search methods for channel dimensions rely on fixed search spaces, which prevents achieving an efficient and fully automated solution. In this work, we propose a novel differentiable neural architecture search method with an efficient dynamic channel allocation algorithm to enable a flexible search space for channel dimensions. We show that the proposed framework is able to find DNN architectures that are equivalent to previous methods in task accuracy and inference latency for the CIFAR-10 dataset with an improvement of $1.3-1.7\times$ in GPU-hours and $1.5-1.7\times$ in the memory requirements during the architecture search stage. Moreover, the proposed frameworks do not require a well-engineered search space a priori, which is an important step towards fully automated design of DNN architectures.
Hierarchical Training of Deep Neural Networks Using Early Exiting
Mar 19, 2023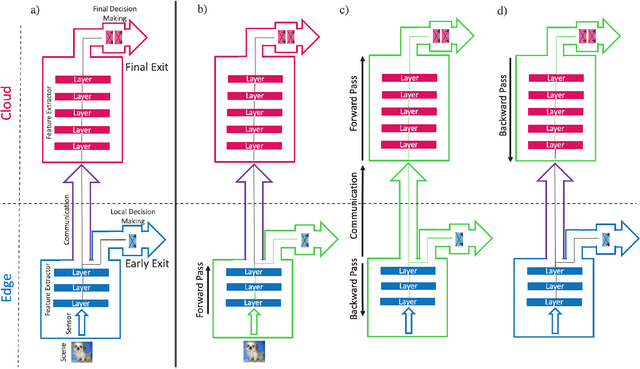
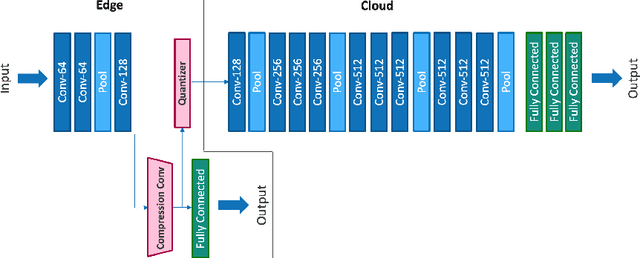
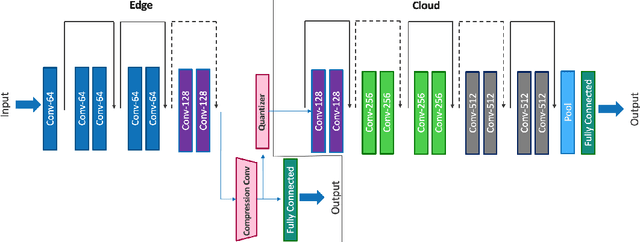
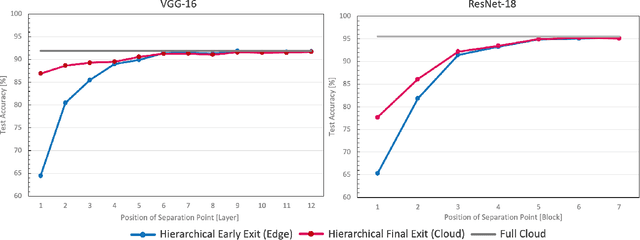
Deep neural networks provide state-of-the-art accuracy for vision tasks but they require significant resources for training. Thus, they are trained on cloud servers far from the edge devices that acquire the data. This issue increases communication cost, runtime and privacy concerns. In this study, a novel hierarchical training method for deep neural networks is proposed that uses early exits in a divided architecture between edge and cloud workers to reduce the communication cost, training runtime and privacy concerns. The method proposes a brand-new use case for early exits to separate the backward pass of neural networks between the edge and the cloud during the training phase. We address the issues of most available methods that due to the sequential nature of the training phase, cannot train the levels of hierarchy simultaneously or they do it with the cost of compromising privacy. In contrast, our method can use both edge and cloud workers simultaneously, does not share the raw input data with the cloud and does not require communication during the backward pass. Several simulations and on-device experiments for different neural network architectures demonstrate the effectiveness of this method. It is shown that the proposed method reduces the training runtime by 29% and 61% in CIFAR-10 classification experiment for VGG-16 and ResNet-18 when the communication with the cloud is done at a low bit rate channel. This gain in the runtime is achieved whilst the accuracy drop is negligible. This method is advantageous for online learning of high-accuracy deep neural networks on low-resource devices such as mobile phones or robots as a part of an edge-cloud system, making them more flexible in facing new tasks and classes of data.
U-Boost NAS: Utilization-Boosted Differentiable Neural Architecture Search
Mar 23, 2022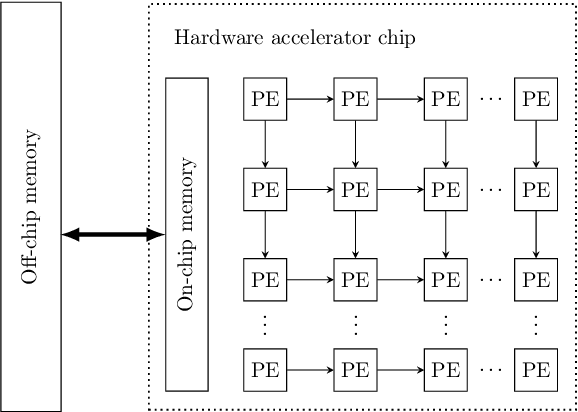

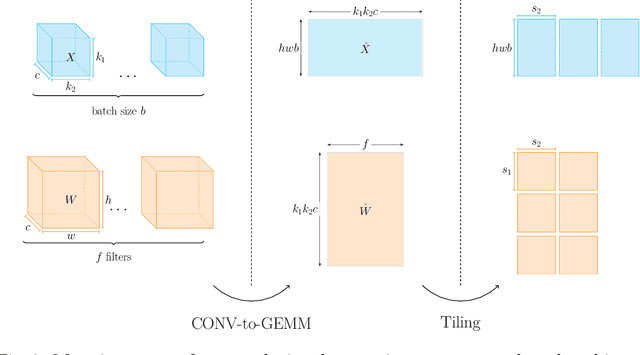
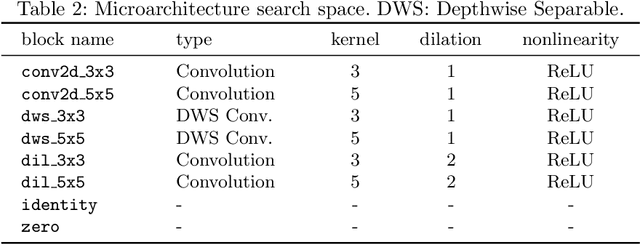
Optimizing resource utilization in target platforms is key to achieving high performance during DNN inference. While optimizations have been proposed for inference latency, memory footprint, and energy consumption, prior hardware-aware neural architecture search (NAS) methods have omitted resource utilization, preventing DNNs to take full advantage of the target inference platforms. Modeling resource utilization efficiently and accurately is challenging, especially for widely-used array-based inference accelerators such as Google TPU. In this work, we propose a novel hardware-aware NAS framework that does not only optimize for task accuracy and inference latency, but also for resource utilization. We also propose and validate a new computational model for resource utilization in inference accelerators. By using the proposed NAS framework and the proposed resource utilization model, we achieve 2.8 - 4x speedup for DNN inference compared to prior hardware-aware NAS methods while attaining similar or improved accuracy in image classification on CIFAR-10 and Imagenet-100 datasets.
Scale-out Systolic Arrays
Mar 22, 2022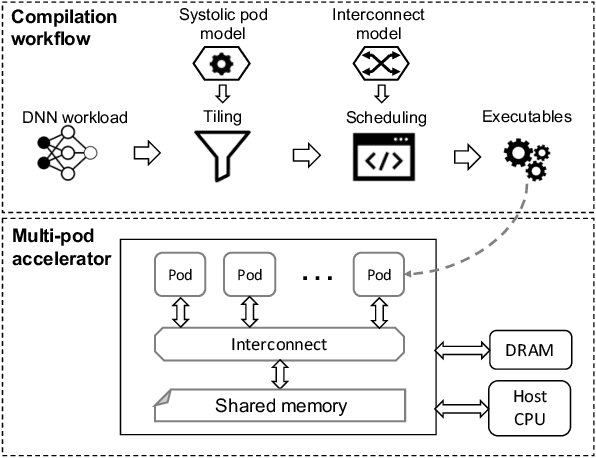
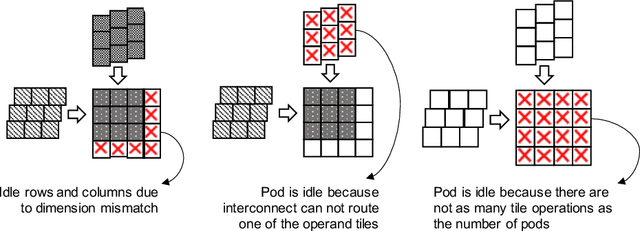
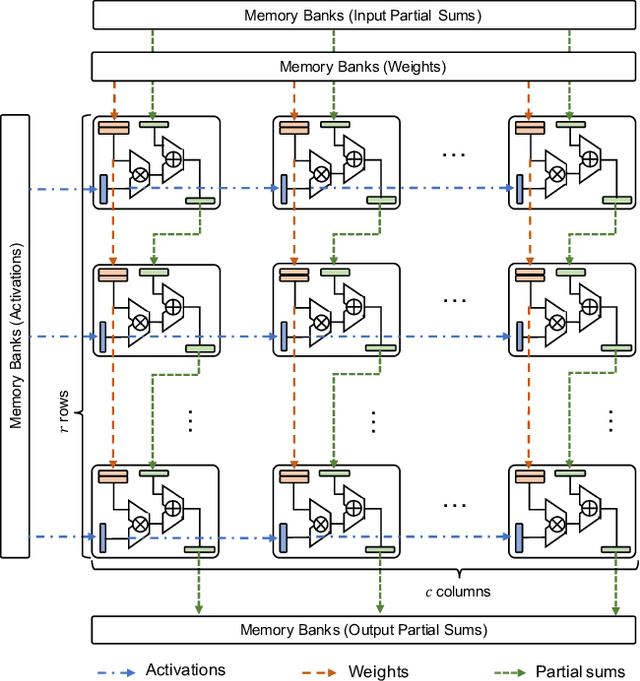
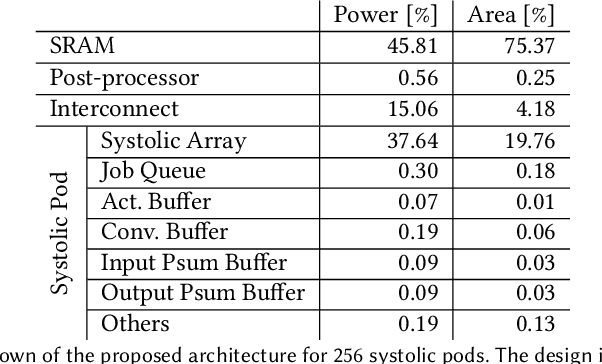
Multi-pod systolic arrays are emerging as the architecture of choice in DNN inference accelerators. Despite their potential, designing multi-pod systolic arrays to maximize effective throughput/Watt (i.e., throughput/Watt adjusted when accounting for array utilization) poses a unique set of challenges. In this work, we study three key pillars in multi-pod systolic array designs, namely array granularity, interconnect, and tiling. We identify optimal array granularity across workloads and show that state-of-the-art commercial accelerators use suboptimal array sizes for single-tenancy workloads. We, then evaluate the bandwidth/latency trade-offs in interconnects and show that Butterfly networks offer a scalable topology for accelerators with a large number of pods. Finally, we introduce a novel data tiling scheme with custom partition size to maximize utilization in optimally sized pods. We propose Scale-out Systolic Arrays, a multi-pod inference accelerator for both single- and multi-tenancy based on these three pillars. We show that SOSA exhibits scaling of up to 600 TeraOps/s in effective throughput for state-of-the-art DNN inference workloads, and outperforms state-of-the-art multi-pod accelerators by a factor of 1.5x.