 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAND: One-Shot Feature Selection with Additive Noise Distortion
May 06, 2025Feature selection is a critical step in data-driven applications, reducing input dimensionality to enhance learning accuracy, computational efficiency, and interpretability. Existing state-of-the-art methods often require post-selection retraining and extensive hyperparameter tuning, complicating their adoption. We introduce a novel, non-intrusive feature selection layer that, given a target feature count $k$, automatically identifies and selects the $k$ most informative features during neural network training. Our method is uniquely simple, requiring no alterations to the loss function, network architecture, or post-selection retraining. The layer is mathematically elegant and can be fully described by: \begin{align} \nonumber \tilde{x}_i = a_i x_i + (1-a_i)z_i \end{align} where $x_i$ is the input feature, $\tilde{x}_i$ the output, $z_i$ a Gaussian noise, and $a_i$ trainable gain such that $\sum_i{a_i^2}=k$. This formulation induces an automatic clustering effect, driving $k$ of the $a_i$ gains to $1$ (selecting informative features) and the rest to $0$ (discarding redundant ones) via weighted noise distortion and gain normalization. Despite its extreme simplicity, our method delivers state-of-the-art performance on standard benchmark datasets and a novel real-world dataset, outperforming or matching existing approaches without requiring hyperparameter search for $k$ or retraining. Theoretical analysis in the context of linear regression further validates its efficacy. Our work demonstrates that simplicity and performance are not mutually exclusive, offering a powerful yet straightforward tool for feature selection in machine learning.
PriPHiT: Privacy-Preserving Hierarchical Training of Deep Neural Networks
Aug 09, 2024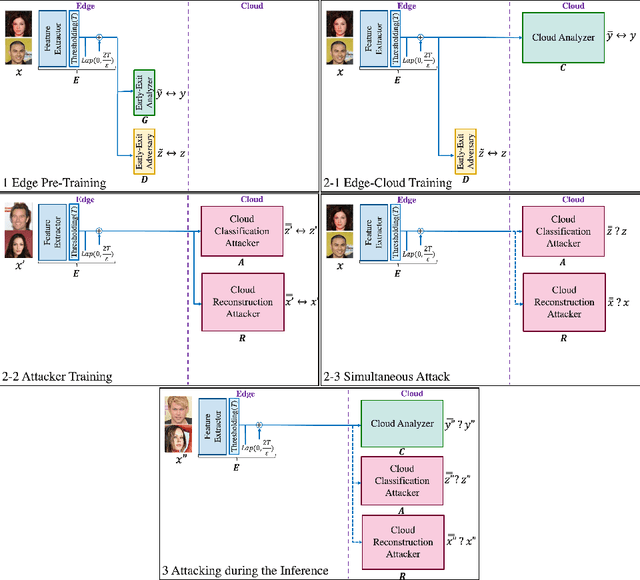
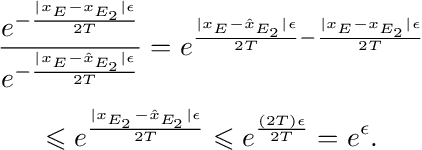
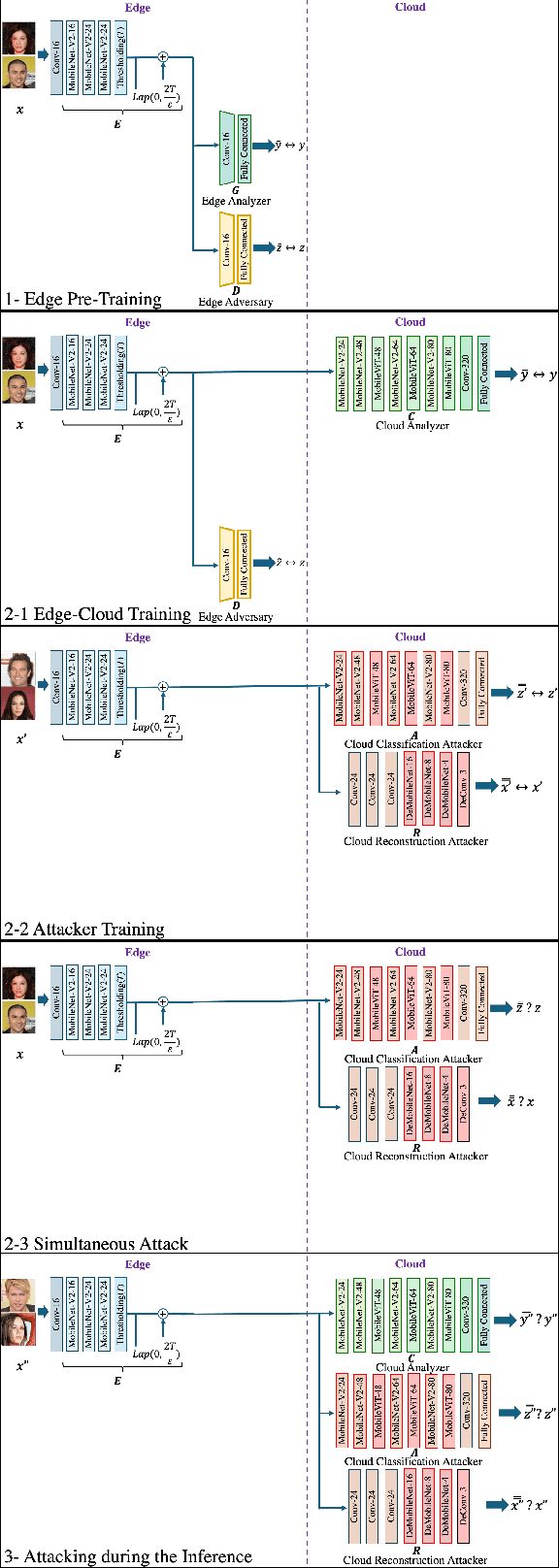
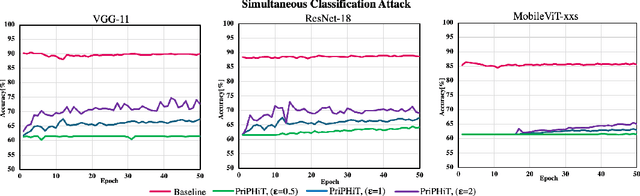
The training phase of deep neural networks requires substantial resources and as such is often performed on cloud servers. However, this raises privacy concerns when the training dataset contains sensitive content, e.g., face images. In this work, we propose a method to perform the training phase of a deep learning model on both an edge device and a cloud server that prevents sensitive content being transmitted to the cloud while retaining the desired information. The proposed privacy-preserving method uses adversarial early exits to suppress the sensitive content at the edge and transmits the task-relevant information to the cloud. This approach incorporates noise addition during the training phase to provide a differential privacy guarantee. We extensively test our method on different facial datasets with diverse face attributes using various deep learning architectures, showcasing its outstanding performance. We also demonstrate the effectiveness of privacy preservation through successful defenses against different white-box and deep reconstruction attacks.
Hierarchical Training of Deep Neural Networks Using Early Exiting
Mar 19, 2023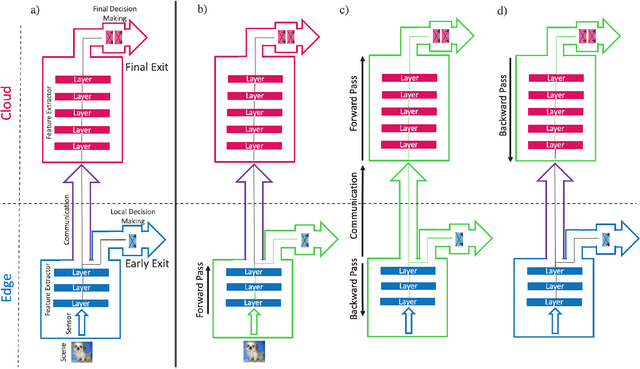
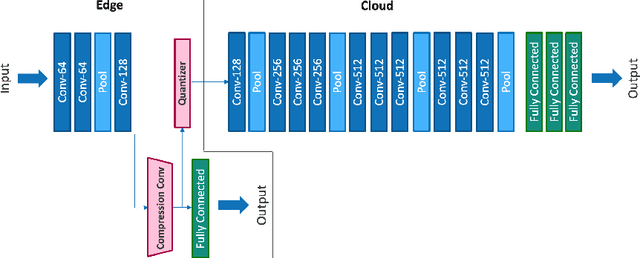
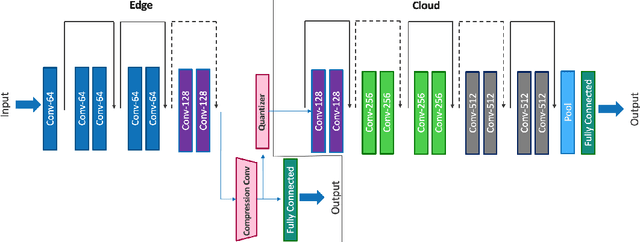
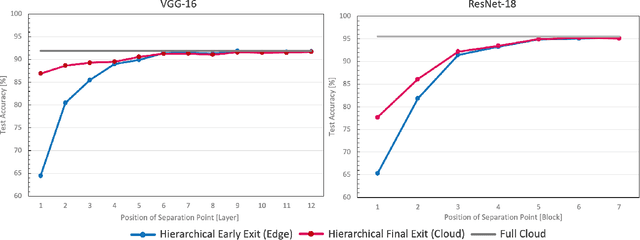
Deep neural networks provide state-of-the-art accuracy for vision tasks but they require significant resources for training. Thus, they are trained on cloud servers far from the edge devices that acquire the data. This issue increases communication cost, runtime and privacy concerns. In this study, a novel hierarchical training method for deep neural networks is proposed that uses early exits in a divided architecture between edge and cloud workers to reduce the communication cost, training runtime and privacy concerns. The method proposes a brand-new use case for early exits to separate the backward pass of neural networks between the edge and the cloud during the training phase. We address the issues of most available methods that due to the sequential nature of the training phase, cannot train the levels of hierarchy simultaneously or they do it with the cost of compromising privacy. In contrast, our method can use both edge and cloud workers simultaneously, does not share the raw input data with the cloud and does not require communication during the backward pass. Several simulations and on-device experiments for different neural network architectures demonstrate the effectiveness of this method. It is shown that the proposed method reduces the training runtime by 29% and 61% in CIFAR-10 classification experiment for VGG-16 and ResNet-18 when the communication with the cloud is done at a low bit rate channel. This gain in the runtime is achieved whilst the accuracy drop is negligible. This method is advantageous for online learning of high-accuracy deep neural networks on low-resource devices such as mobile phones or robots as a part of an edge-cloud system, making them more flexible in facing new tasks and classes of data.
Privacy-Preserving Image Acquisition Using Trainable Optical Kernel
Jun 28, 2021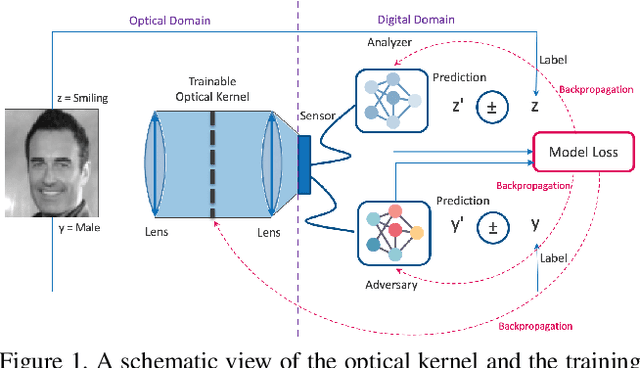
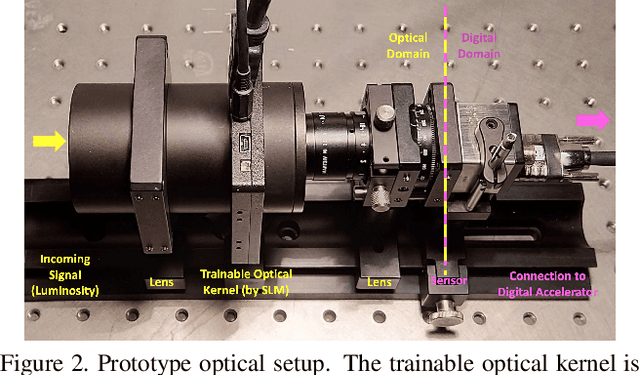
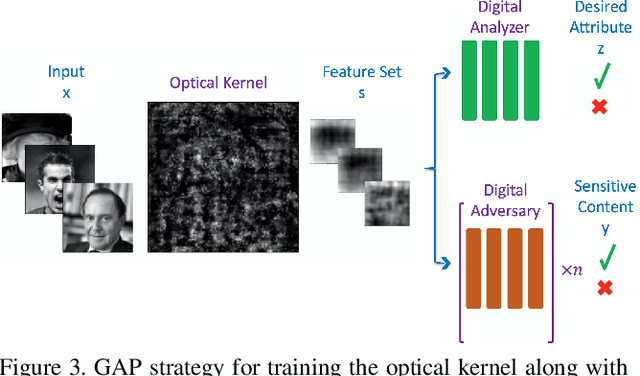

Preserving privacy is a growing concern in our society where sensors and cameras are ubiquitous. In this work, for the first time, we propose a trainable image acquisition method that removes the sensitive identity revealing information in the optical domain before it reaches the image sensor. The method benefits from a trainable optical convolution kernel which transmits the desired information while filters out the sensitive content. As the sensitive content is suppressed before it reaches the image sensor, it does not enter the digital domain therefore is unretrievable by any sort of privacy attack. This is in contrast with the current digital privacy-preserving methods that are all vulnerable to direct access attack. Also, in contrast with the previous optical privacy-preserving methods that cannot be trained, our method is data-driven and optimized for the specific application at hand. Moreover, there is no additional computation, memory, or power burden on the acquisition system since this processing happens passively in the optical domain and can even be used together and on top of the fully digital privacy-preserving systems. The proposed approach is adaptable to different digital neural networks and content. We demonstrate it for several scenarios such as smile detection as the desired attribute while the gender is filtered out as the sensitive content. We trained the optical kernel in conjunction with two adversarial neural networks where the analysis network tries to detect the desired attribute and the adversarial network tries to detect the sensitive content. We show that this method can reduce 65.1% of sensitive content when it is selected to be the gender and it only loses 7.3% of the desired content. Moreover, we reconstruct the original faces using the deep reconstruction method that confirms the ineffectiveness of reconstruction attacks to obtain the sensitive content.