 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccuracy Boosters: Epoch-Driven Mixed-Mantissa Block Floating-Point for DNN Training
Paper and Code
Nov 22, 2022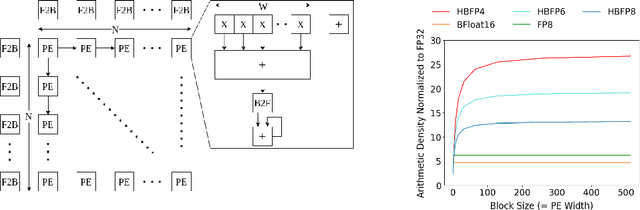
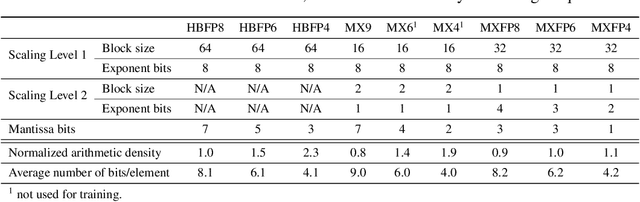
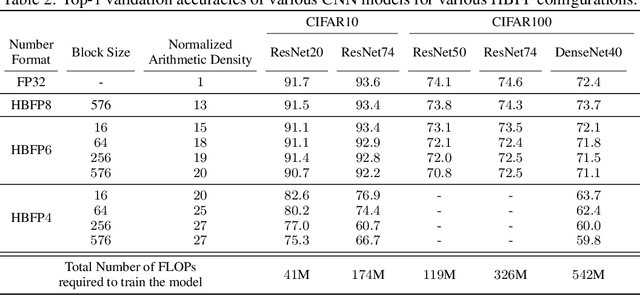
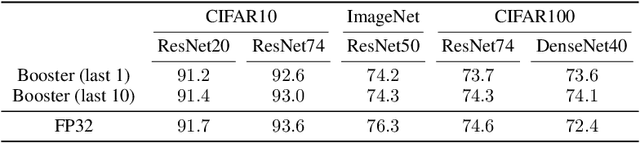
The unprecedented growth in DNN model complexity, size and the amount of training data have led to a commensurate increase in demand for computing and a search for minimal encoding. Recent research advocates Hybrid Block Floating-Point (HBFP) as a technique that minimizes silicon provisioning in accelerators by converting the majority of arithmetic operations in training to 8-bit fixed-point. In this paper, we perform a full-scale exploration of the HBFP design space including minimal mantissa encoding, varying block sizes, and mixed mantissa bit-width across layers and epochs. We propose Accuracy Boosters, an epoch-driven mixed-mantissa HBFP that uses 6-bit mantissa only in the last epoch and converts $99.7\%$ of all arithmetic operations in training to 4-bit mantissas. Accuracy Boosters enable reducing silicon provisioning for an HBFP training accelerator by $16.98\times$ as compared to FP32, while preserving or outperforming FP32 accuracy.