 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpark Transformer: Reactivating Sparsity in FFN and Attention
Jun 07, 2025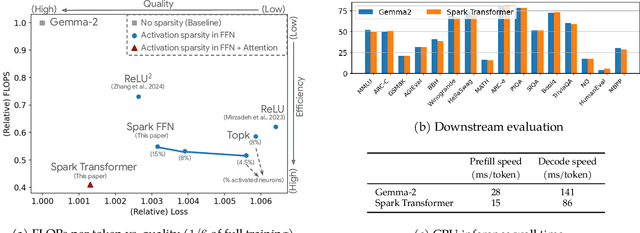
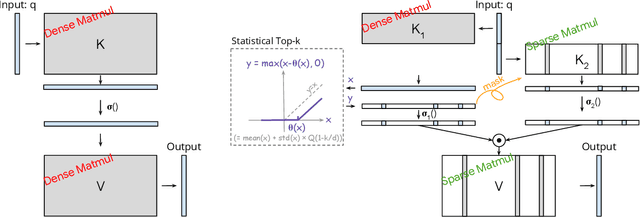
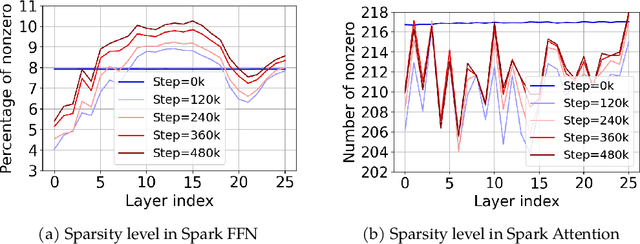
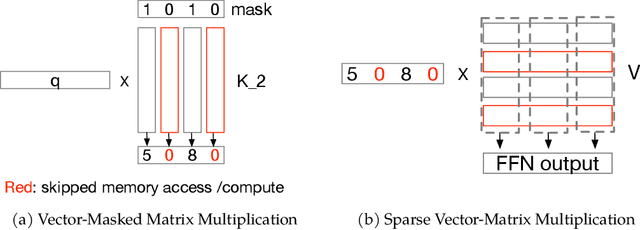
The discovery of the lazy neuron phenomenon in trained Transformers, where the vast majority of neurons in their feed-forward networks (FFN) are inactive for each token, has spurred tremendous interests in activation sparsity for enhancing large model efficiency. While notable progress has been made in translating such sparsity to wall-time benefits, modern Transformers have moved away from the ReLU activation function crucial to this phenomenon. Existing efforts on re-introducing activation sparsity often degrade model quality, increase parameter count, complicate or slow down training. Sparse attention, the application of sparse activation to the attention mechanism, often faces similar challenges. This paper introduces the Spark Transformer, a novel architecture that achieves a high level of activation sparsity in both FFN and the attention mechanism while maintaining model quality, parameter count, and standard training procedures. Our method realizes sparsity via top-k masking for explicit control over sparsity level. Crucially, we introduce statistical top-k, a hardware-accelerator-friendly, linear-time approximate algorithm that avoids costly sorting and mitigates significant training slowdown from standard top-$k$ operators. Furthermore, Spark Transformer reallocates existing FFN parameters and attention key embeddings to form a low-cost predictor for identifying activated entries. This design not only mitigates quality loss from enforced sparsity, but also enhances wall-time benefit. Pretrained with the Gemma-2 recipe, Spark Transformer demonstrates competitive performance on standard benchmarks while exhibiting significant sparsity: only 8% of FFN neurons are activated, and each token attends to a maximum of 256 tokens. This sparsity translates to a 2.5x reduction in FLOPs, leading to decoding wall-time speedups of up to 1.79x on CPU and 1.40x on GPU.
Understanding and Optimizing Multi-Stage AI Inference Pipelines
Apr 16, 2025The rapid evolution of Large Language Models (LLMs) has driven the need for increasingly sophisticated inference pipelines and hardware platforms. Modern LLM serving extends beyond traditional prefill-decode workflows, incorporating multi-stage processes such as Retrieval Augmented Generation (RAG), key-value (KV) cache retrieval, dynamic model routing, and multi step reasoning. These stages exhibit diverse computational demands, requiring distributed systems that integrate GPUs, ASICs, CPUs, and memory-centric architectures. However, existing simulators lack the fidelity to model these heterogeneous, multi-engine workflows, limiting their ability to inform architectural decisions. To address this gap, we introduce HERMES, a Heterogeneous Multi-stage LLM inference Execution Simulator. HERMES models diverse request stages; including RAG, KV retrieval, reasoning, prefill, and decode across complex hardware hierarchies. HERMES supports heterogeneous clients executing multiple models concurrently unlike prior frameworks while incorporating advanced batching strategies and multi-level memory hierarchies. By integrating real hardware traces with analytical modeling, HERMES captures critical trade-offs such as memory bandwidth contention, inter-cluster communication latency, and batching efficiency in hybrid CPU-accelerator deployments. Through case studies, we explore the impact of reasoning stages on end-to-end latency, optimal batching strategies for hybrid pipelines, and the architectural implications of remote KV cache retrieval. HERMES empowers system designers to navigate the evolving landscape of LLM inference, providing actionable insights into optimizing hardware-software co-design for next-generation AI workloads.
RAGO: Systematic Performance Optimization for Retrieval-Augmented Generation Serving
Mar 21, 2025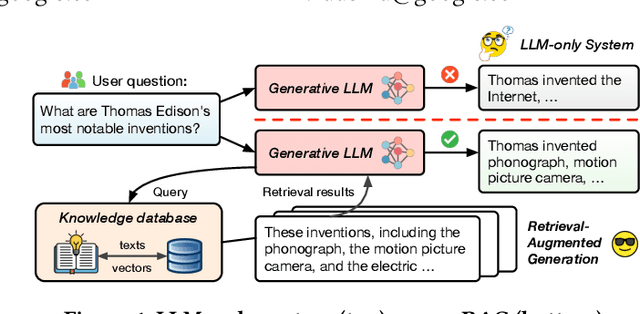



Retrieval-augmented generation (RAG), which combines large language models (LLMs) with retrievals from external knowledge databases, is emerging as a popular approach for reliable LLM serving. However, efficient RAG serving remains an open challenge due to the rapid emergence of many RAG variants and the substantial differences in workload characteristics across them. In this paper, we make three fundamental contributions to advancing RAG serving. First, we introduce RAGSchema, a structured abstraction that captures the wide range of RAG algorithms, serving as a foundation for performance optimization. Second, we analyze several representative RAG workloads with distinct RAGSchema, revealing significant performance variability across these workloads. Third, to address this variability and meet diverse performance requirements, we propose RAGO (Retrieval-Augmented Generation Optimizer), a system optimization framework for efficient RAG serving. Our evaluation shows that RAGO achieves up to a 2x increase in QPS per chip and a 55% reduction in time-to-first-token latency compared to RAG systems built on LLM-system extensions.
Learning to Keep a Promise: Scaling Language Model Decoding Parallelism with Learned Asynchronous Decoding
Feb 17, 2025

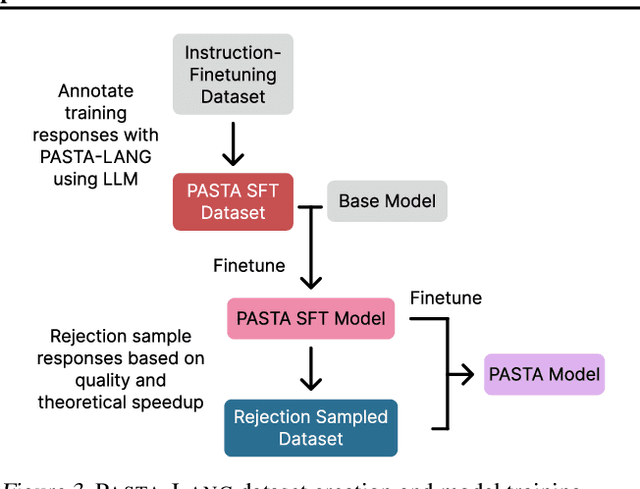
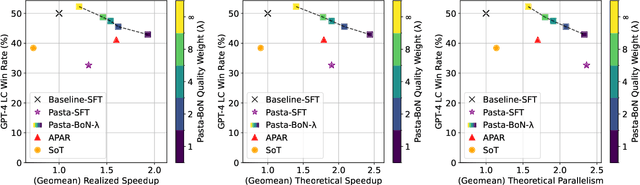
Decoding with autoregressive large language models (LLMs) traditionally occurs sequentially, generating one token after another. An emerging line of work explored parallel decoding by identifying and simultaneously generating semantically independent chunks of LLM responses. However, these techniques rely on hand-crafted heuristics tied to syntactic structures like lists and paragraphs, making them rigid and imprecise. We present PASTA, a learning-based system that teaches LLMs to identify semantic independence and express parallel decoding opportunities in their own responses. At its core are PASTA-LANG and its interpreter: PASTA-LANG is an annotation language that enables LLMs to express semantic independence in their own responses; the language interpreter acts on these annotations to orchestrate parallel decoding on-the-fly at inference time. Through a two-stage finetuning process, we train LLMs to generate PASTA-LANG annotations that optimize both response quality and decoding speed. Evaluation on AlpacaEval, an instruction following benchmark, shows that our approach Pareto-dominates existing methods in terms of decoding speed and response quality; our results demonstrate geometric mean speedups ranging from 1.21x to 1.93x with corresponding quality changes of +2.2% to -7.1%, measured by length-controlled win rates against sequential decoding baseline.
Effective Interplay between Sparsity and Quantization: From Theory to Practice
May 31, 2024



The increasing size of deep neural networks necessitates effective model compression to improve computational efficiency and reduce their memory footprint. Sparsity and quantization are two prominent compression methods that have individually demonstrated significant reduction in computational and memory footprints while preserving model accuracy. While effective, the interplay between these two methods remains an open question. In this paper, we investigate the interaction between these two methods and assess whether their combination impacts final model accuracy. We mathematically prove that applying sparsity before quantization is the optimal sequence for these operations, minimizing error in computation. Our empirical studies across a wide range of models, including OPT and Llama model families (125M-8B) and ViT corroborate these theoretical findings. In addition, through rigorous analysis, we demonstrate that sparsity and quantization are not orthogonal; their interaction can significantly harm model accuracy, with quantization error playing a dominant role in this degradation. Our findings extend to the efficient deployment of large models in resource-limited compute platforms and reduce serving cost, offering insights into best practices for applying these compression methods to maximize efficacy without compromising accuracy.
Progressive Gradient Flow for Robust N:M Sparsity Training in Transformers
Feb 07, 2024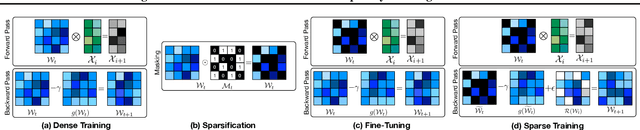


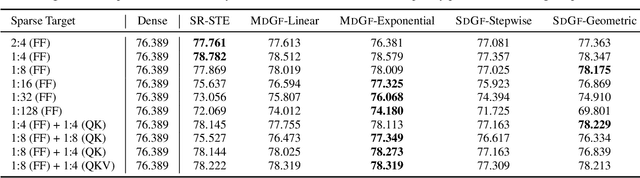
N:M Structured sparsity has garnered significant interest as a result of relatively modest overhead and improved efficiency. Additionally, this form of sparsity holds considerable appeal for reducing the memory footprint owing to their modest representation overhead. There have been efforts to develop training recipes for N:M structured sparsity, they primarily focus on low-sparsity regions ($\sim$50\%). Nonetheless, performance of models trained using these approaches tends to decline when confronted with high-sparsity regions ($>$80\%). In this work, we study the effectiveness of existing sparse training recipes at \textit{high-sparsity regions} and argue that these methods fail to sustain the model quality on par with low-sparsity regions. We demonstrate that the significant factor contributing to this disparity is the presence of elevated levels of induced noise in the gradient magnitudes. To mitigate this undesirable effect, we employ decay mechanisms to progressively restrict the flow of gradients towards pruned elements. Our approach improves the model quality by up to 2$\%$ and 5$\%$ in vision and language models at high sparsity regime, respectively. We also evaluate the trade-off between model accuracy and training compute cost in terms of FLOPs. At iso-training FLOPs, our method yields better performance compared to conventional sparse training recipes, exhibiting an accuracy improvement of up to 2$\%$. The source code is available at https://github.com/abhibambhaniya/progressive_gradient_flow_nm_sparsity.
JaxPruner: A concise library for sparsity research
May 02, 2023


This paper introduces JaxPruner, an open-source JAX-based pruning and sparse training library for machine learning research. JaxPruner aims to accelerate research on sparse neural networks by providing concise implementations of popular pruning and sparse training algorithms with minimal memory and latency overhead. Algorithms implemented in JaxPruner use a common API and work seamlessly with the popular optimization library Optax, which, in turn, enables easy integration with existing JAX based libraries. We demonstrate this ease of integration by providing examples in four different codebases: Scenic, t5x, Dopamine and FedJAX and provide baseline experiments on popular benchmarks.
TPU v4: An Optically Reconfigurable Supercomputer for Machine Learning with Hardware Support for Embeddings
Apr 20, 2023In response to innovations in machine learning (ML) models, production workloads changed radically and rapidly. TPU v4 is the fifth Google domain specific architecture (DSA) and its third supercomputer for such ML models. Optical circuit switches (OCSes) dynamically reconfigure its interconnect topology to improve scale, availability, utilization, modularity, deployment, security, power, and performance; users can pick a twisted 3D torus topology if desired. Much cheaper, lower power, and faster than Infiniband, OCSes and underlying optical components are <5% of system cost and <3% of system power. Each TPU v4 includes SparseCores, dataflow processors that accelerate models that rely on embeddings by 5x-7x yet use only 5% of die area and power. Deployed since 2020, TPU v4 outperforms TPU v3 by 2.1x and improves performance/Watt by 2.7x. The TPU v4 supercomputer is 4x larger at 4096 chips and thus ~10x faster overall, which along with OCS flexibility helps large language models. For similar sized systems, it is ~4.3x-4.5x faster than the Graphcore IPU Bow and is 1.2x-1.7x faster and uses 1.3x-1.9x less power than the Nvidia A100. TPU v4s inside the energy-optimized warehouse scale computers of Google Cloud use ~3x less energy and produce ~20x less CO2e than contemporary DSAs in a typical on-premise data center.
STEP: Learning N:M Structured Sparsity Masks from Scratch with Precondition
Feb 02, 2023



Recent innovations on hardware (e.g. Nvidia A100) have motivated learning N:M structured sparsity masks from scratch for fast model inference. However, state-of-the-art learning recipes in this regime (e.g. SR-STE) are proposed for non-adaptive optimizers like momentum SGD, while incurring non-trivial accuracy drop for Adam-trained models like attention-based LLMs. In this paper, we first demonstrate such gap origins from poorly estimated second moment (i.e. variance) in Adam states given by the masked weights. We conjecture that learning N:M masks with Adam should take the critical regime of variance estimation into account. In light of this, we propose STEP, an Adam-aware recipe that learns N:M masks with two phases: first, STEP calculates a reliable variance estimate (precondition phase) and subsequently, the variance remains fixed and is used as a precondition to learn N:M masks (mask-learning phase). STEP automatically identifies the switching point of two phases by dynamically sampling variance changes over the training trajectory and testing the sample concentration. Empirically, we evaluate STEP and other baselines such as ASP and SR-STE on multiple tasks including CIFAR classification, machine translation and LLM fine-tuning (BERT-Base, GPT-2). We show STEP mitigates the accuracy drop of baseline recipes and is robust to aggressive structured sparsity ratios.
Training Recipe for N:M Structured Sparsity with Decaying Pruning Mask
Sep 15, 2022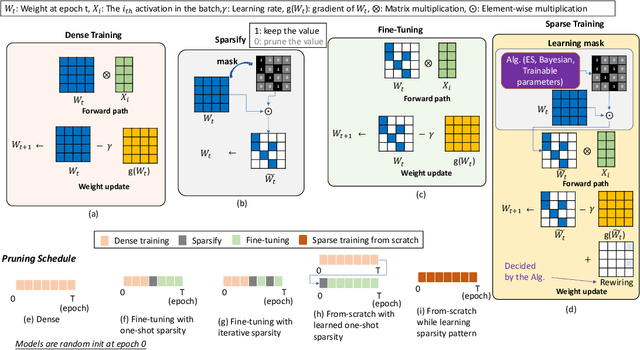

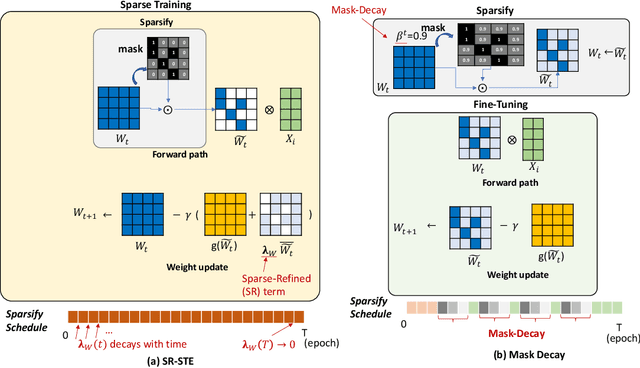

Sparsity has become one of the promising methods to compress and accelerate Deep Neural Networks (DNNs). Among different categories of sparsity, structured sparsity has gained more attention due to its efficient execution on modern accelerators. Particularly, N:M sparsity is attractive because there are already hardware accelerator architectures that can leverage certain forms of N:M structured sparsity to yield higher compute-efficiency. In this work, we focus on N:M sparsity and extensively study and evaluate various training recipes for N:M sparsity in terms of the trade-off between model accuracy and compute cost (FLOPs). Building upon this study, we propose two new decay-based pruning methods, namely "pruning mask decay" and "sparse structure decay". Our evaluations indicate that these proposed methods consistently deliver state-of-the-art (SOTA) model accuracy, comparable to unstructured sparsity, on a Transformer-based model for a translation task. The increase in the accuracy of the sparse model using the new training recipes comes at the cost of marginal increase in the total training compute (FLOPs).