 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
TPU v4: An Optically Reconfigurable Supercomputer for Machine Learning with Hardware Support for Embeddings
Apr 20, 2023In response to innovations in machine learning (ML) models, production workloads changed radically and rapidly. TPU v4 is the fifth Google domain specific architecture (DSA) and its third supercomputer for such ML models. Optical circuit switches (OCSes) dynamically reconfigure its interconnect topology to improve scale, availability, utilization, modularity, deployment, security, power, and performance; users can pick a twisted 3D torus topology if desired. Much cheaper, lower power, and faster than Infiniband, OCSes and underlying optical components are <5% of system cost and <3% of system power. Each TPU v4 includes SparseCores, dataflow processors that accelerate models that rely on embeddings by 5x-7x yet use only 5% of die area and power. Deployed since 2020, TPU v4 outperforms TPU v3 by 2.1x and improves performance/Watt by 2.7x. The TPU v4 supercomputer is 4x larger at 4096 chips and thus ~10x faster overall, which along with OCS flexibility helps large language models. For similar sized systems, it is ~4.3x-4.5x faster than the Graphcore IPU Bow and is 1.2x-1.7x faster and uses 1.3x-1.9x less power than the Nvidia A100. TPU v4s inside the energy-optimized warehouse scale computers of Google Cloud use ~3x less energy and produce ~20x less CO2e than contemporary DSAs in a typical on-premise data center.
Exploring the limits of Concurrency in ML Training on Google TPUs
Nov 07, 2020
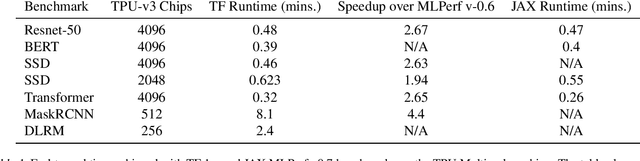
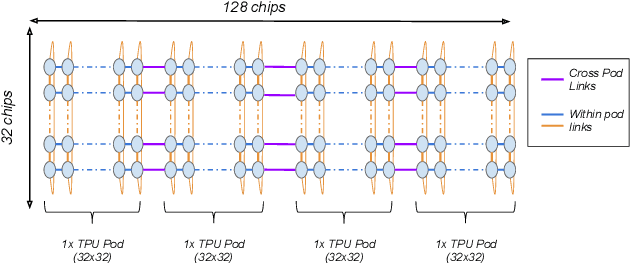
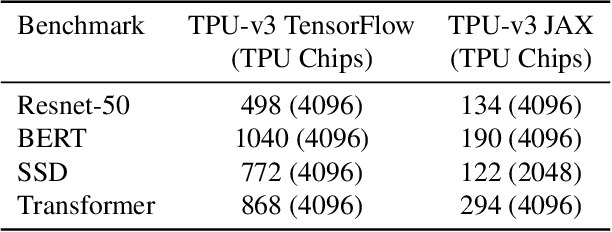
Recent results in language understanding using neural networks have required training hardware of unprecedentedscale, with thousands of chips cooperating on a single training run. This paper presents techniques to scaleML models on the Google TPU Multipod, a mesh with 4096 TPU-v3 chips. We discuss model parallelism toovercome scaling limitations from the fixed batch size in data parallelism, communication/collective optimizations,distributed evaluation of training metrics, and host input processing scaling optimizations. These techniques aredemonstrated in both the TensorFlow and JAX programming frameworks. We also present performance resultsfrom the recent Google submission to the MLPerf-v0.7 benchmark contest, achieving record training times from16 to 28 seconds in four MLPerf models on the Google TPU-v3 Multipod machine.