 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCosmos 3: Omnimodal World Models for Physical AI
Jun 01, 2026We introduce Cosmos 3, a family of omnimodal world models designed to jointly process and generate language, image, video, audio, and action sequences within a unified mixture-of-transformers architecture. By supporting highly flexible input-output configurations, Cosmos 3 seamlessly unifies critical modalities for Physical AI -- effectively subsuming vision-language models, video generators, world simulators, and world-action models into a single framework. Our evaluation demonstrates that Cosmos 3 establishes a new state-of-the-art across a diverse suite of understanding and generation tasks, demonstrating omnimodal world models as scalable, general-purpose backbones for embodied agents. Our post-trained Cosmos 3 models were ranked as the best open-source Text-to-Image and Image-to-Video models by Artificial Analysis, and the best policy model by RoboArena at the time the technical report was written. To accelerate open research and deployment in Physical AI, we make our code, model checkpoints, curated synthetic datasets, and evaluation benchmark available under the Linux Foundation's OpenMDW-1.1 https://openmdw.ai/license/1-1/ License at https://github.com/nvidia/cosmos}{github.com/nvidia/cosmos and https://huggingface.co/collections/nvidia/cosmos3 . The project website is available at https://research.nvidia.com/labs/cosmos-lab/cosmos3 .
World Action Models are Zero-shot Policies
Feb 17, 2026State-of-the-art Vision-Language-Action (VLA) models excel at semantic generalization but struggle to generalize to unseen physical motions in novel environments. We introduce DreamZero, a World Action Model (WAM) built upon a pretrained video diffusion backbone. Unlike VLAs, WAMs learn physical dynamics by predicting future world states and actions, using video as a dense representation of how the world evolves. By jointly modeling video and action, DreamZero learns diverse skills effectively from heterogeneous robot data without relying on repetitive demonstrations. This results in over 2x improvement in generalization to new tasks and environments compared to state-of-the-art VLAs in real robot experiments. Crucially, through model and system optimizations, we enable a 14B autoregressive video diffusion model to perform real-time closed-loop control at 7Hz. Finally, we demonstrate two forms of cross-embodiment transfer: video-only demonstrations from other robots or humans yield a relative improvement of over 42% on unseen task performance with just 10-20 minutes of data. More surprisingly, DreamZero enables few-shot embodiment adaptation, transferring to a new embodiment with only 30 minutes of play data while retaining zero-shot generalization.
DreamDojo: A Generalist Robot World Model from Large-Scale Human Videos
Feb 06, 2026Being able to simulate the outcomes of actions in varied environments will revolutionize the development of generalist agents at scale. However, modeling these world dynamics, especially for dexterous robotics tasks, poses significant challenges due to limited data coverage and scarce action labels. As an endeavor towards this end, we introduce DreamDojo, a foundation world model that learns diverse interactions and dexterous controls from 44k hours of egocentric human videos. Our data mixture represents the largest video dataset to date for world model pretraining, spanning a wide range of daily scenarios with diverse objects and skills. To address the scarcity of action labels, we introduce continuous latent actions as unified proxy actions, enhancing interaction knowledge transfer from unlabeled videos. After post-training on small-scale target robot data, DreamDojo demonstrates a strong understanding of physics and precise action controllability. We also devise a distillation pipeline that accelerates DreamDojo to a real-time speed of 10.81 FPS and further improves context consistency. Our work enables several important applications based on generative world models, including live teleoperation, policy evaluation, and model-based planning. Systematic evaluation on multiple challenging out-of-distribution (OOD) benchmarks verifies the significance of our method for simulating open-world, contact-rich tasks, paving the way for general-purpose robot world models.
Cosmos-Reason1: From Physical Common Sense To Embodied Reasoning
Mar 18, 2025Physical AI systems need to perceive, understand, and perform complex actions in the physical world. In this paper, we present the Cosmos-Reason1 models that can understand the physical world and generate appropriate embodied decisions (e.g., next step action) in natural language through long chain-of-thought reasoning processes. We begin by defining key capabilities for Physical AI reasoning, with a focus on physical common sense and embodied reasoning. To represent physical common sense, we use a hierarchical ontology that captures fundamental knowledge about space, time, and physics. For embodied reasoning, we rely on a two-dimensional ontology that generalizes across different physical embodiments. Building on these capabilities, we develop two multimodal large language models, Cosmos-Reason1-8B and Cosmos-Reason1-56B. We curate data and train our models in four stages: vision pre-training, general supervised fine-tuning (SFT), Physical AI SFT, and Physical AI reinforcement learning (RL) as the post-training. To evaluate our models, we build comprehensive benchmarks for physical common sense and embodied reasoning according to our ontologies. Evaluation results show that Physical AI SFT and reinforcement learning bring significant improvements. To facilitate the development of Physical AI, we will make our code and pre-trained models available under the NVIDIA Open Model License at https://github.com/nvidia-cosmos/cosmos-reason1.
Scalable Machine Learning Training Infrastructure for Online Ads Recommendation and Auction Scoring Modeling at Google
Jan 17, 2025



Large-scale Ads recommendation and auction scoring models at Google scale demand immense computational resources. While specialized hardware like TPUs have improved linear algebra computations, bottlenecks persist in large-scale systems. This paper proposes solutions for three critical challenges that must be addressed for efficient end-to-end execution in a widely used production infrastructure: (1) Input Generation and Ingestion Pipeline: Efficiently transforming raw features (e.g., "search query") into numerical inputs and streaming them to TPUs; (2) Large Embedding Tables: Optimizing conversion of sparse features into dense floating-point vectors for neural network consumption; (3) Interruptions and Error Handling: Minimizing resource wastage in large-scale shared datacenters. To tackle these challenges, we propose a shared input generation technique to reduce computational load of input generation by amortizing costs across many models. Furthermore, we propose partitioning, pipelining, and RPC (Remote Procedure Call) coalescing software techniques to optimize embedding operations. To maintain efficiency at scale, we describe novel preemption notice and training hold mechanisms that minimize resource wastage, and ensure prompt error resolution. These techniques have demonstrated significant improvement in Google production, achieving a 116% performance boost and an 18% reduction in training costs across representative models.
A Latent Dirichlet Allocation (LDA) Semantic Text Analytics Approach to Explore Topical Features in Charity Crowdfunding Campaigns
Jan 03, 2024Crowdfunding in the realm of the Social Web has received substantial attention, with prior research examining various aspects of campaigns, including project objectives, durations, and influential project categories for successful fundraising. These factors are crucial for entrepreneurs seeking donor support. However, the terrain of charity crowdfunding within the Social Web remains relatively unexplored, lacking comprehension of the motivations driving donations that often lack concrete reciprocation. Distinct from conventional crowdfunding that offers tangible returns, charity crowdfunding relies on intangible rewards like tax advantages, recognition posts, or advisory roles. Such details are often embedded within campaign narratives, yet, the analysis of textual content in charity crowdfunding is limited. This study introduces an inventive text analytics framework, utilizing Latent Dirichlet Allocation (LDA) to extract latent themes from textual descriptions of charity campaigns. The study has explored four different themes, two each in campaign and incentive descriptions. Campaign description themes are focused on child and elderly health mainly the ones who are diagnosed with terminal diseases. Incentive description themes are based on tax benefits, certificates, and appreciation posts. These themes, combined with numerical parameters, predict campaign success. The study was successful in using Random Forest Classifier to predict success of the campaign using both thematic and numerical parameters. The study distinguishes thematic categories, particularly medical need-based charity and general causes, based on project and incentive descriptions. In conclusion, this research bridges the gap by showcasing topic modelling utility in uncharted charity crowdfunding domains.
TPU v4: An Optically Reconfigurable Supercomputer for Machine Learning with Hardware Support for Embeddings
Apr 20, 2023In response to innovations in machine learning (ML) models, production workloads changed radically and rapidly. TPU v4 is the fifth Google domain specific architecture (DSA) and its third supercomputer for such ML models. Optical circuit switches (OCSes) dynamically reconfigure its interconnect topology to improve scale, availability, utilization, modularity, deployment, security, power, and performance; users can pick a twisted 3D torus topology if desired. Much cheaper, lower power, and faster than Infiniband, OCSes and underlying optical components are <5% of system cost and <3% of system power. Each TPU v4 includes SparseCores, dataflow processors that accelerate models that rely on embeddings by 5x-7x yet use only 5% of die area and power. Deployed since 2020, TPU v4 outperforms TPU v3 by 2.1x and improves performance/Watt by 2.7x. The TPU v4 supercomputer is 4x larger at 4096 chips and thus ~10x faster overall, which along with OCS flexibility helps large language models. For similar sized systems, it is ~4.3x-4.5x faster than the Graphcore IPU Bow and is 1.2x-1.7x faster and uses 1.3x-1.9x less power than the Nvidia A100. TPU v4s inside the energy-optimized warehouse scale computers of Google Cloud use ~3x less energy and produce ~20x less CO2e than contemporary DSAs in a typical on-premise data center.
Google's Neural Machine Translation System: Bridging the Gap between Human and Machine Translation
Oct 08, 2016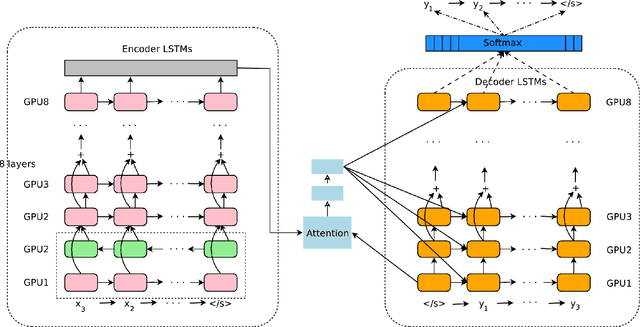

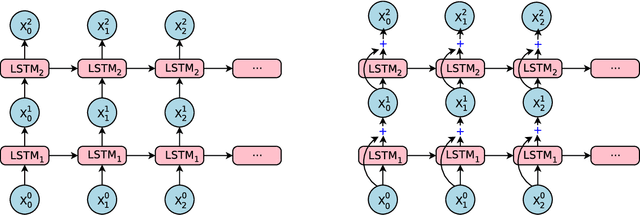
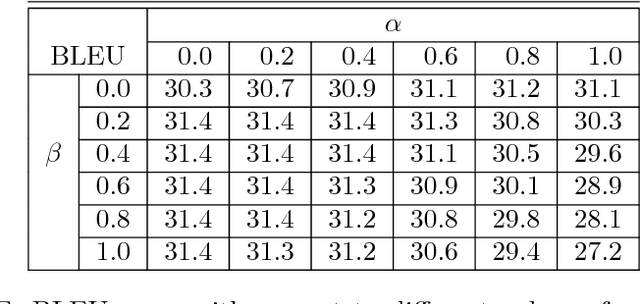
Neural Machine Translation (NMT) is an end-to-end learning approach for automated translation, with the potential to overcome many of the weaknesses of conventional phrase-based translation systems. Unfortunately, NMT systems are known to be computationally expensive both in training and in translation inference. Also, most NMT systems have difficulty with rare words. These issues have hindered NMT's use in practical deployments and services, where both accuracy and speed are essential. In this work, we present GNMT, Google's Neural Machine Translation system, which attempts to address many of these issues. Our model consists of a deep LSTM network with 8 encoder and 8 decoder layers using attention and residual connections. To improve parallelism and therefore decrease training time, our attention mechanism connects the bottom layer of the decoder to the top layer of the encoder. To accelerate the final translation speed, we employ low-precision arithmetic during inference computations. To improve handling of rare words, we divide words into a limited set of common sub-word units ("wordpieces") for both input and output. This method provides a good balance between the flexibility of "character"-delimited models and the efficiency of "word"-delimited models, naturally handles translation of rare words, and ultimately improves the overall accuracy of the system. Our beam search technique employs a length-normalization procedure and uses a coverage penalty, which encourages generation of an output sentence that is most likely to cover all the words in the source sentence. On the WMT'14 English-to-French and English-to-German benchmarks, GNMT achieves competitive results to state-of-the-art. Using a human side-by-side evaluation on a set of isolated simple sentences, it reduces translation errors by an average of 60% compared to Google's phrase-based production system.