 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Safety Report on GPT-5.2, Gemini 3 Pro, Qwen3-VL, Grok 4.1 Fast, Nano Banana Pro, and Seedream 4.5
Jan 16, 2026The rapid evolution of Large Language Models (LLMs) and Multimodal Large Language Models (MLLMs) has driven major gains in reasoning, perception, and generation across language and vision, yet whether these advances translate into comparable improvements in safety remains unclear, partly due to fragmented evaluations that focus on isolated modalities or threat models. In this report, we present an integrated safety evaluation of six frontier models--GPT-5.2, Gemini 3 Pro, Qwen3-VL, Grok 4.1 Fast, Nano Banana Pro, and Seedream 4.5--assessing each across language, vision-language, and image generation using a unified protocol that combines benchmark, adversarial, multilingual, and compliance evaluations. By aggregating results into safety leaderboards and model profiles, we reveal a highly uneven safety landscape: while GPT-5.2 demonstrates consistently strong and balanced performance, other models exhibit clear trade-offs across benchmark safety, adversarial robustness, multilingual generalization, and regulatory compliance. Despite strong results under standard benchmarks, all models remain highly vulnerable under adversarial testing, with worst-case safety rates dropping below 6%. Text-to-image models show slightly stronger alignment in regulated visual risk categories, yet remain fragile when faced with adversarial or semantically ambiguous prompts. Overall, these findings highlight that safety in frontier models is inherently multidimensional--shaped by modality, language, and evaluation design--underscoring the need for standardized, holistic safety assessments to better reflect real-world risk and guide responsible deployment.
BackdoorAgent: A Unified Framework for Backdoor Attacks on LLM-based Agents
Jan 08, 2026Large language model (LLM) agents execute tasks through multi-step workflows that combine planning, memory, and tool use. While this design enables autonomy, it also expands the attack surface for backdoor threats. Backdoor triggers injected into specific stages of an agent workflow can persist through multiple intermediate states and adversely influence downstream outputs. However, existing studies remain fragmented and typically analyze individual attack vectors in isolation, leaving the cross-stage interaction and propagation of backdoor triggers poorly understood from an agent-centric perspective. To fill this gap, we propose \textbf{BackdoorAgent}, a modular and stage-aware framework that provides a unified, agent-centric view of backdoor threats in LLM agents. BackdoorAgent structures the attack surface into three functional stages of agentic workflows, including \textbf{planning attacks}, \textbf{memory attacks}, and \textbf{tool-use attacks}, and instruments agent execution to enable systematic analysis of trigger activation and propagation across different stages. Building on this framework, we construct a standardized benchmark spanning four representative agent applications: \textbf{Agent QA}, \textbf{Agent Code}, \textbf{Agent Web}, and \textbf{Agent Drive}, covering both language-only and multimodal settings. Our empirical analysis shows that \textit{triggers implanted at a single stage can persist across multiple steps and propagate through intermediate states.} For instance, when using a GPT-based backbone, we observe trigger persistence in 43.58\% of planning attacks, 77.97\% of memory attacks, and 60.28\% of tool-stage attacks, highlighting the vulnerabilities of the agentic workflow itself to backdoor threats. To facilitate reproducibility and future research, our code and benchmark are publicly available at GitHub.
CodeRAG: Finding Relevant and Necessary Knowledge for Retrieval-Augmented Repository-Level Code Completion
Sep 19, 2025Repository-level code completion automatically predicts the unfinished code based on the broader information from the repository. Recent strides in Code Large Language Models (code LLMs) have spurred the development of repository-level code completion methods, yielding promising results. Nevertheless, they suffer from issues such as inappropriate query construction, single-path code retrieval, and misalignment between code retriever and code LLM. To address these problems, we introduce CodeRAG, a framework tailored to identify relevant and necessary knowledge for retrieval-augmented repository-level code completion. Its core components include log probability guided query construction, multi-path code retrieval, and preference-aligned BestFit reranking. Extensive experiments on benchmarks ReccEval and CCEval demonstrate that CodeRAG significantly and consistently outperforms state-of-the-art methods. The implementation of CodeRAG is available at https://github.com/KDEGroup/CodeRAG.
Digital Gatekeepers: Google's Role in Curating Hashtags and Subreddits
Jun 17, 2025Search engines play a crucial role as digital gatekeepers, shaping the visibility of Web and social media content through algorithmic curation. This study investigates how search engines like Google selectively promotes or suppresses certain hashtags and subreddits, impacting the information users encounter. By comparing search engine results with nonsampled data from Reddit and Twitter/X, we reveal systematic biases in content visibility. Google's algorithms tend to suppress subreddits and hashtags related to sexually explicit material, conspiracy theories, advertisements, and cryptocurrencies, while promoting content associated with higher engagement. These findings suggest that Google's gatekeeping practices influence public discourse by curating the social media narratives available to users.
* Accepted to ACL 2025 Main
AutoData: A Multi-Agent System for Open Web Data Collection
May 21, 2025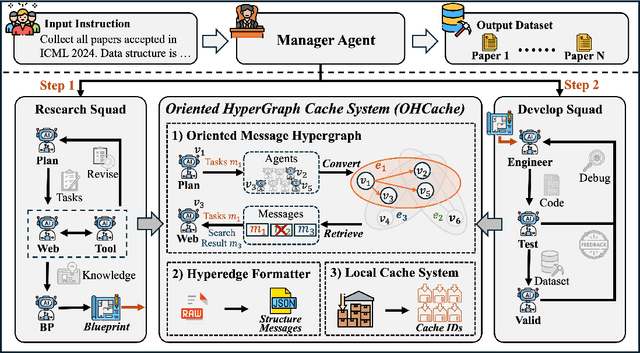
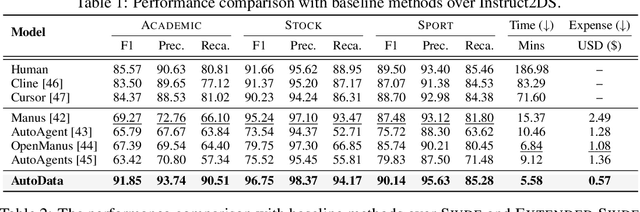
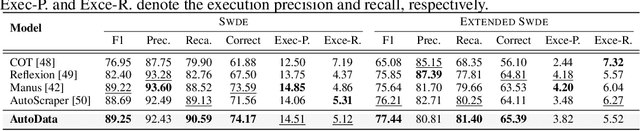

The exponential growth of data-driven systems and AI technologies has intensified the demand for high-quality web-sourced datasets. While existing datasets have proven valuable, conventional web data collection approaches face significant limitations in terms of human effort and scalability. Current data-collecting solutions fall into two categories: wrapper-based methods that struggle with adaptability and reproducibility, and large language model (LLM)-based approaches that incur substantial computational and financial costs. To address these challenges, we propose AutoData, a novel multi-agent system for Automated web Data collection, that requires minimal human intervention, i.e., only necessitating a natural language instruction specifying the desired dataset. In addition, AutoData is designed with a robust multi-agent architecture, featuring a novel oriented message hypergraph coordinated by a central task manager, to efficiently organize agents across research and development squads. Besides, we introduce a novel hypergraph cache system to advance the multi-agent collaboration process that enables efficient automated data collection and mitigates the token cost issues prevalent in existing LLM-based systems. Moreover, we introduce Instruct2DS, a new benchmark dataset supporting live data collection from web sources across three domains: academic, finance, and sports. Comprehensive evaluations over Instruct2DS and three existing benchmark datasets demonstrate AutoData's superior performance compared to baseline methods. Case studies on challenging tasks such as picture book collection and paper extraction from surveys further validate its applicability. Our source code and dataset are available at https://github.com/GraphResearcher/AutoData.
Scenethesis: A Language and Vision Agentic Framework for 3D Scene Generation
May 05, 2025Synthesizing interactive 3D scenes from text is essential for gaming, virtual reality, and embodied AI. However, existing methods face several challenges. Learning-based approaches depend on small-scale indoor datasets, limiting the scene diversity and layout complexity. While large language models (LLMs) can leverage diverse text-domain knowledge, they struggle with spatial realism, often producing unnatural object placements that fail to respect common sense. Our key insight is that vision perception can bridge this gap by providing realistic spatial guidance that LLMs lack. To this end, we introduce Scenethesis, a training-free agentic framework that integrates LLM-based scene planning with vision-guided layout refinement. Given a text prompt, Scenethesis first employs an LLM to draft a coarse layout. A vision module then refines it by generating an image guidance and extracting scene structure to capture inter-object relations. Next, an optimization module iteratively enforces accurate pose alignment and physical plausibility, preventing artifacts like object penetration and instability. Finally, a judge module verifies spatial coherence. Comprehensive experiments show that Scenethesis generates diverse, realistic, and physically plausible 3D interactive scenes, making it valuable for virtual content creation, simulation environments, and embodied AI research.
Describe Anything: Detailed Localized Image and Video Captioning
Apr 22, 2025Generating detailed and accurate descriptions for specific regions in images and videos remains a fundamental challenge for vision-language models. We introduce the Describe Anything Model (DAM), a model designed for detailed localized captioning (DLC). DAM preserves both local details and global context through two key innovations: a focal prompt, which ensures high-resolution encoding of targeted regions, and a localized vision backbone, which integrates precise localization with its broader context. To tackle the scarcity of high-quality DLC data, we propose a Semi-supervised learning (SSL)-based Data Pipeline (DLC-SDP). DLC-SDP starts with existing segmentation datasets and expands to unlabeled web images using SSL. We introduce DLC-Bench, a benchmark designed to evaluate DLC without relying on reference captions. DAM sets new state-of-the-art on 7 benchmarks spanning keyword-level, phrase-level, and detailed multi-sentence localized image and video captioning.
Revisiting Likelihood-Based Out-of-Distribution Detection by Modeling Representations
Apr 10, 2025Out-of-distribution (OOD) detection is critical for ensuring the reliability of deep learning systems, particularly in safety-critical applications. Likelihood-based deep generative models have historically faced criticism for their unsatisfactory performance in OOD detection, often assigning higher likelihood to OOD data than in-distribution samples when applied to image data. In this work, we demonstrate that likelihood is not inherently flawed. Rather, several properties in the images space prohibit likelihood as a valid detection score. Given a sufficiently good likelihood estimator, specifically using the probability flow formulation of a diffusion model, we show that likelihood-based methods can still perform on par with state-of-the-art methods when applied in the representation space of pre-trained encoders. The code of our work can be found at $\href{https://github.com/limchaos/Likelihood-OOD.git}{\texttt{https://github.com/limchaos/Likelihood-OOD.git}}$.
Cosmos-Reason1: From Physical Common Sense To Embodied Reasoning
Mar 18, 2025Physical AI systems need to perceive, understand, and perform complex actions in the physical world. In this paper, we present the Cosmos-Reason1 models that can understand the physical world and generate appropriate embodied decisions (e.g., next step action) in natural language through long chain-of-thought reasoning processes. We begin by defining key capabilities for Physical AI reasoning, with a focus on physical common sense and embodied reasoning. To represent physical common sense, we use a hierarchical ontology that captures fundamental knowledge about space, time, and physics. For embodied reasoning, we rely on a two-dimensional ontology that generalizes across different physical embodiments. Building on these capabilities, we develop two multimodal large language models, Cosmos-Reason1-8B and Cosmos-Reason1-56B. We curate data and train our models in four stages: vision pre-training, general supervised fine-tuning (SFT), Physical AI SFT, and Physical AI reinforcement learning (RL) as the post-training. To evaluate our models, we build comprehensive benchmarks for physical common sense and embodied reasoning according to our ontologies. Evaluation results show that Physical AI SFT and reinforcement learning bring significant improvements. To facilitate the development of Physical AI, we will make our code and pre-trained models available under the NVIDIA Open Model License at https://github.com/nvidia-cosmos/cosmos-reason1.
Cosmos World Foundation Model Platform for Physical AI
Jan 07, 2025



Physical AI needs to be trained digitally first. It needs a digital twin of itself, the policy model, and a digital twin of the world, the world model. In this paper, we present the Cosmos World Foundation Model Platform to help developers build customized world models for their Physical AI setups. We position a world foundation model as a general-purpose world model that can be fine-tuned into customized world models for downstream applications. Our platform covers a video curation pipeline, pre-trained world foundation models, examples of post-training of pre-trained world foundation models, and video tokenizers. To help Physical AI builders solve the most critical problems of our society, we make our platform open-source and our models open-weight with permissive licenses available via https://github.com/NVIDIA/Cosmos.