 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Controllable Image Generation through Representation-Conditioned Diffusion Models
May 26, 2026Diffusion models have emerged as powerful tools for high-quality image generation and editing, but guiding these models to produce specific outputs remains a challenge. Conventional approaches rely on conditioning mechanisms, such as text prompts or semantic maps, which require extensively annotated datasets. In this preliminary work, we explore diffusion models conditioned on representations from a pre-trained self-supervised model. The self-conditioning mechanism not only improves the quality of unconditional image generation, but also provides a representation space that can be used to control the generation. We explore this conditioning space by identifying directions of variations, and demonstrate promising properties in terms of smoothness and disentanglement.
Representation-Conditioned Diffusion Models for Guided Training Data Generation
May 26, 2026Data availability remains a critical bottleneck in many deep learning applications. Large-scale datasets are often expensive to collect, curate and annotate, which can limit the scalability and applicability of supervised learning methods. In this work, we evaluate the classification performance of models trained on synthetic image datasets produced by generative deep learning. In particular, we use latent diffusion models conditioned on learned representations from DINOv2, DINOv3, and CLIP. Our results demonstrates that this representation-conditioned formulation significantly outperforms class-conditioned generation by a large margin (+10.76 p.p. top-1 accuracy on ImageNet100), by improving sample quality and mode coverage. Furthermore, by scaling the size of the synthetic dataset, we are able to outperform a classifier trained on the real data (+2.0 p.p top-1 accuracy). We also demonstrate how generated images can be used for augmentation purposes, outperforming classical augmentation methods, and how the conditioning space can be used for sample filtering to further improve training value. Collectively, these findings highlight that representation-conditioned diffusion models provide a promising approach for augmenting, complementing, or potentially replacing real-world datasets in large-scale visual learning tasks.
Commutator-Induced Uncertainty in VAEs
May 22, 2026Variational autoencoders (VAEs) often struggle to represent non-commutative structure in learned latent spaces. Symmetry-aware VAEs commonly address this issue by enforcing commutativity through algebraic regularization, which is appropriate for commutative transformation groups but can suppress meaningful non-commutative structure when it is intrinsic to the data. We argue that non-commutativity should instead be explicitly diagnosed and reflected in reconstruction behavior. We introduce a Lie Group VAE framework that combines geometric and algebraic perspectives on uncertainty while separating discrete generative factors from continuous geometric transformations. In a first phase, the model is trained without structural constraints while algebraic non-commutativity is measured through finite Baker-Campbell-Hausdorff deviations and decoder order sensitivity is measured through reconstruction order-swap tests. These diagnostics reveal a scale mismatch between latent non-commutativity and reconstruction behavior under unconstrained training. In a second phase, we introduce a deformation-stability constraint with a data-driven calibration constant that aligns decoder sensitivity with algebraic non-commutativity. We evaluate the framework on dSprites, 3DShapes, 3DCars, and CelebA against generic and symmetry-aware baselines, including beta-VAE, CLG-VAE, and CFASL. Across synthetic benchmarks, the method improves reconstruction quality and yields decoder-level behavior more consistent with latent non-commutative structure. Qualitative analyses show clearer order-dependent latent compositions and more stable reconstructions. On CelebA, the model yields more faithful reconstructions and factor-specific latent traversals than CFASL, while also exhibiting meaningful order-dependent interactions between learned latent directions.
Exploring Metric Fusion for Evaluation of NeRFs
Sep 16, 2025Neural Radiance Fields (NeRFs) have demonstrated significant potential in synthesizing novel viewpoints. Evaluating the NeRF-generated outputs, however, remains a challenge due to the unique artifacts they exhibit, and no individual metric performs well across all datasets. We hypothesize that combining two successful metrics, Deep Image Structure and Texture Similarity (DISTS) and Video Multi-Method Assessment Fusion (VMAF), based on different perceptual methods, can overcome the limitations of individual metrics and achieve improved correlation with subjective quality scores. We experiment with two normalization strategies for the individual metrics and two fusion strategies to evaluate their impact on the resulting correlation with the subjective scores. The proposed pipeline is tested on two distinct datasets, Synthetic and Outdoor, and its performance is evaluated across three different configurations. We present a detailed analysis comparing the correlation coefficients of fusion methods and individual scores with subjective scores to demonstrate the robustness and generalizability of the fusion metrics.
Revisiting Likelihood-Based Out-of-Distribution Detection by Modeling Representations
Apr 10, 2025Out-of-distribution (OOD) detection is critical for ensuring the reliability of deep learning systems, particularly in safety-critical applications. Likelihood-based deep generative models have historically faced criticism for their unsatisfactory performance in OOD detection, often assigning higher likelihood to OOD data than in-distribution samples when applied to image data. In this work, we demonstrate that likelihood is not inherently flawed. Rather, several properties in the images space prohibit likelihood as a valid detection score. Given a sufficiently good likelihood estimator, specifically using the probability flow formulation of a diffusion model, we show that likelihood-based methods can still perform on par with state-of-the-art methods when applied in the representation space of pre-trained encoders. The code of our work can be found at $\href{https://github.com/limchaos/Likelihood-OOD.git}{\texttt{https://github.com/limchaos/Likelihood-OOD.git}}$.
Detecting Domain Shift in Multiple Instance Learning for Digital Pathology Using Fréchet Domain Distance
May 16, 2024Multiple-instance learning (MIL) is an attractive approach for digital pathology applications as it reduces the costs related to data collection and labelling. However, it is not clear how sensitive MIL is to clinically realistic domain shifts, i.e., differences in data distribution that could negatively affect performance, and if already existing metrics for detecting domain shifts work well with these algorithms. We trained an attention-based MIL algorithm to classify whether a whole-slide image of a lymph node contains breast tumour metastases. The algorithm was evaluated on data from a hospital in a different country and various subsets of this data that correspond to different levels of domain shift. Our contributions include showing that MIL for digital pathology is affected by clinically realistic differences in data, evaluating which features from a MIL model are most suitable for detecting changes in performance, and proposing an unsupervised metric named Fr\'echet Domain Distance (FDD) for quantification of domain shifts. Shift measure performance was evaluated through the mean Pearson correlation to change in classification performance, where FDD achieved 0.70 on 10-fold cross-validation models. The baselines included Deep ensemble, Difference of Confidence, and Representation shift which resulted in 0.45, -0.29, and 0.56 mean Pearson correlation, respectively. FDD could be a valuable tool for care providers and vendors who need to verify if a MIL system is likely to perform reliably when implemented at a new site, without requiring any additional annotations from pathologists.
Joint tone mapping and denoising of thermal infrared images via multi-scale Retinex and multi-task learning
May 01, 2023Cameras digitize real-world scenes as pixel intensity values with a limited value range given by the available bits per pixel (bpp). High Dynamic Range (HDR) cameras capture those luminance values in higher resolution through an increase in the number of bpp. Most displays, however, are limited to 8 bpp. Naive HDR compression methods lead to a loss of the rich information contained in those HDR images. In this paper, tone mapping algorithms for thermal infrared images with 16 bpp are investigated that can preserve this information. An optimized multi-scale Retinex algorithm sets the baseline. This algorithm is then approximated with a deep learning approach based on the popular U-Net architecture. The remaining noise in the images after tone mapping is reduced implicitly by utilizing a self-supervised deep learning approach that can be jointly trained with the tone mapping approach in a multi-task learning scheme. Further discussions are provided on denoising and deflickering for thermal infrared video enhancement in the context of tone mapping. Extensive experiments on the public FLIR ADAS Dataset prove the effectiveness of our proposed method in comparison with the state-of-the-art.
Standalone Neural ODEs with Sensitivity Analysis
Jun 08, 2022

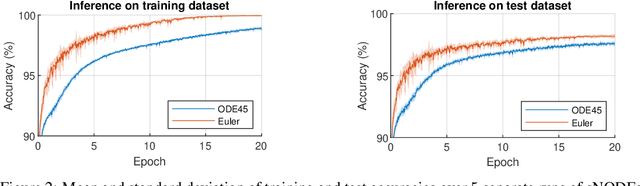
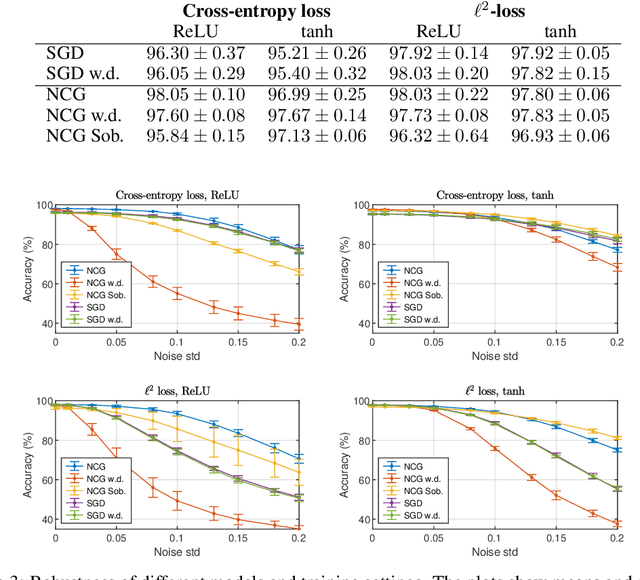
This paper presents the Standalone Neural ODE (sNODE), a continuous-depth neural ODE model capable of describing a full deep neural network. This uses a novel nonlinear conjugate gradient (NCG) descent optimization scheme for training, where the Sobolev gradient can be incorporated to improve smoothness of model weights. We also present a general formulation of the neural sensitivity problem and show how it is used in the NCG training. The sensitivity analysis provides a reliable measure of uncertainty propagation throughout a network, and can be used to study model robustness and to generate adversarial attacks. Our evaluations demonstrate that our novel formulations lead to increased robustness and performance as compared to ResNet models, and that it opens up for new opportunities for designing and developing machine learning with improved explainability.
Learning via nonlinear conjugate gradients and depth-varying neural ODEs
Feb 11, 2022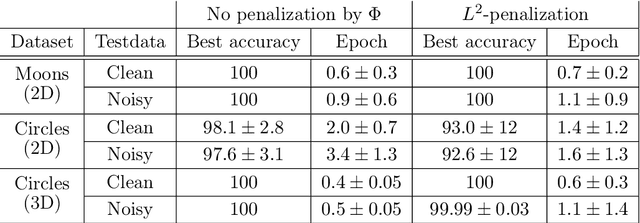
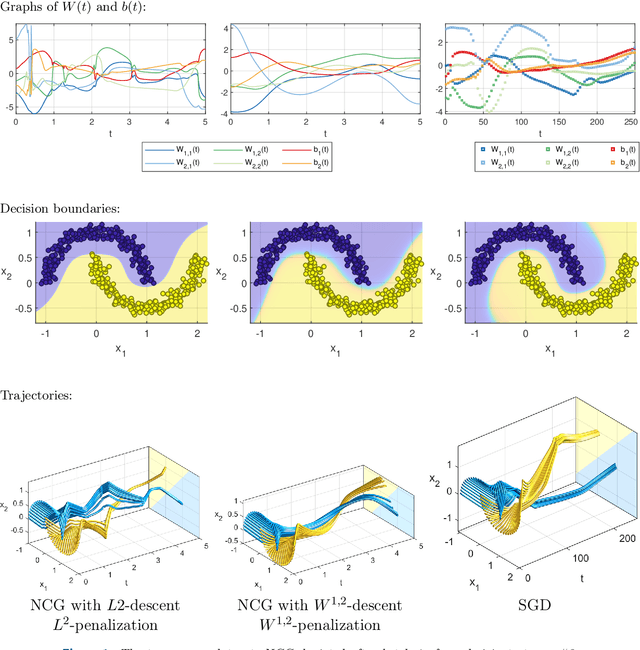
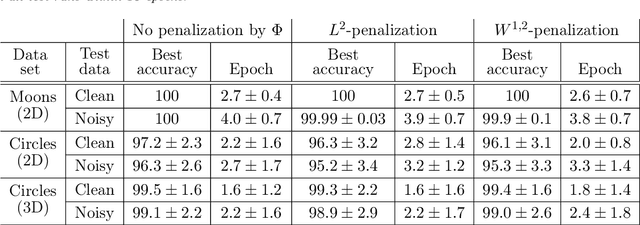
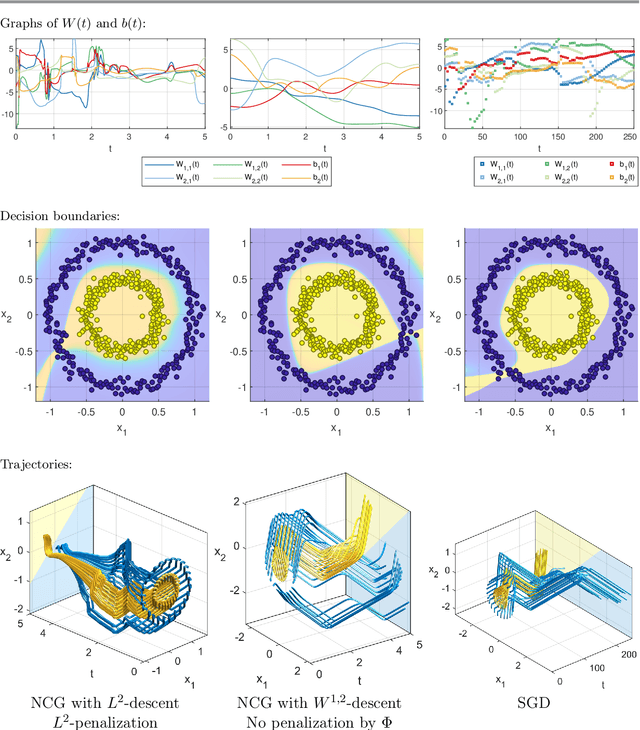
The inverse problem of supervised reconstruction of depth-variable (time-dependent) parameters in a neural ordinary differential equation (NODE) is considered, that means finding the weights of a residual network with time continuous layers. The NODE is treated as an isolated entity describing the full network as opposed to earlier research, which embedded it between pre- and post-appended layers trained by conventional methods. The proposed parameter reconstruction is done for a general first order differential equation by minimizing a cost functional covering a variety of loss functions and penalty terms. A nonlinear conjugate gradient method (NCG) is derived for the minimization. Mathematical properties are stated for the differential equation and the cost functional. The adjoint problem needed is derived together with a sensitivity problem. The sensitivity problem can estimate changes in the network output under perturbation of the trained parameters. To preserve smoothness during the iterations the Sobolev gradient is calculated and incorporated. As a proof-of-concept, numerical results are included for a NODE and two synthetic datasets, and compared with standard gradient approaches (not based on NODEs). The results show that the proposed method works well for deep learning with infinite numbers of layers, and has built-in stability and smoothness.
Can uncertainty boost the reliability of AI-based diagnostic methods in digital pathology?
Dec 17, 2021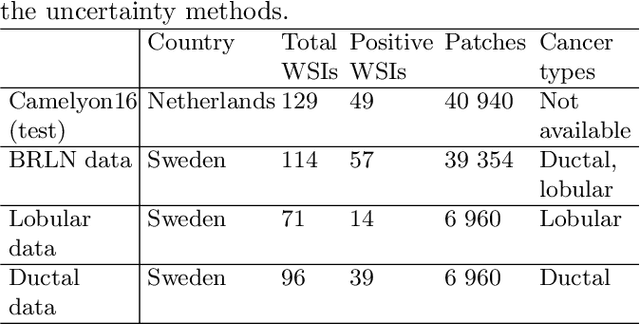


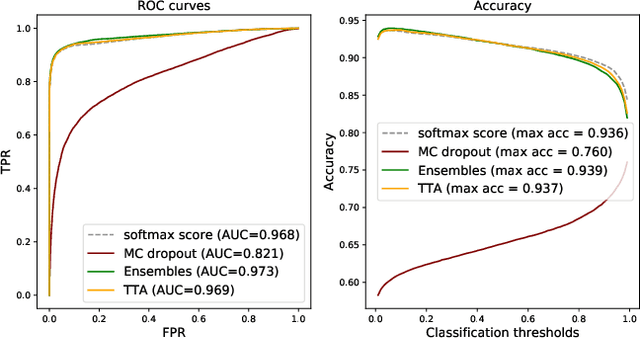
Deep learning (DL) has shown great potential in digital pathology applications. The robustness of a diagnostic DL-based solution is essential for safe clinical deployment. In this work we evaluate if adding uncertainty estimates for DL predictions in digital pathology could result in increased value for the clinical applications, by boosting the general predictive performance or by detecting mispredictions. We compare the effectiveness of model-integrated methods (MC dropout and Deep ensembles) with a model-agnostic approach (Test time augmentation, TTA). Moreover, four uncertainty metrics are compared. Our experiments focus on two domain shift scenarios: a shift to a different medical center and to an underrepresented subtype of cancer. Our results show that uncertainty estimates can add some reliability and reduce sensitivity to classification threshold selection. While advanced metrics and deep ensembles perform best in our comparison, the added value over simpler metrics and TTA is small. Importantly, the benefit of all evaluated uncertainty estimation methods is diminished by domain shift.