 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStandalone Neural ODEs with Sensitivity Analysis
Jun 08, 2022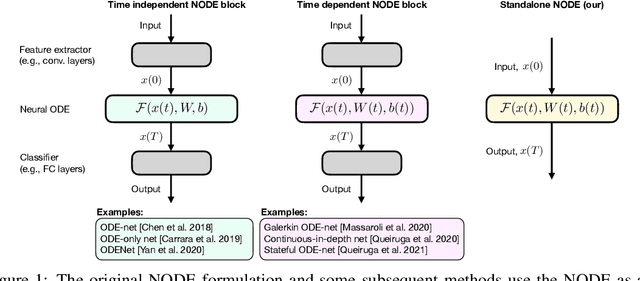

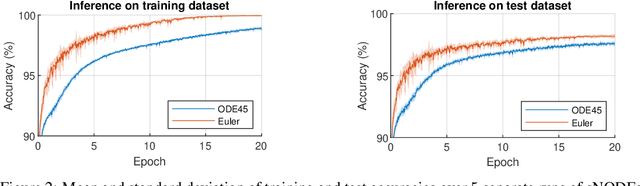
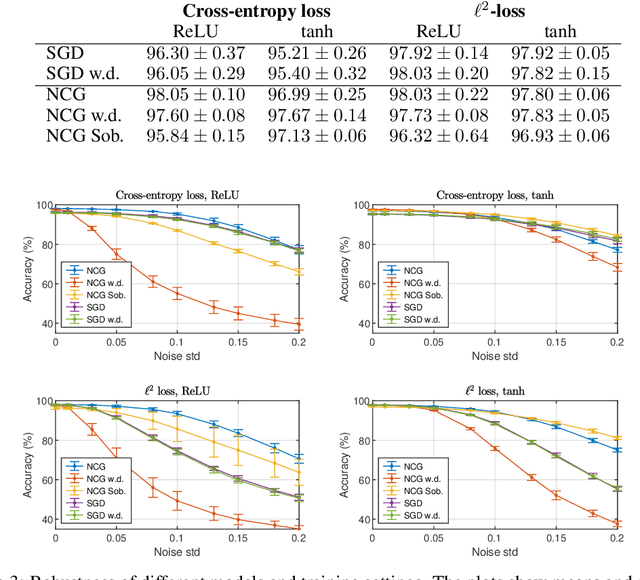
This paper presents the Standalone Neural ODE (sNODE), a continuous-depth neural ODE model capable of describing a full deep neural network. This uses a novel nonlinear conjugate gradient (NCG) descent optimization scheme for training, where the Sobolev gradient can be incorporated to improve smoothness of model weights. We also present a general formulation of the neural sensitivity problem and show how it is used in the NCG training. The sensitivity analysis provides a reliable measure of uncertainty propagation throughout a network, and can be used to study model robustness and to generate adversarial attacks. Our evaluations demonstrate that our novel formulations lead to increased robustness and performance as compared to ResNet models, and that it opens up for new opportunities for designing and developing machine learning with improved explainability.
Learning via nonlinear conjugate gradients and depth-varying neural ODEs
Feb 11, 2022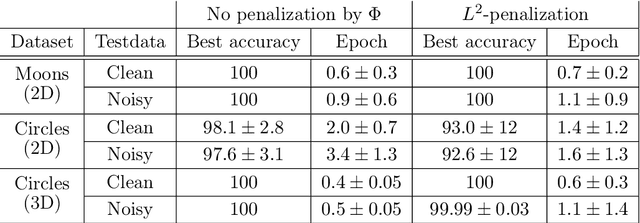
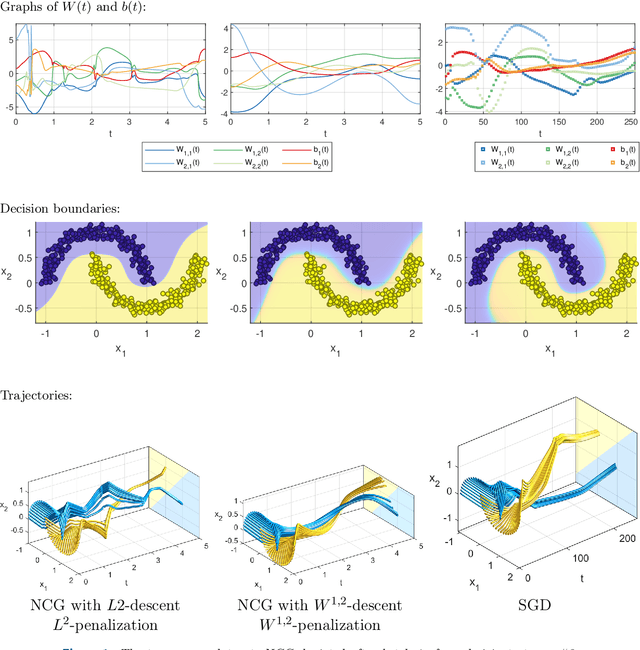
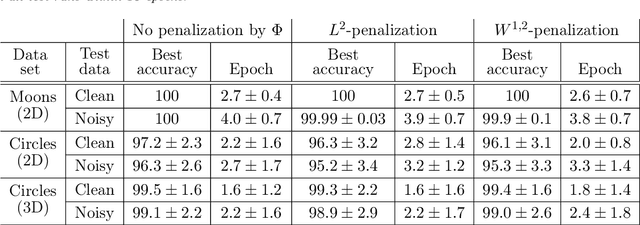
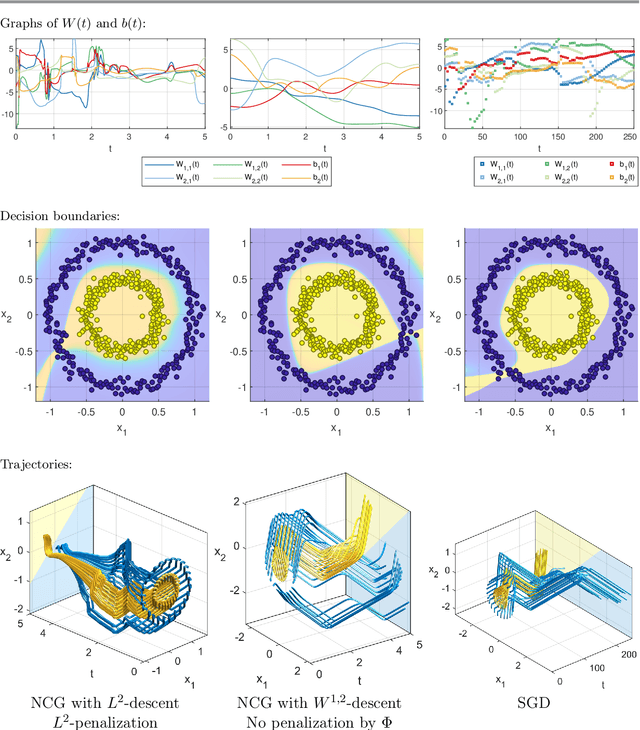
The inverse problem of supervised reconstruction of depth-variable (time-dependent) parameters in a neural ordinary differential equation (NODE) is considered, that means finding the weights of a residual network with time continuous layers. The NODE is treated as an isolated entity describing the full network as opposed to earlier research, which embedded it between pre- and post-appended layers trained by conventional methods. The proposed parameter reconstruction is done for a general first order differential equation by minimizing a cost functional covering a variety of loss functions and penalty terms. A nonlinear conjugate gradient method (NCG) is derived for the minimization. Mathematical properties are stated for the differential equation and the cost functional. The adjoint problem needed is derived together with a sensitivity problem. The sensitivity problem can estimate changes in the network output under perturbation of the trained parameters. To preserve smoothness during the iterations the Sobolev gradient is calculated and incorporated. As a proof-of-concept, numerical results are included for a NODE and two synthetic datasets, and compared with standard gradient approaches (not based on NODEs). The results show that the proposed method works well for deep learning with infinite numbers of layers, and has built-in stability and smoothness.