 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEthical Considerations for the Military Use of Artificial Intelligence in Visual Reconnaissance
Feb 05, 2025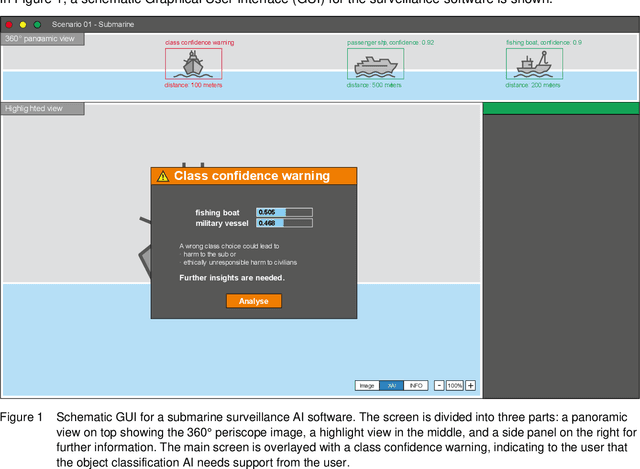
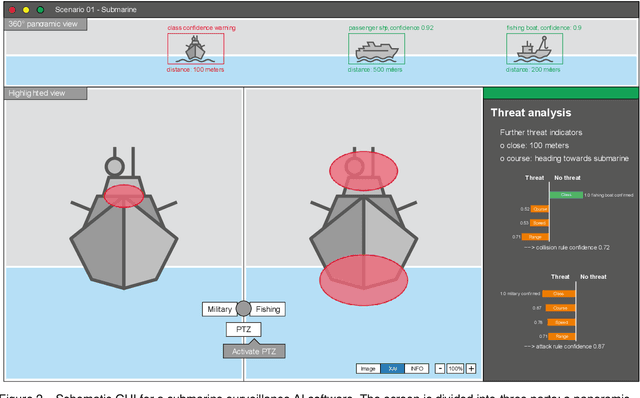
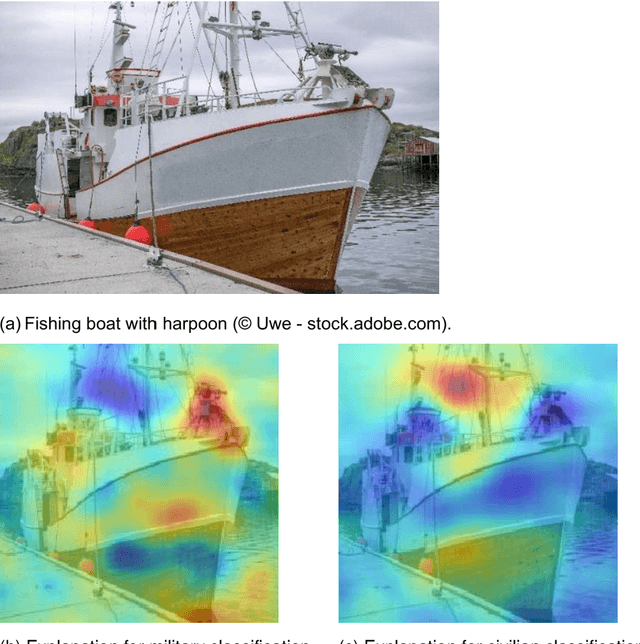
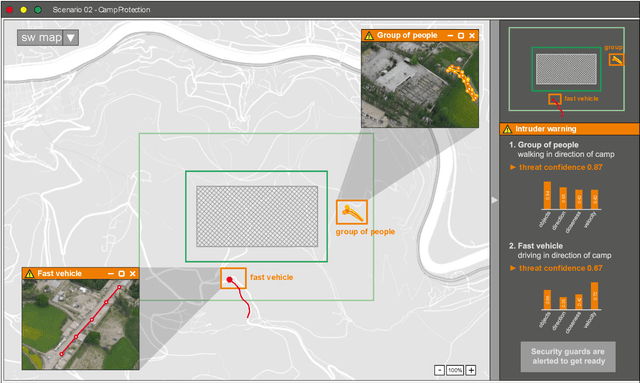
This white paper underscores the critical importance of responsibly deploying Artificial Intelligence (AI) in military contexts, emphasizing a commitment to ethical and legal standards. The evolving role of AI in the military goes beyond mere technical applications, necessitating a framework grounded in ethical principles. The discussion within the paper delves into ethical AI principles, particularly focusing on the Fairness, Accountability, Transparency, and Ethics (FATE) guidelines. Noteworthy considerations encompass transparency, justice, non-maleficence, and responsibility. Importantly, the paper extends its examination to military-specific ethical considerations, drawing insights from the Just War theory and principles established by prominent entities. In addition to the identified principles, the paper introduces further ethical considerations specifically tailored for military AI applications. These include traceability, proportionality, governability, responsibility, and reliability. The application of these ethical principles is discussed on the basis of three use cases in the domains of sea, air, and land. Methods of automated sensor data analysis, eXplainable AI (XAI), and intuitive user experience are utilized to specify the use cases close to real-world scenarios. This comprehensive approach to ethical considerations in military AI reflects a commitment to aligning technological advancements with established ethical frameworks. It recognizes the need for a balance between leveraging AI's potential benefits in military operations while upholding moral and legal standards. The inclusion of these ethical principles serves as a foundation for responsible and accountable use of AI in the complex and dynamic landscape of military scenarios.
OSSA: Unsupervised One-Shot Style Adaptation
Oct 01, 2024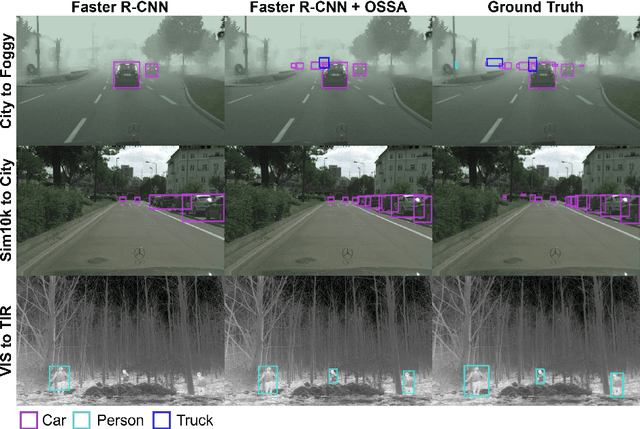
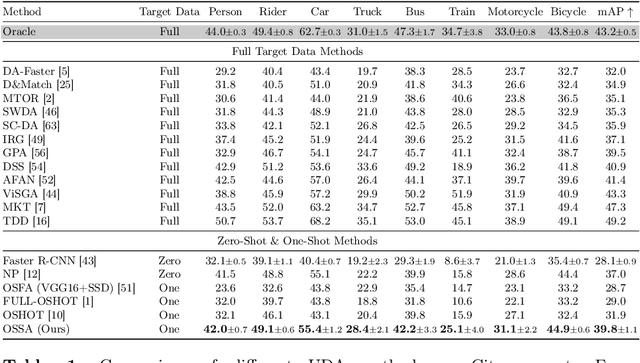
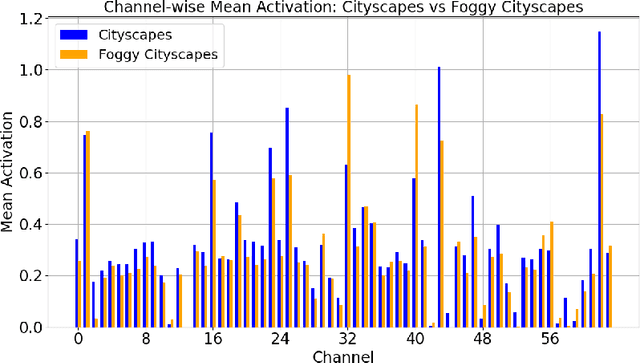
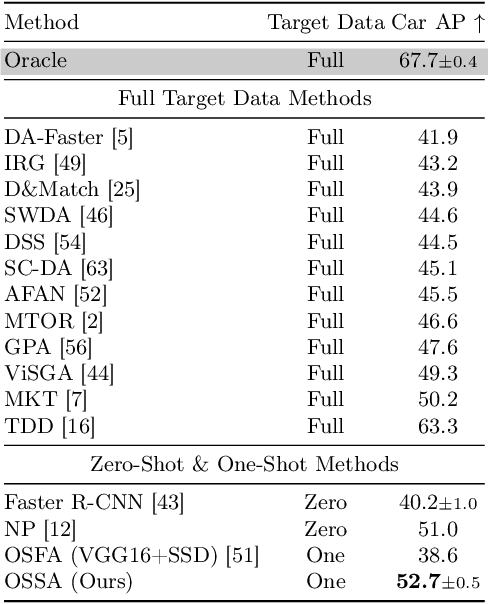
Despite their success in various vision tasks, deep neural network architectures often underperform in out-of-distribution scenarios due to the difference between training and target domain style. To address this limitation, we introduce One-Shot Style Adaptation (OSSA), a novel unsupervised domain adaptation method for object detection that utilizes a single, unlabeled target image to approximate the target domain style. Specifically, OSSA generates diverse target styles by perturbing the style statistics derived from a single target image and then applies these styles to a labeled source dataset at the feature level using Adaptive Instance Normalization (AdaIN). Extensive experiments show that OSSA establishes a new state-of-the-art among one-shot domain adaptation methods by a significant margin, and in some cases, even outperforms strong baselines that use thousands of unlabeled target images. By applying OSSA in various scenarios, including weather, simulated-to-real (sim2real), and visual-to-thermal adaptations, our study explores the overarching significance of the style gap in these contexts. OSSA's simplicity and efficiency allow easy integration into existing frameworks, providing a potentially viable solution for practical applications with limited data availability. Code is available at https://github.com/RobinGerster7/OSSA
Utilizing Grounded SAM for self-supervised frugal camouflaged human detection
Jun 09, 2024Visually detecting camouflaged objects is a hard problem for both humans and computer vision algorithms. Strong similarities between object and background appearance make the task significantly more challenging than traditional object detection or segmentation tasks. Current state-of-the-art models use either convolutional neural networks or vision transformers as feature extractors. They are trained in a fully supervised manner and thus need a large amount of labeled training data. In this paper, both self-supervised and frugal learning methods are introduced to the task of Camouflaged Object Detection (COD). The overall goal is to fine-tune two COD reference methods, namely SINet-V2 and HitNet, pre-trained for camouflaged animal detection to the task of camouflaged human detection. Therefore, we use the public dataset CPD1K that contains camouflaged humans in a forest environment. We create a strong baseline using supervised frugal transfer learning for the fine-tuning task. Then, we analyze three pseudo-labeling approaches to perform the fine-tuning task in a self-supervised manner. Our experiments show that we achieve similar performance by pure self-supervision compared to fully supervised frugal learning.
Joint tone mapping and denoising of thermal infrared images via multi-scale Retinex and multi-task learning
May 01, 2023Cameras digitize real-world scenes as pixel intensity values with a limited value range given by the available bits per pixel (bpp). High Dynamic Range (HDR) cameras capture those luminance values in higher resolution through an increase in the number of bpp. Most displays, however, are limited to 8 bpp. Naive HDR compression methods lead to a loss of the rich information contained in those HDR images. In this paper, tone mapping algorithms for thermal infrared images with 16 bpp are investigated that can preserve this information. An optimized multi-scale Retinex algorithm sets the baseline. This algorithm is then approximated with a deep learning approach based on the popular U-Net architecture. The remaining noise in the images after tone mapping is reduced implicitly by utilizing a self-supervised deep learning approach that can be jointly trained with the tone mapping approach in a multi-task learning scheme. Further discussions are provided on denoising and deflickering for thermal infrared video enhancement in the context of tone mapping. Extensive experiments on the public FLIR ADAS Dataset prove the effectiveness of our proposed method in comparison with the state-of-the-art.
A Framework for Benchmarking Real-Time Embedded Object Detection
Apr 23, 2023Object detection is one of the key tasks in many applications of computer vision. Deep Neural Networks (DNNs) are undoubtedly a well-suited approach for object detection. However, such DNNs need highly adapted hardware together with hardware-specific optimization to guarantee high efficiency during inference. This is especially the case when aiming for efficient object detection in video streaming applications on limited hardware such as edge devices. Comparing vendor-specific hardware and related optimization software pipelines in a fair experimental setup is a challenge. In this paper, we propose a framework that uses a host computer with a host software application together with a light-weight interface based on the Message Queuing Telemetry Transport (MQTT) protocol. Various different target devices with target apps can be connected via MQTT with this host computer. With well-defined and standardized MQTT messages, object detection results can be reported to the host computer, where the results are evaluated without harming or influencing the processing on the device. With this quite generic framework, we can measure the object detection performance, the runtime, and the energy efficiency at the same time. The effectiveness of this framework is demonstrated in multiple experiments that offer deep insights into the optimization of DNNs.
* Proceedings of the DAGM German Conference on Pattern Recognition (GCPR) 2022
Anchor-free Small-scale Multispectral Pedestrian Detection
Aug 20, 2020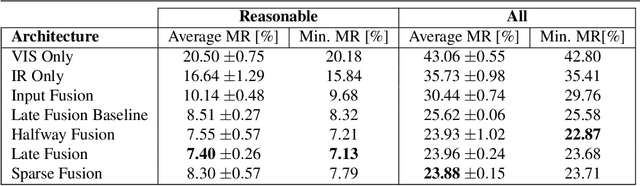

Multispectral images consisting of aligned visual-optical (VIS) and thermal infrared (IR) image pairs are well-suited for practical applications like autonomous driving or visual surveillance. Such data can be used to increase the performance of pedestrian detection especially for weakly illuminated, small-scaled, or partially occluded instances. The current state-of-the-art is based on variants of Faster R-CNN and thus passes through two stages: a proposal generator network with handcrafted anchor boxes for object localization and a classification network for verifying the object category. In this paper we propose a method for effective and efficient multispectral fusion of the two modalities in an adapted single-stage anchor-free base architecture. We aim at learning pedestrian representations based on object center and scale rather than direct bounding box predictions. In this way, we can both simplify the network architecture and achieve higher detection performance, especially for pedestrians under occlusion or at low object resolution. In addition, we provide a study on well-suited multispectral data augmentation techniques that improve the commonly used augmentations. The results show our method's effectiveness in detecting small-scaled pedestrians. We achieve 5.68% log-average miss rate in comparison to the best current state-of-the-art of 7.49% (25% improvement) on the challenging KAIST Multispectral Pedestrian Detection Benchmark. Code: https://github.com/HensoldtOptronicsCV/MultispectralPedestrianDetection
Generalization ability of region proposal networks for multispectral person detection
May 07, 2019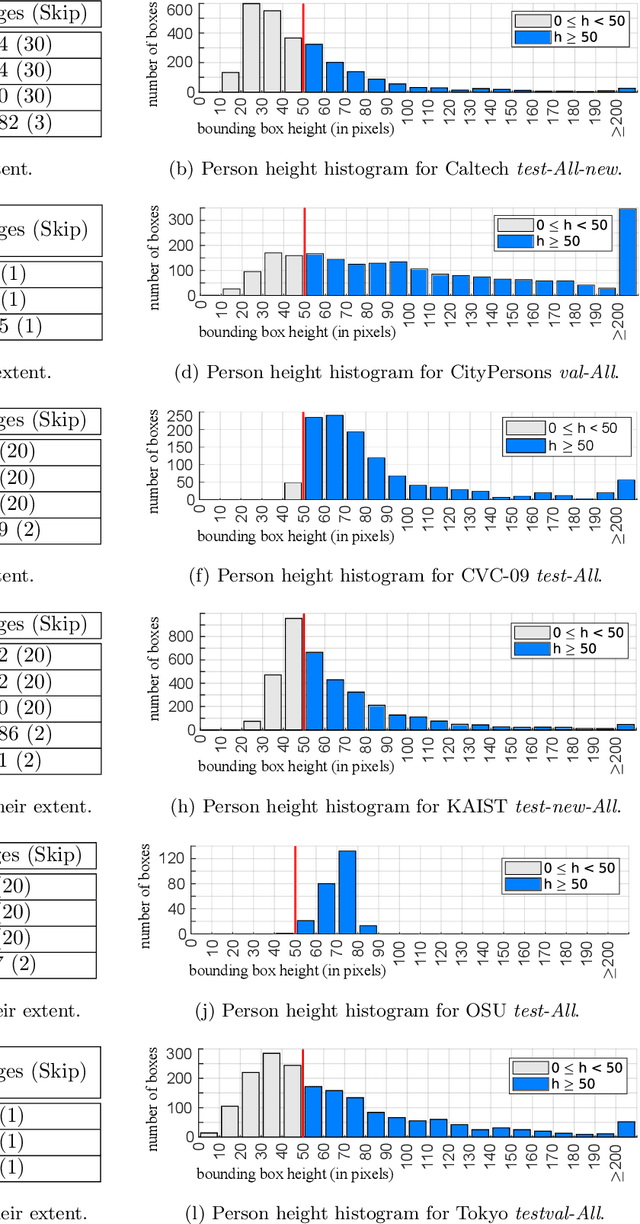



Multispectral person detection aims at automatically localizing humans in images that consist of multiple spectral bands. Usually, the visual-optical (VIS) and the thermal infrared (IR) spectra are combined to achieve higher robustness for person detection especially in insufficiently illuminated scenes. This paper focuses on analyzing existing detection approaches for their generalization ability. Generalization is a key feature for machine learning based detection algorithms that are supposed to perform well across different datasets. Inspired by recent literature regarding person detection in the VIS spectrum, we perform a cross-validation study to empirically determine the most promising dataset to train a well-generalizing detector. Therefore, we pick one reference Deep Convolutional Neural Network (DCNN) architecture and three different multispectral datasets. The Region Proposal Network (RPN) originally introduced for object detection within the popular Faster R-CNN is chosen as a reference DCNN. The reason is that a stand-alone RPN is able to serve as a competitive detector for two-class problems such as person detection. Furthermore, current state-of-the-art approaches initially apply an RPN followed by individual classifiers. The three considered datasets are the KAIST Multispectral Pedestrian Benchmark including recently published improved annotations for training and testing, the Tokyo Multi-spectral Semantic Segmentation dataset, and the OSU Color-Thermal dataset including recently released annotations. The experimental results show that the KAIST Multispectral Pedestrian Benchmark with its improved annotations provides the best basis to train a DCNN with good generalization ability compared to the other two multispectral datasets. On average, this detection model achieves a log-average Miss Rate (MR) of 29.74 % evaluated on the reasonable test subsets of the three datasets.