 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEthical Considerations for the Military Use of Artificial Intelligence in Visual Reconnaissance
Feb 05, 2025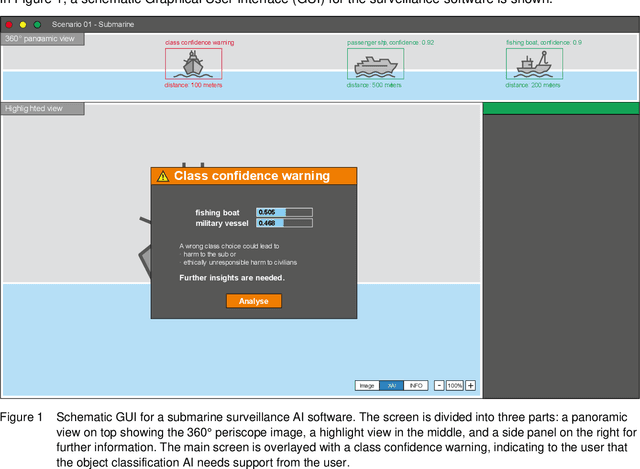
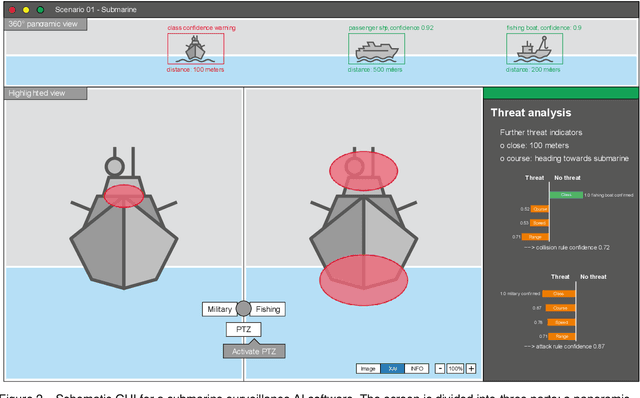
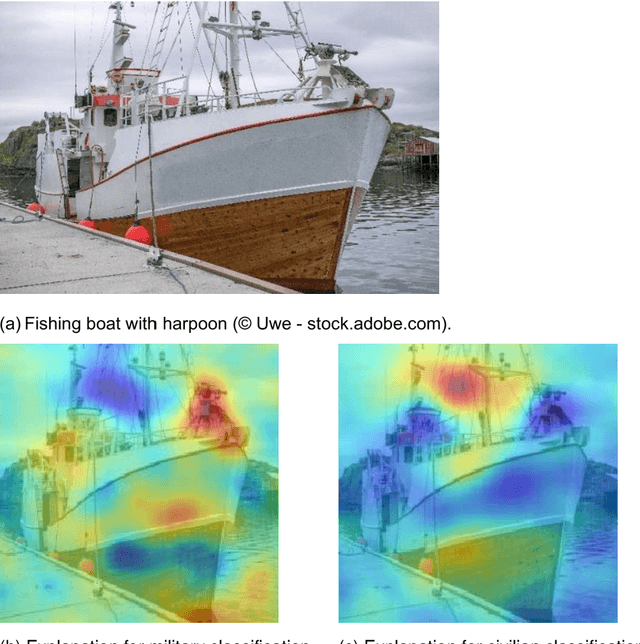
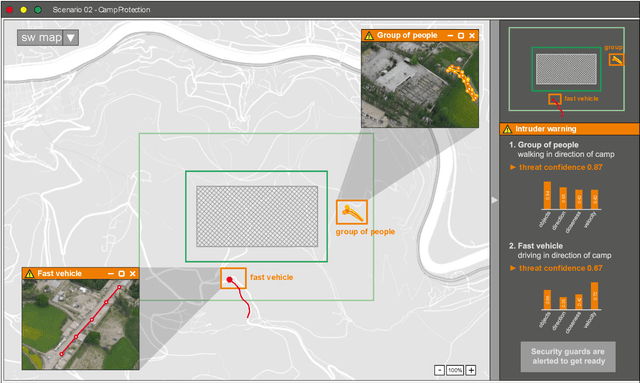
This white paper underscores the critical importance of responsibly deploying Artificial Intelligence (AI) in military contexts, emphasizing a commitment to ethical and legal standards. The evolving role of AI in the military goes beyond mere technical applications, necessitating a framework grounded in ethical principles. The discussion within the paper delves into ethical AI principles, particularly focusing on the Fairness, Accountability, Transparency, and Ethics (FATE) guidelines. Noteworthy considerations encompass transparency, justice, non-maleficence, and responsibility. Importantly, the paper extends its examination to military-specific ethical considerations, drawing insights from the Just War theory and principles established by prominent entities. In addition to the identified principles, the paper introduces further ethical considerations specifically tailored for military AI applications. These include traceability, proportionality, governability, responsibility, and reliability. The application of these ethical principles is discussed on the basis of three use cases in the domains of sea, air, and land. Methods of automated sensor data analysis, eXplainable AI (XAI), and intuitive user experience are utilized to specify the use cases close to real-world scenarios. This comprehensive approach to ethical considerations in military AI reflects a commitment to aligning technological advancements with established ethical frameworks. It recognizes the need for a balance between leveraging AI's potential benefits in military operations while upholding moral and legal standards. The inclusion of these ethical principles serves as a foundation for responsible and accountable use of AI in the complex and dynamic landscape of military scenarios.
SkyScapes -- Fine-Grained Semantic Understanding of Aerial Scenes
Jul 12, 2020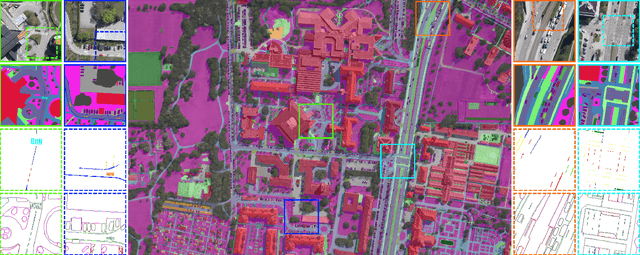
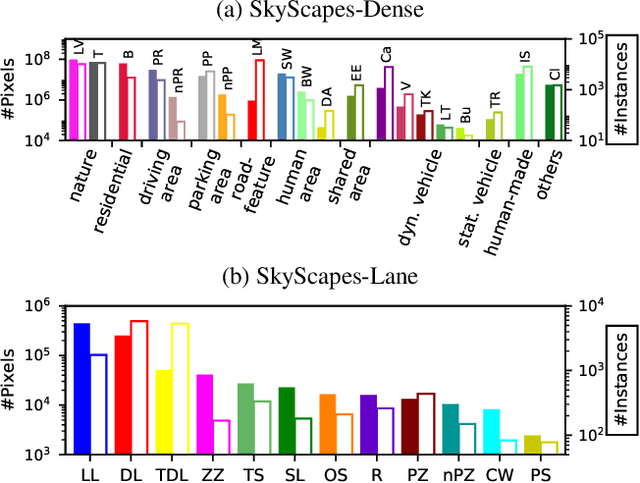
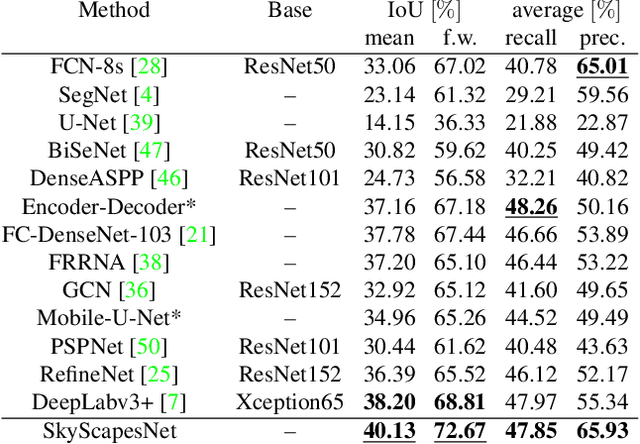
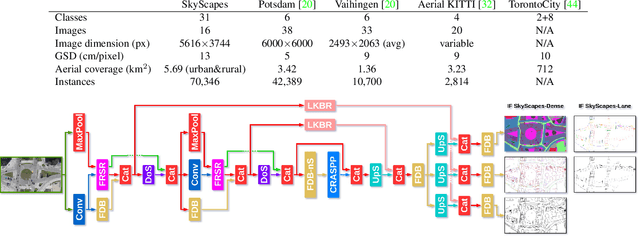
Understanding the complex urban infrastructure with centimeter-level accuracy is essential for many applications from autonomous driving to mapping, infrastructure monitoring, and urban management. Aerial images provide valuable information over a large area instantaneously; nevertheless, no current dataset captures the complexity of aerial scenes at the level of granularity required by real-world applications. To address this, we introduce SkyScapes, an aerial image dataset with highly-accurate, fine-grained annotations for pixel-level semantic labeling. SkyScapes provides annotations for 31 semantic categories ranging from large structures, such as buildings, roads and vegetation, to fine details, such as 12 (sub-)categories of lane markings. We have defined two main tasks on this dataset: dense semantic segmentation and multi-class lane-marking prediction. We carry out extensive experiments to evaluate state-of-the-art segmentation methods on SkyScapes. Existing methods struggle to deal with the wide range of classes, object sizes, scales, and fine details present. We therefore propose a novel multi-task model, which incorporates semantic edge detection and is better tuned for feature extraction from a wide range of scales. This model achieves notable improvements over the baselines in region outlines and level of detail on both tasks.
Human Pose Estimation for Real-World Crowded Scenarios
Jul 16, 2019
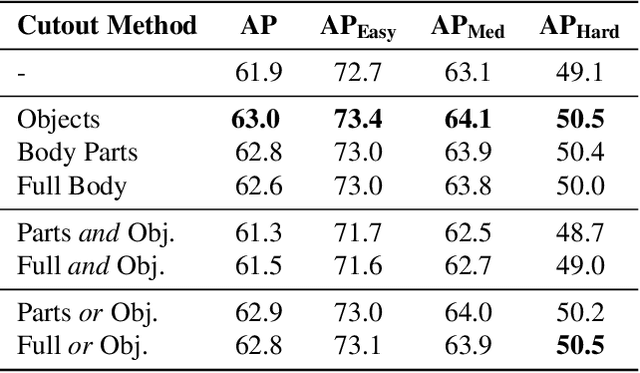

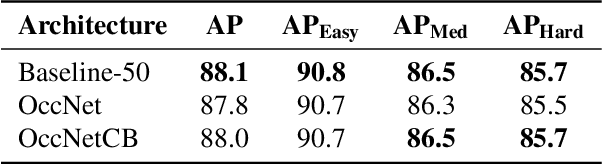
Human pose estimation has recently made significant progress with the adoption of deep convolutional neural networks. Its many applications have attracted tremendous interest in recent years. However, many practical applications require pose estimation for human crowds, which still is a rarely addressed problem. In this work, we explore methods to optimize pose estimation for human crowds, focusing on challenges introduced with dense crowds, such as occlusions, people in close proximity to each other, and partial visibility of people. In order to address these challenges, we evaluate three aspects of a pose detection approach: i) a data augmentation method to introduce robustness to occlusions, ii) the explicit detection of occluded body parts, and iii) the use of the synthetic generated datasets. The first approach to improve the accuracy in crowded scenarios is to generate occlusions at training time using person and object cutouts from the object recognition dataset COCO (Common Objects in Context). Furthermore, the synthetically generated dataset JTA (Joint Track Auto) is evaluated for the use in real-world crowd applications. In order to overcome the transfer gap of JTA originating from a low pose variety and less dense crowds, an extension dataset is created to ease the use for real-world applications. Additionally, the occlusion flags provided with JTA are utilized to train a model, which explicitly distinguishes between occluded and visible body parts in two distinct branches. The combination of the proposed additions to the baseline method help to improve the overall accuracy by 4.7% AP and thereby provide comparable results to current state-of-the-art approaches on the respective dataset.
A Systematic Evaluation of Recent Deep Learning Architectures for Fine-Grained Vehicle Classification
Jun 08, 2018Fine-grained vehicle classification is the task of classifying make, model, and year of a vehicle. This is a very challenging task, because vehicles of different types but similar color and viewpoint can often look much more similar than vehicles of same type but differing color and viewpoint. Vehicle make, model, and year in com- bination with vehicle color - are of importance in several applications such as vehicle search, re-identification, tracking, and traffic analysis. In this work we investigate the suitability of several recent landmark convolutional neural network (CNN) architectures, which have shown top results on large scale image classification tasks, for the task of fine-grained classification of vehicles. We compare the performance of the networks VGG16, several ResNets, Inception architectures, the recent DenseNets, and MobileNet. For classification we use the Stanford Cars-196 dataset which features 196 different types of vehicles. We investigate several aspects of CNN training, such as data augmentation and training from scratch vs. fine-tuning. Importantly, we introduce no aspects in the architectures or training process which are specific to vehicle classification. Our final model achieves a state-of-the-art classification accuracy of 94.6% outperforming all related works, even approaches which are specifically tailored for the task, e.g. by including vehicle part detections.
A Pose-Sensitive Embedding for Person Re-Identification with Expanded Cross Neighborhood Re-Ranking
Apr 02, 2018
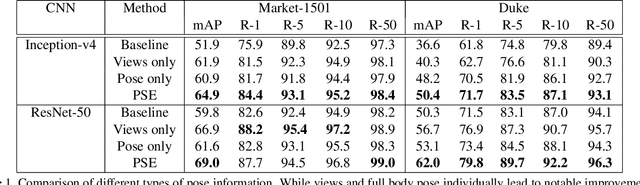
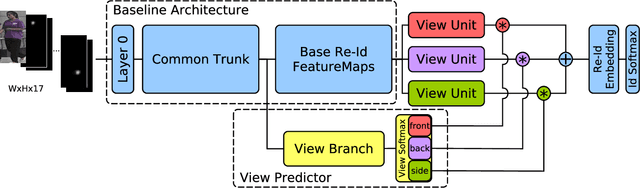
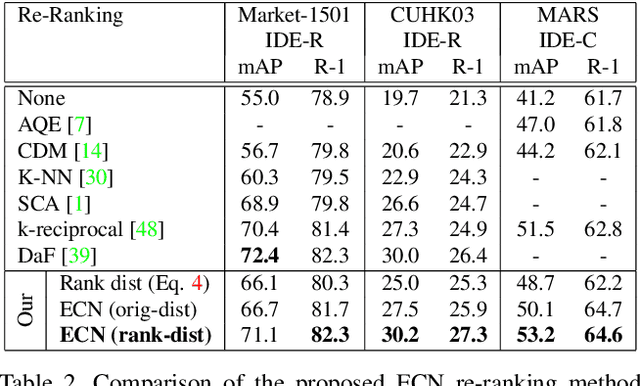
Person re identification is a challenging retrieval task that requires matching a person's acquired image across non overlapping camera views. In this paper we propose an effective approach that incorporates both the fine and coarse pose information of the person to learn a discriminative embedding. In contrast to the recent direction of explicitly modeling body parts or correcting for misalignment based on these, we show that a rather straightforward inclusion of acquired camera view and/or the detected joint locations into a convolutional neural network helps to learn a very effective representation. To increase retrieval performance, re-ranking techniques based on computed distances have recently gained much attention. We propose a new unsupervised and automatic re-ranking framework that achieves state-of-the-art re-ranking performance. We show that in contrast to the current state-of-the-art re-ranking methods our approach does not require to compute new rank lists for each image pair (e.g., based on reciprocal neighbors) and performs well by using simple direct rank list based comparison or even by just using the already computed euclidean distances between the images. We show that both our learned representation and our re-ranking method achieve state-of-the-art performance on a number of challenging surveillance image and video datasets. The code is available online at: https://github.com/pse-ecn/pose-sensitive-embedding
Deep Learning Prototype Domains for Person Re-Identification
Sep 19, 2017
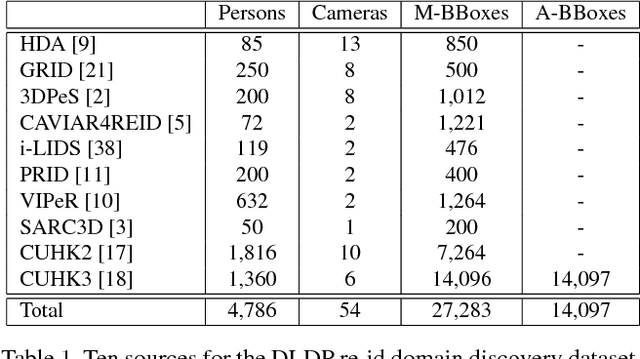
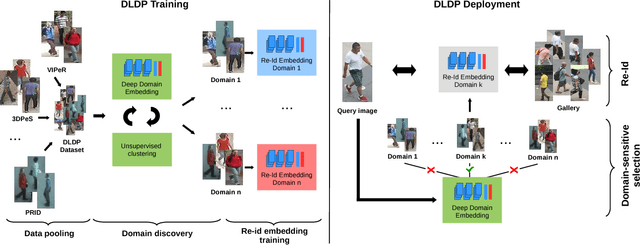
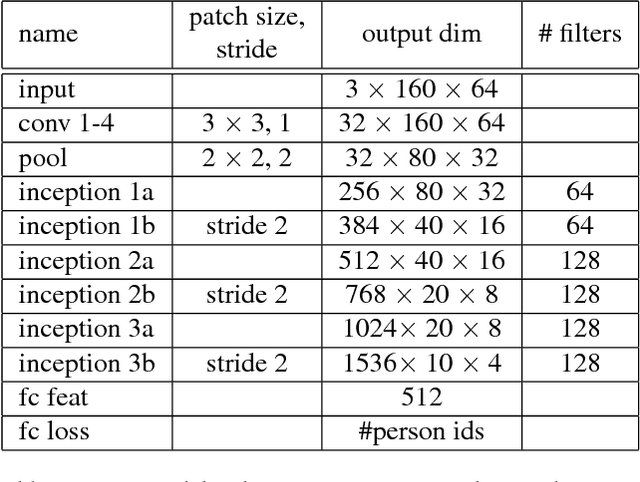
Person re-identification (re-id) is the task of matching multiple occurrences of the same person from different cameras, poses, lighting conditions, and a multitude of other factors which alter the visual appearance. Typically, this is achieved by learning either optimal features or matching metrics which are adapted to specific pairs of camera views dictated by the pairwise labelled training datasets. In this work, we formulate a deep learning based novel approach to automatic prototype-domain discovery for domain perceptive (adaptive) person re-id (rather than camera pair specific learning) for any camera views scalable to new unseen scenes without training data. We learn a separate re-id model for each of the discovered prototype-domains and during model deployment, use the person probe image to select automatically the model of the closest prototype domain. Our approach requires neither supervised nor unsupervised domain adaptation learning, i.e. no data available from the target domains. We evaluate extensively our model under realistic re-id conditions using automatically detected bounding boxes with low-resolution and partial occlusion. We show that our approach outperforms most of the state-of-the-art supervised and unsupervised methods on the latest CUHK-SYSU and PRW benchmarks.
Deep View-Sensitive Pedestrian Attribute Inference in an end-to-end Model
Jul 19, 2017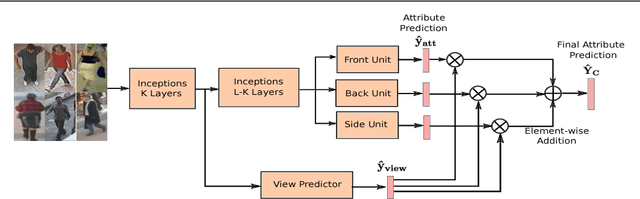
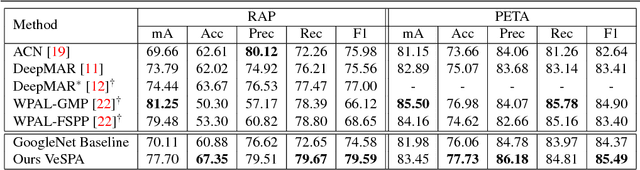


Pedestrian attribute inference is a demanding problem in visual surveillance that can facilitate person retrieval, search and indexing. To exploit semantic relations between attributes, recent research treats it as a multi-label image classification task. The visual cues hinting at attributes can be strongly localized and inference of person attributes such as hair, backpack, shorts, etc., are highly dependent on the acquired view of the pedestrian. In this paper we assert this dependence in an end-to-end learning framework and show that a view-sensitive attribute inference is able to learn better attribute predictions. Our proposed model jointly predicts the coarse pose (view) of the pedestrian and learns specialized view-specific multi-label attribute predictions. We show in an extensive evaluation on three challenging datasets (PETA, RAP and WIDER) that our proposed end-to-end view-aware attribute prediction model provides competitive performance and improves on the published state-of-the-art on these datasets.