 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkyScapes -- Fine-Grained Semantic Understanding of Aerial Scenes
Jul 12, 2020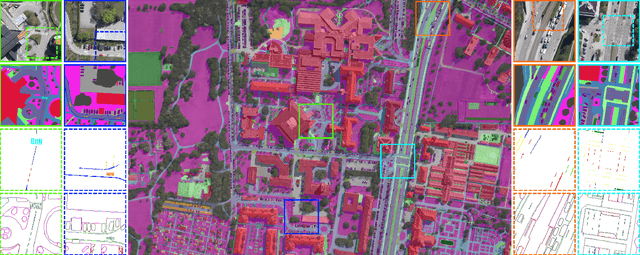
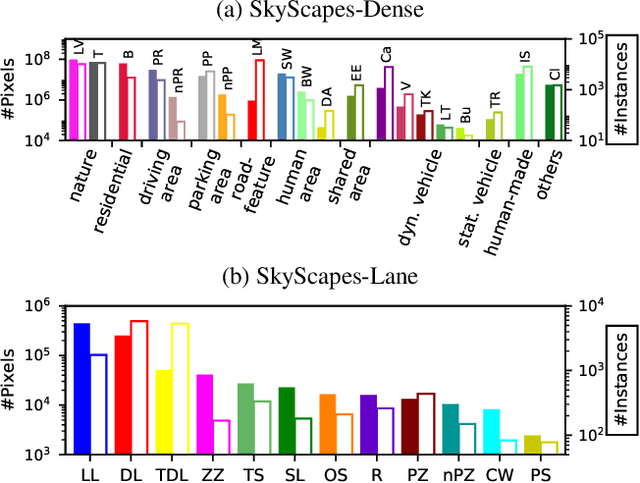
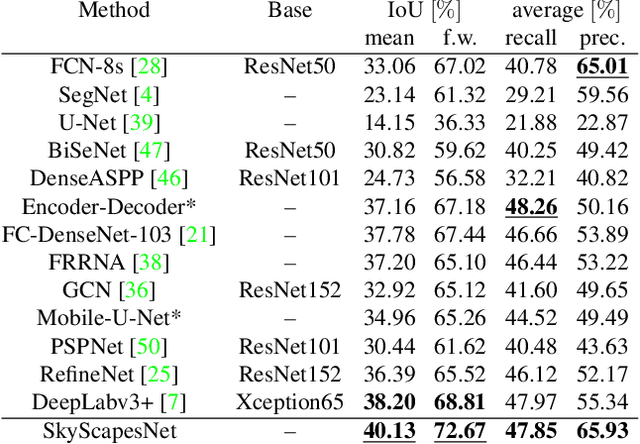
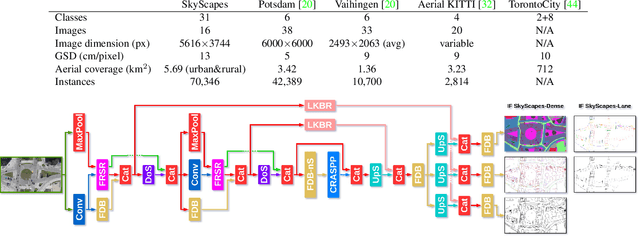
Understanding the complex urban infrastructure with centimeter-level accuracy is essential for many applications from autonomous driving to mapping, infrastructure monitoring, and urban management. Aerial images provide valuable information over a large area instantaneously; nevertheless, no current dataset captures the complexity of aerial scenes at the level of granularity required by real-world applications. To address this, we introduce SkyScapes, an aerial image dataset with highly-accurate, fine-grained annotations for pixel-level semantic labeling. SkyScapes provides annotations for 31 semantic categories ranging from large structures, such as buildings, roads and vegetation, to fine details, such as 12 (sub-)categories of lane markings. We have defined two main tasks on this dataset: dense semantic segmentation and multi-class lane-marking prediction. We carry out extensive experiments to evaluate state-of-the-art segmentation methods on SkyScapes. Existing methods struggle to deal with the wide range of classes, object sizes, scales, and fine details present. We therefore propose a novel multi-task model, which incorporates semantic edge detection and is better tuned for feature extraction from a wide range of scales. This model achieves notable improvements over the baselines in region outlines and level of detail on both tasks.
Towards Multi-class Object Detection in Unconstrained Remote Sensing Imagery
Nov 01, 2018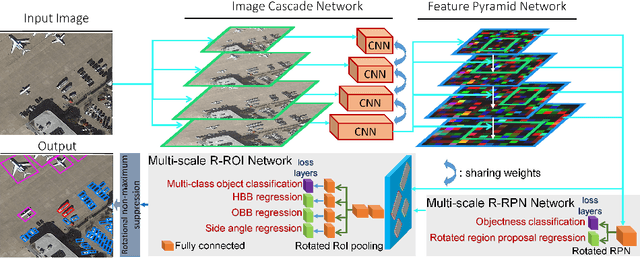
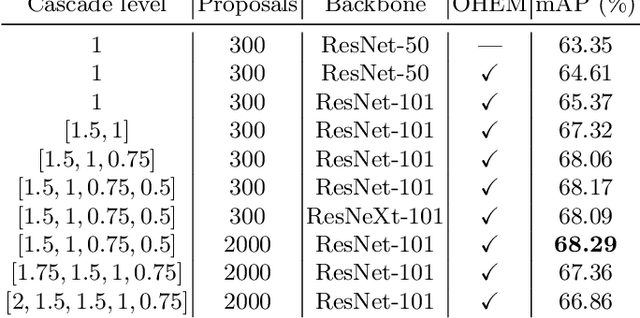
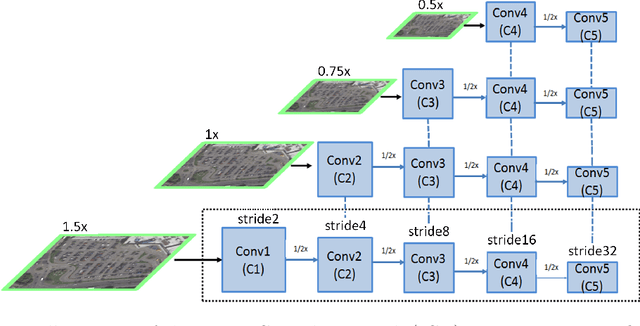

Automatic multi-class object detection in remote sensing images in unconstrained scenarios is of high interest for several applications including traffic monitoring and disaster management. The huge variation in object scale, orientation, category, and complex backgrounds, as well as the different camera sensors pose great challenges for current algorithms. In this work, we propose a new method consisting of a novel joint image cascade and feature pyramid network with multi-size convolution kernels to extract multi-scale strong and weak semantic features. These features are fed into rotation-based region proposal and region of interest networks to produce object detections. Finally, rotational non-maximum suppression is applied to remove redundant detections. During training, we minimize joint horizontal and oriented bounding box loss functions, as well as a novel loss that enforces oriented boxes to be rectangular. Our method achieves 68.16% mAP on horizontal and 72.45% mAP on oriented bounding box detection tasks on the challenging DOTA dataset, outperforming all published methods by a large margin (+6% and +12% absolute improvement, respectively). Furthermore, it generalizes to two other datasets, NWPU VHR-10 and UCAS-AOD, and achieves competitive results with the baselines even when trained on DOTA. Our method can be deployed in multi-class object detection applications, regardless of the image and object scales and orientations, making it a great choice for unconstrained aerial and satellite imagery.
End-to-End Saliency Mapping via Probability Distribution Prediction
Apr 05, 2018

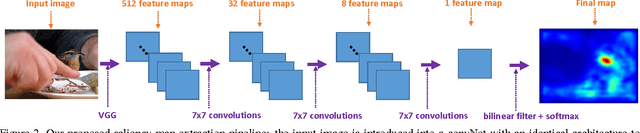
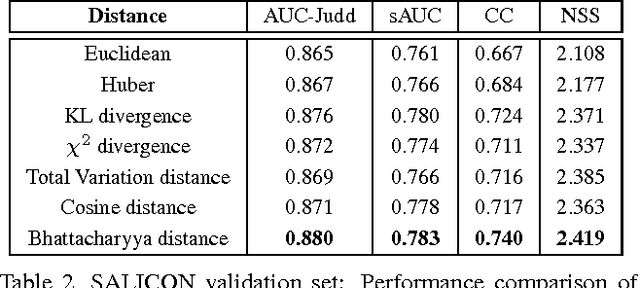
Most saliency estimation methods aim to explicitly model low-level conspicuity cues such as edges or blobs and may additionally incorporate top-down cues using face or text detection. Data-driven methods for training saliency models using eye-fixation data are increasingly popular, particularly with the introduction of large-scale datasets and deep architectures. However, current methods in this latter paradigm use loss functions designed for classification or regression tasks whereas saliency estimation is evaluated on topographical maps. In this work, we introduce a new saliency map model which formulates a map as a generalized Bernoulli distribution. We then train a deep architecture to predict such maps using novel loss functions which pair the softmax activation function with measures designed to compute distances between probability distributions. We show in extensive experiments the effectiveness of such loss functions over standard ones on four public benchmark datasets, and demonstrate improved performance over state-of-the-art saliency methods.
Sympathy for the Details: Dense Trajectories and Hybrid Classification Architectures for Action Recognition
Aug 25, 2016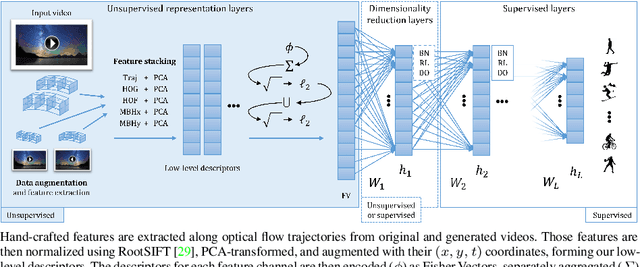

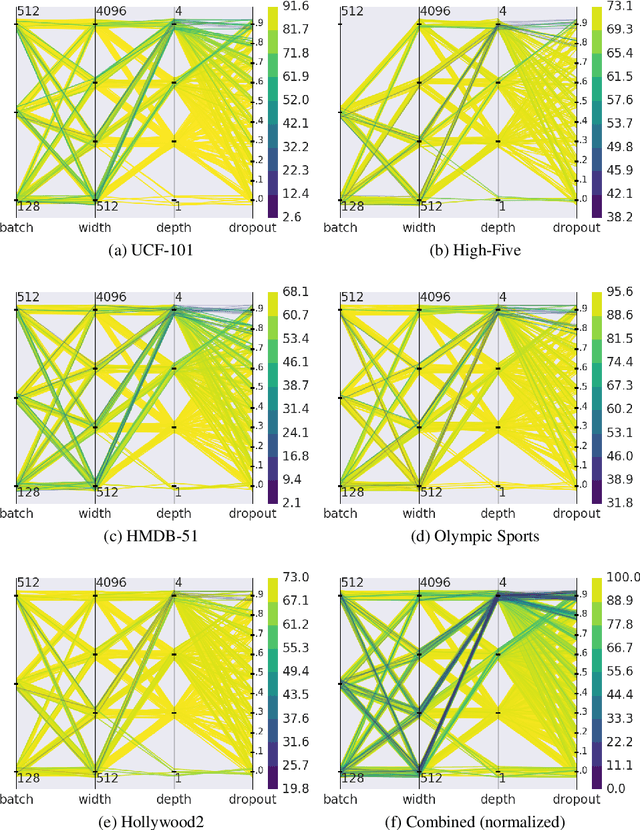
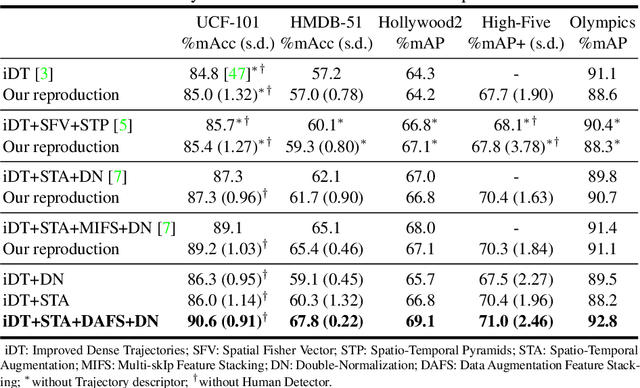
Action recognition in videos is a challenging task due to the complexity of the spatio-temporal patterns to model and the difficulty to acquire and learn on large quantities of video data. Deep learning, although a breakthrough for image classification and showing promise for videos, has still not clearly superseded action recognition methods using hand-crafted features, even when training on massive datasets. In this paper, we introduce hybrid video classification architectures based on carefully designed unsupervised representations of hand-crafted spatio-temporal features classified by supervised deep networks. As we show in our experiments on five popular benchmarks for action recognition, our hybrid model combines the best of both worlds: it is data efficient (trained on 150 to 10000 short clips) and yet improves significantly on the state of the art, including recent deep models trained on millions of manually labelled images and videos.
Virtual Worlds as Proxy for Multi-Object Tracking Analysis
May 20, 2016



Modern computer vision algorithms typically require expensive data acquisition and accurate manual labeling. In this work, we instead leverage the recent progress in computer graphics to generate fully labeled, dynamic, and photo-realistic proxy virtual worlds. We propose an efficient real-to-virtual world cloning method, and validate our approach by building and publicly releasing a new video dataset, called Virtual KITTI (see http://www.xrce.xerox.com/Research-Development/Computer-Vision/Proxy-Virtual-Worlds), automatically labeled with accurate ground truth for object detection, tracking, scene and instance segmentation, depth, and optical flow. We provide quantitative experimental evidence suggesting that (i) modern deep learning algorithms pre-trained on real data behave similarly in real and virtual worlds, and (ii) pre-training on virtual data improves performance. As the gap between real and virtual worlds is small, virtual worlds enable measuring the impact of various weather and imaging conditions on recognition performance, all other things being equal. We show these factors may affect drastically otherwise high-performing deep models for tracking.
Online Domain Adaptation for Multi-Object Tracking
Aug 04, 2015



Automatically detecting, labeling, and tracking objects in videos depends first and foremost on accurate category-level object detectors. These might, however, not always be available in practice, as acquiring high-quality large scale labeled training datasets is either too costly or impractical for all possible real-world application scenarios. A scalable solution consists in re-using object detectors pre-trained on generic datasets. This work is the first to investigate the problem of on-line domain adaptation of object detectors for causal multi-object tracking (MOT). We propose to alleviate the dataset bias by adapting detectors from category to instances, and back: (i) we jointly learn all target models by adapting them from the pre-trained one, and (ii) we also adapt the pre-trained model on-line. We introduce an on-line multi-task learning algorithm to efficiently share parameters and reduce drift, while gradually improving recall. Our approach is applicable to any linear object detector, and we evaluate both cheap "mini-Fisher Vectors" and expensive "off-the-shelf" ConvNet features. We quantitatively measure the benefit of our domain adaptation strategy on the KITTI tracking benchmark and on a new dataset (PASCAL-to-KITTI) we introduce to study the domain mismatch problem in MOT.