 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Human Action Videos by Coupling 3D Game Engines and Probabilistic Graphical Models
Oct 12, 2019



Deep video action recognition models have been highly successful in recent years but require large quantities of manually annotated data, which are expensive and laborious to obtain. In this work, we investigate the generation of synthetic training data for video action recognition, as synthetic data have been successfully used to supervise models for a variety of other computer vision tasks. We propose an interpretable parametric generative model of human action videos that relies on procedural generation, physics models and other components of modern game engines. With this model we generate a diverse, realistic, and physically plausible dataset of human action videos, called PHAV for "Procedural Human Action Videos". PHAV contains a total of 39,982 videos, with more than 1,000 examples for each of 35 action categories. Our video generation approach is not limited to existing motion capture sequences: 14 of these 35 categories are procedurally defined synthetic actions. In addition, each video is represented with 6 different data modalities, including RGB, optical flow and pixel-level semantic labels. These modalities are generated almost simultaneously using the Multiple Render Targets feature of modern GPUs. In order to leverage PHAV, we introduce a deep multi-task (i.e. that considers action classes from multiple datasets) representation learning architecture that is able to simultaneously learn from synthetic and real video datasets, even when their action categories differ. Our experiments on the UCF-101 and HMDB-51 benchmarks suggest that combining our large set of synthetic videos with small real-world datasets can boost recognition performance. Our approach also significantly outperforms video representations produced by fine-tuning state-of-the-art unsupervised generative models of videos.
Procedural Generation of Videos to Train Deep Action Recognition Networks
Jul 19, 2017



Deep learning for human action recognition in videos is making significant progress, but is slowed down by its dependency on expensive manual labeling of large video collections. In this work, we investigate the generation of synthetic training data for action recognition, as it has recently shown promising results for a variety of other computer vision tasks. We propose an interpretable parametric generative model of human action videos that relies on procedural generation and other computer graphics techniques of modern game engines. We generate a diverse, realistic, and physically plausible dataset of human action videos, called PHAV for "Procedural Human Action Videos". It contains a total of 39,982 videos, with more than 1,000 examples for each action of 35 categories. Our approach is not limited to existing motion capture sequences, and we procedurally define 14 synthetic actions. We introduce a deep multi-task representation learning architecture to mix synthetic and real videos, even if the action categories differ. Our experiments on the UCF101 and HMDB51 benchmarks suggest that combining our large set of synthetic videos with small real-world datasets can boost recognition performance, significantly outperforming fine-tuning state-of-the-art unsupervised generative models of videos.
Sympathy for the Details: Dense Trajectories and Hybrid Classification Architectures for Action Recognition
Aug 25, 2016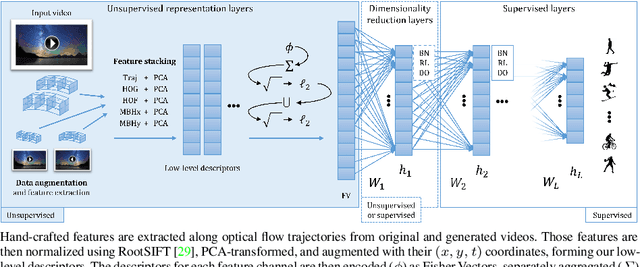

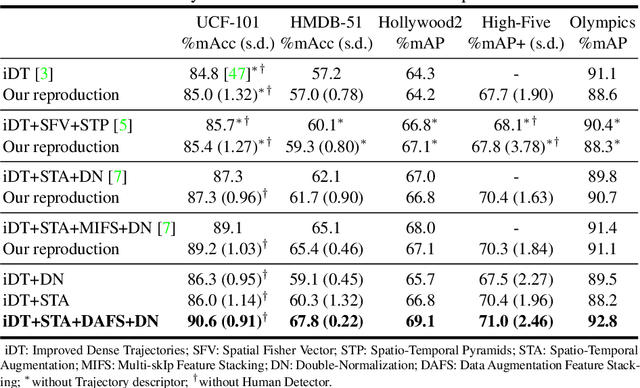
Action recognition in videos is a challenging task due to the complexity of the spatio-temporal patterns to model and the difficulty to acquire and learn on large quantities of video data. Deep learning, although a breakthrough for image classification and showing promise for videos, has still not clearly superseded action recognition methods using hand-crafted features, even when training on massive datasets. In this paper, we introduce hybrid video classification architectures based on carefully designed unsupervised representations of hand-crafted spatio-temporal features classified by supervised deep networks. As we show in our experiments on five popular benchmarks for action recognition, our hybrid model combines the best of both worlds: it is data efficient (trained on 150 to 10000 short clips) and yet improves significantly on the state of the art, including recent deep models trained on millions of manually labelled images and videos.
Recognizing Static Signs from the Brazilian Sign Language: Comparing Large-Margin Decision Directed Acyclic Graphs, Voting Support Vector Machines and Artificial Neural Networks
Oct 28, 2012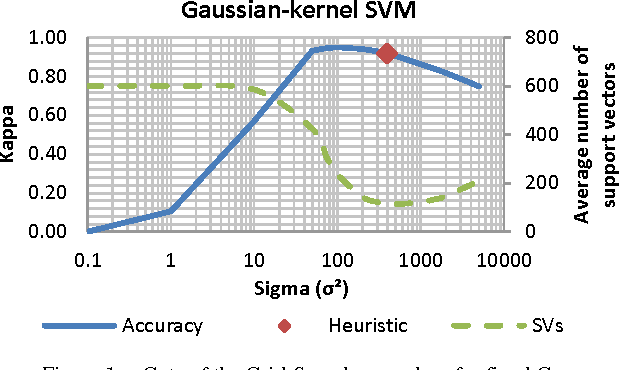
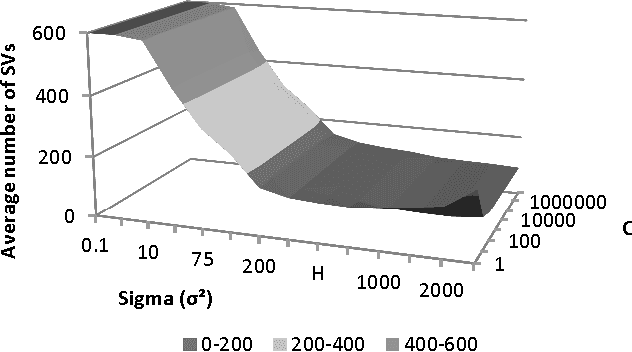
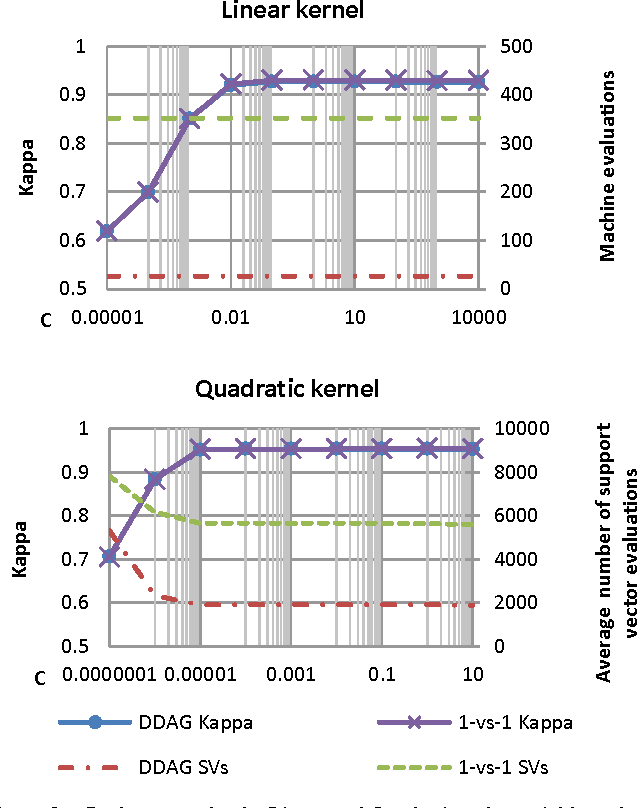
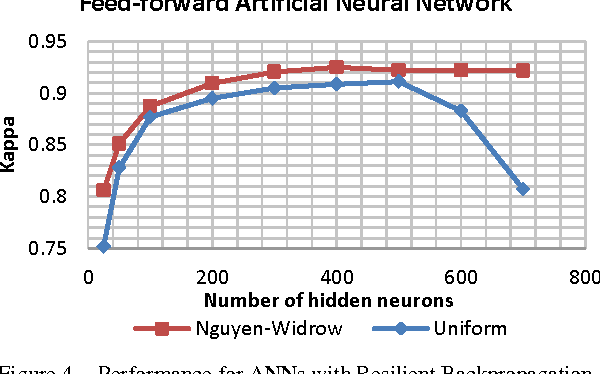
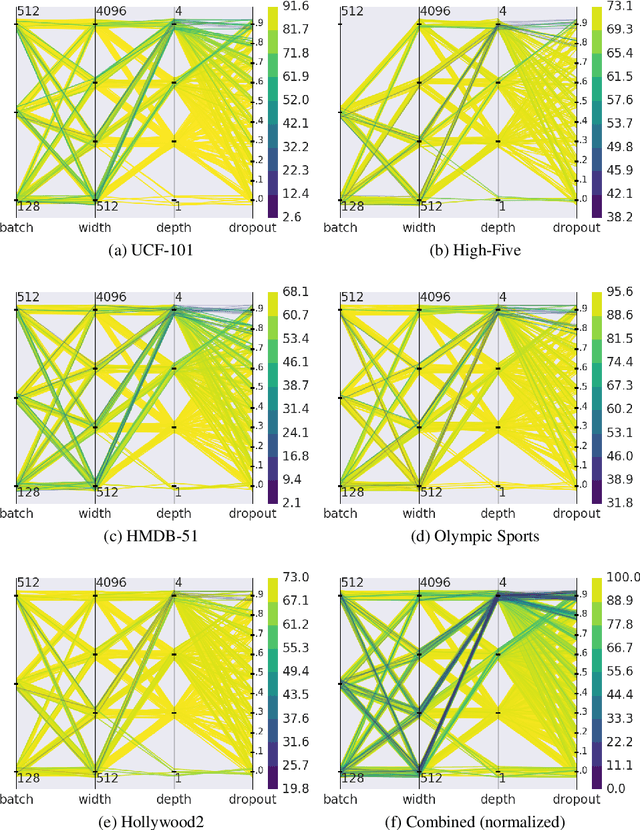
In this paper, we explore and detail our experiments in a high-dimensionality, multi-class image classification problem often found in the automatic recognition of Sign Languages. Here, our efforts are directed towards comparing the characteristics, advantages and drawbacks of creating and training Support Vector Machines disposed in a Directed Acyclic Graph and Artificial Neural Networks to classify signs from the Brazilian Sign Language (LIBRAS). We explore how the different heuristics, hyperparameters and multi-class decision schemes affect the performance, efficiency and ease of use for each classifier. We provide hyperparameter surface maps capturing accuracy and efficiency, comparisons between DDAGs and 1-vs-1 SVMs, and effects of heuristics when training ANNs with Resilient Backpropagation. We report statistically significant results using Cohen's Kappa statistic for contingency tables.