 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Human Action Videos by Coupling 3D Game Engines and Probabilistic Graphical Models
Oct 12, 2019



Deep video action recognition models have been highly successful in recent years but require large quantities of manually annotated data, which are expensive and laborious to obtain. In this work, we investigate the generation of synthetic training data for video action recognition, as synthetic data have been successfully used to supervise models for a variety of other computer vision tasks. We propose an interpretable parametric generative model of human action videos that relies on procedural generation, physics models and other components of modern game engines. With this model we generate a diverse, realistic, and physically plausible dataset of human action videos, called PHAV for "Procedural Human Action Videos". PHAV contains a total of 39,982 videos, with more than 1,000 examples for each of 35 action categories. Our video generation approach is not limited to existing motion capture sequences: 14 of these 35 categories are procedurally defined synthetic actions. In addition, each video is represented with 6 different data modalities, including RGB, optical flow and pixel-level semantic labels. These modalities are generated almost simultaneously using the Multiple Render Targets feature of modern GPUs. In order to leverage PHAV, we introduce a deep multi-task (i.e. that considers action classes from multiple datasets) representation learning architecture that is able to simultaneously learn from synthetic and real video datasets, even when their action categories differ. Our experiments on the UCF-101 and HMDB-51 benchmarks suggest that combining our large set of synthetic videos with small real-world datasets can boost recognition performance. Our approach also significantly outperforms video representations produced by fine-tuning state-of-the-art unsupervised generative models of videos.
GPU-accelerated real-time stixel computation
Oct 13, 2016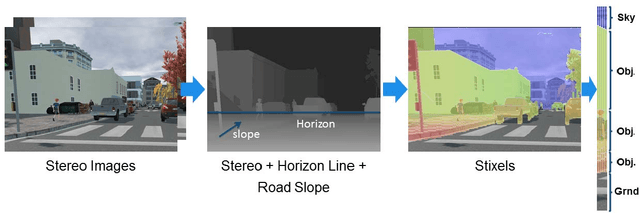

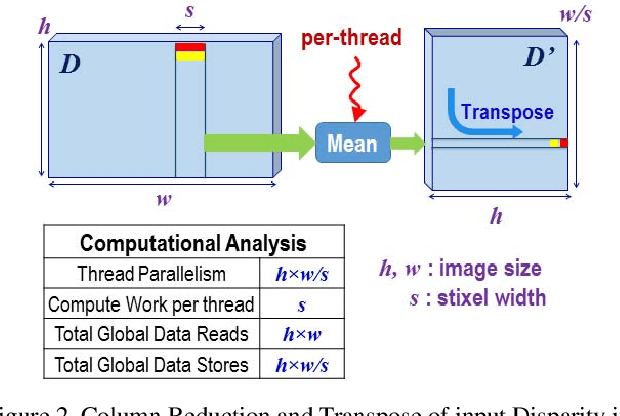
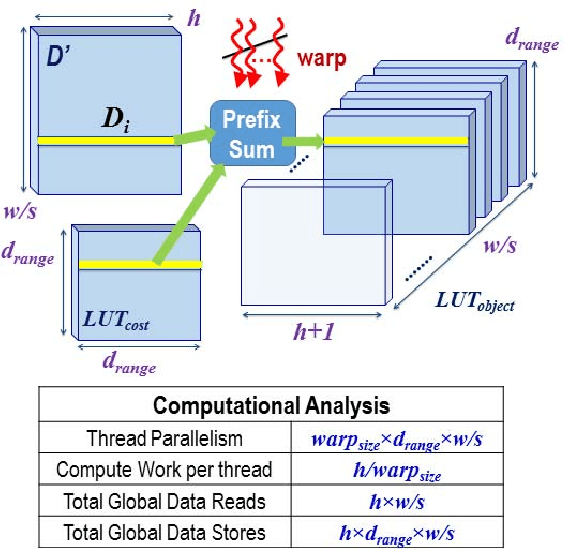
The Stixel World is a medium-level, compact representation of road scenes that abstracts millions of disparity pixels into hundreds or thousands of stixels. The goal of this work is to implement and evaluate a complete multi-stixel estimation pipeline on an embedded, energy-efficient, GPU-accelerated device. This work presents a full GPU-accelerated implementation of stixel estimation that produces reliable results at 26 frames per second (real-time) on the Tegra X1 for disparity images of 1024x440 pixels and stixel widths of 5 pixels, and achieves more than 400 frames per second on a high-end Titan X GPU card.
Embedded real-time stereo estimation via Semi-Global Matching on the GPU
Oct 13, 2016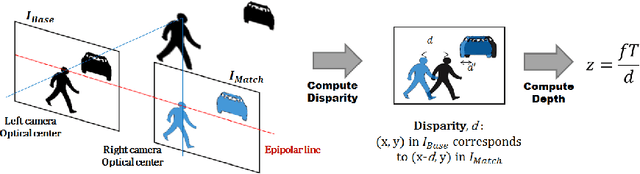
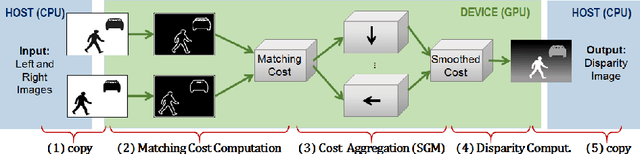
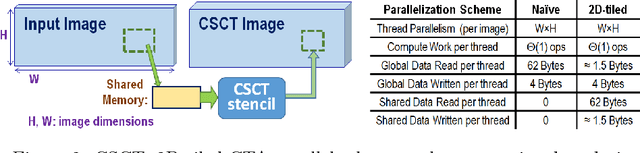
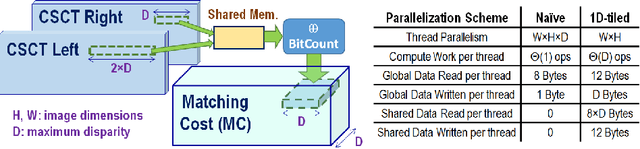
Dense, robust and real-time computation of depth information from stereo-camera systems is a computationally demanding requirement for robotics, advanced driver assistance systems (ADAS) and autonomous vehicles. Semi-Global Matching (SGM) is a widely used algorithm that propagates consistency constraints along several paths across the image. This work presents a real-time system producing reliable disparity estimation results on the new embedded energy-efficient GPU devices. Our design runs on a Tegra X1 at 42 frames per second (fps) for an image size of 640x480, 128 disparity levels, and using 4 path directions for the SGM method.
Sympathy for the Details: Dense Trajectories and Hybrid Classification Architectures for Action Recognition
Aug 25, 2016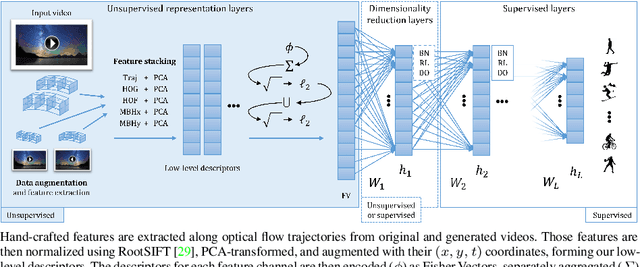

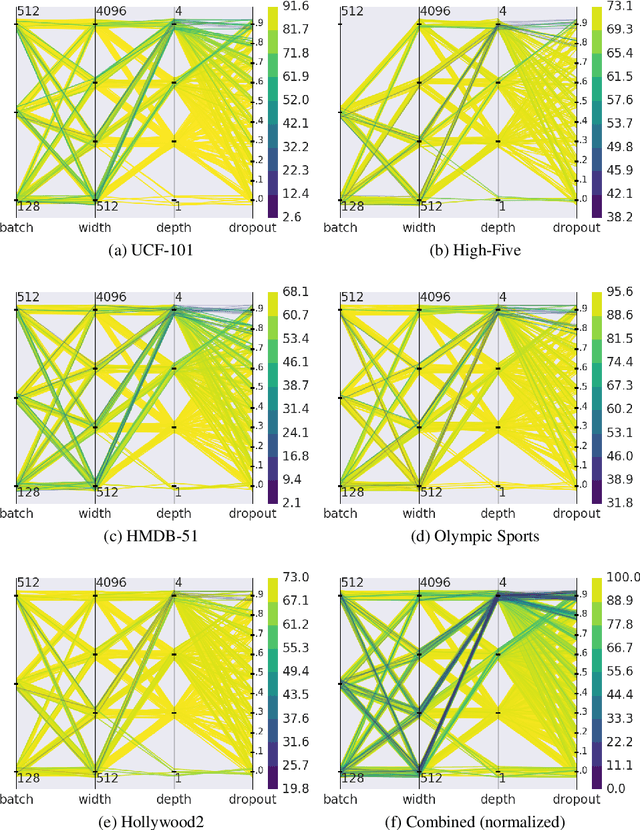
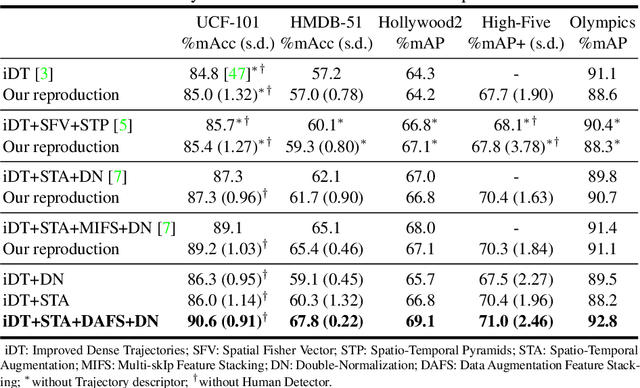
Action recognition in videos is a challenging task due to the complexity of the spatio-temporal patterns to model and the difficulty to acquire and learn on large quantities of video data. Deep learning, although a breakthrough for image classification and showing promise for videos, has still not clearly superseded action recognition methods using hand-crafted features, even when training on massive datasets. In this paper, we introduce hybrid video classification architectures based on carefully designed unsupervised representations of hand-crafted spatio-temporal features classified by supervised deep networks. As we show in our experiments on five popular benchmarks for action recognition, our hybrid model combines the best of both worlds: it is data efficient (trained on 150 to 10000 short clips) and yet improves significantly on the state of the art, including recent deep models trained on millions of manually labelled images and videos.