 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiple Pedestrians and Vehicles Tracking in Aerial Imagery: A Comprehensive Study
Oct 19, 2020
In this paper, we address various challenges in multi-pedestrian and vehicle tracking in high-resolution aerial imagery by intensive evaluation of a number of traditional and Deep Learning based Single- and Multi-Object Tracking methods. We also describe our proposed Deep Learning based Multi-Object Tracking method AerialMPTNet that fuses appearance, temporal, and graphical information using a Siamese Neural Network, a Long Short-Term Memory, and a Graph Convolutional Neural Network module for a more accurate and stable tracking. Moreover, we investigate the influence of the Squeeze-and-Excitation layers and Online Hard Example Mining on the performance of AerialMPTNet. To the best of our knowledge, we are the first in using these two for a regression-based Multi-Object Tracking. Additionally, we studied and compared the L1 and Huber loss functions. In our experiments, we extensively evaluate AerialMPTNet on three aerial Multi-Object Tracking datasets, namely AerialMPT and KIT AIS pedestrian and vehicle datasets. Qualitative and quantitative results show that AerialMPTNet outperforms all previous methods for the pedestrian datasets and achieves competitive results for the vehicle dataset. In addition, Long Short-Term Memory and Graph Convolutional Neural Network modules enhance the tracking performance. Moreover, using Squeeze-and-Excitation and Online Hard Example Mining significantly helps for some cases while degrades the results for other cases. In addition, according to the results, L1 yields better results with respect to Huber loss for most of the scenarios. The presented results provide a deep insight into challenges and opportunities of the aerial Multi-Object Tracking domain, paving the way for future research.
AerialMPTNet: Multi-Pedestrian Tracking in Aerial Imagery Using Temporal and Graphical Features
Jun 27, 2020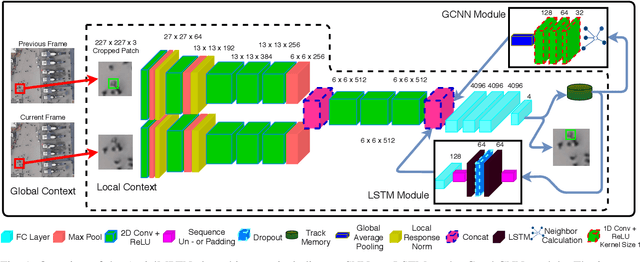

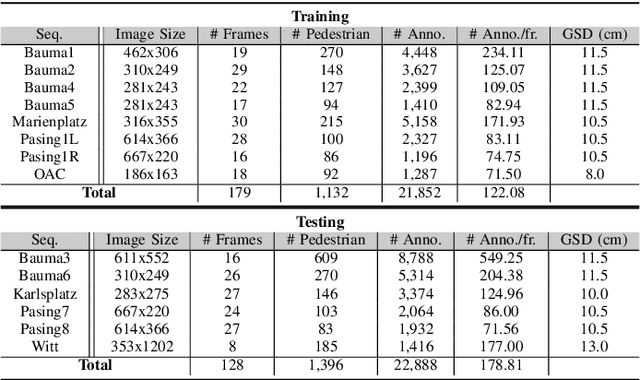

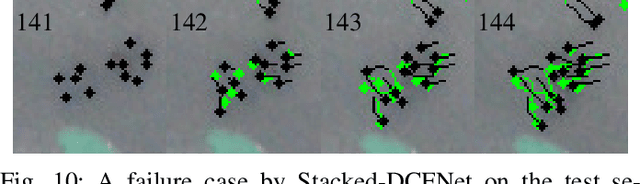
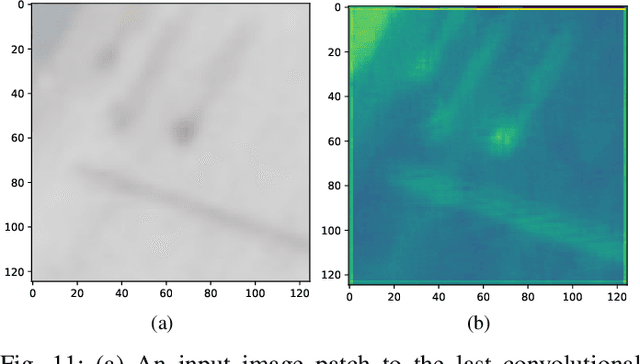
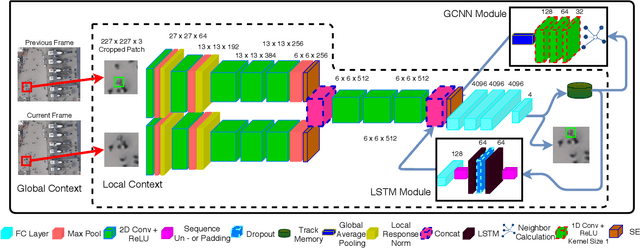
Multi-pedestrian tracking in aerial imagery has several applications such as large-scale event monitoring, disaster management, search-and-rescue missions, and as input into predictive crowd dynamic models. Due to the challenges such as the large number and the tiny size of the pedestrians (e.g., 4 x 4 pixels) with their similar appearances as well as different scales and atmospheric conditions of the images with their extremely low frame rates (e.g., 2 fps), current state-of-the-art algorithms including the deep learning-based ones are unable to perform well. In this paper, we propose AerialMPTNet, a novel approach for multi-pedestrian tracking in geo-referenced aerial imagery by fusing appearance features from a Siamese Neural Network, movement predictions from a Long Short-Term Memory, and pedestrian interconnections from a GraphCNN. In addition, to address the lack of diverse aerial pedestrian tracking datasets, we introduce the Aerial Multi-Pedestrian Tracking (AerialMPT) dataset consisting of 307 frames and 44,740 pedestrians annotated. We believe that AerialMPT is the largest and most diverse dataset to this date and will be released publicly. We evaluate AerialMPTNet on AerialMPT and KIT AIS, and benchmark with several state-of-the-art tracking methods. Results indicate that AerialMPTNet significantly outperforms other methods on accuracy and time-efficiency.
MRCNet: Crowd Counting and Density Map Estimation in Aerial and Ground Imagery
Sep 27, 2019
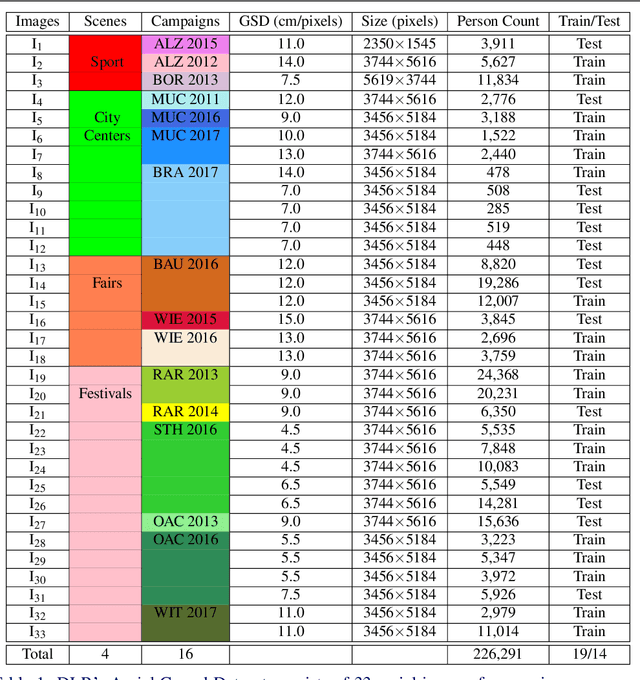


In spite of the many advantages of aerial imagery for crowd monitoring and management at mass events, datasets of aerial images of crowds are still lacking in the field. As a remedy, in this work we introduce a novel crowd dataset, the DLR Aerial Crowd Dataset (DLR-ACD), which is composed of 33 large aerial images acquired from 16 flight campaigns over mass events with 226,291 persons annotated. To the best of our knowledge, DLR-ACD is the first aerial crowd dataset and will be released publicly. To tackle the problem of accurate crowd counting and density map estimation in aerial images of crowds, this work also proposes a new encoder-decoder convolutional neural network, the so-called Multi-Resolution Crowd Network MRCNet. The encoder is based on the VGG-16 network and the decoder is composed of a set of bilinear upsampling and convolutional layers. Using two losses, one at an earlier level and another at the last level of the decoder, MRCNet estimates crowd counts and high-resolution crowd density maps as two different but interrelated tasks. In addition, MRCNet utilizes contextual and detailed local information by combining high- and low-level features through a number of lateral connections inspired by the Feature Pyramid Network (FPN) technique. We evaluated MRCNet on the proposed DLR-ACD dataset as well as on the ShanghaiTech dataset, a CCTV-based crowd counting benchmark. The results demonstrate that MRCNet outperforms the state-of-the-art crowd counting methods in estimating the crowd counts and density maps for both aerial and CCTV-based images.
Late or Earlier Information Fusion from Depth and Spectral Data? Large-Scale Digital Surface Model Refinement by Hybrid-cGAN
Apr 22, 2019
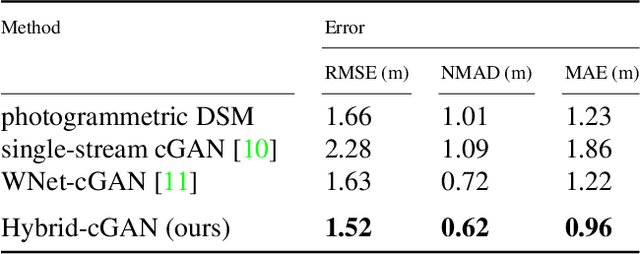


We present the workflow of a DSM refinement methodology using a Hybrid-cGAN where the generative part consists of two encoders and a common decoder which blends the spectral and height information within one network. The inputs to the Hybrid-cGAN are single-channel photogrammetric DSMs with continuous values and single-channel pan-chromatic (PAN) half-meter resolution satellite images. Experimental results demonstrate that the earlier information fusion from data with different physical meanings helps to propagate fine details and complete an inaccurate or missing 3D information about building forms. Moreover, it improves the building boundaries making them more rectilinear.
DSM Building Shape Refinement from Combined Remote Sensing Images based on Wnet-cGANs
Mar 08, 2019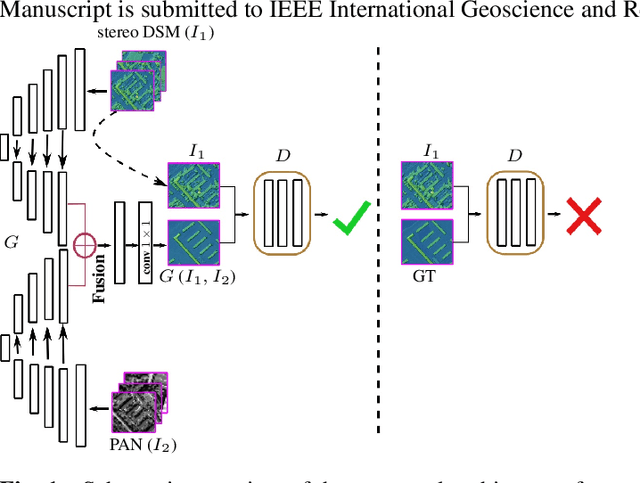
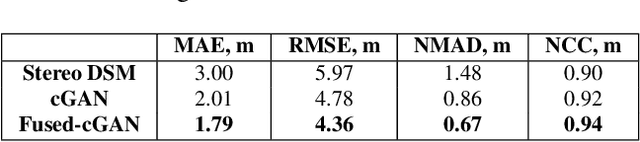

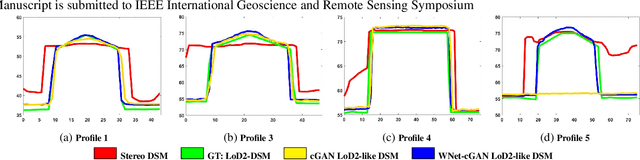
We describe the workflow of a digital surface models (DSMs) refinement algorithm using a hybrid conditional generative adversarial network (cGAN) where the generative part consists of two parallel networks merged at the last stage forming a WNet architecture. The inputs to the so-called WNet-cGAN are stereo DSMs and panchromatic (PAN) half-meter resolution satellite images. Fusing these helps to propagate fine detailed information from a spectral image and complete the missing 3D knowledge from a stereo DSM about building shapes. Besides, it refines the building outlines and edges making them more rectangular and sharp.
Aerial LaneNet: Lane Marking Semantic Segmentation in Aerial Imagery using Wavelet-Enhanced Cost-sensitive Symmetric Fully Convolutional Neural Networks
Nov 01, 2018

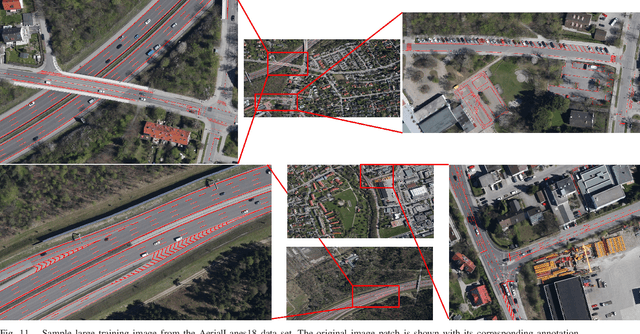
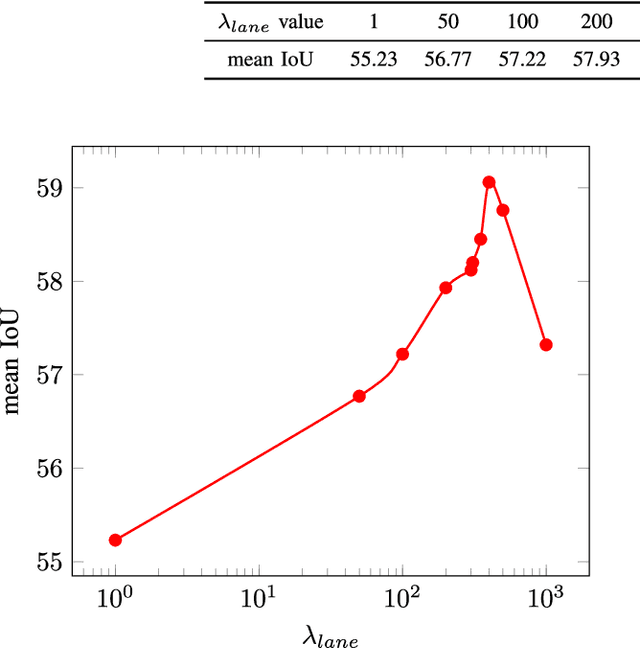
The knowledge about the placement and appearance of lane markings is a prerequisite for the creation of maps with high precision, necessary for autonomous driving, infrastructure monitoring, lane-wise traffic management, and urban planning. Lane markings are one of the important components of such maps. Lane markings convey the rules of roads to drivers. While these rules are learned by humans, an autonomous driving vehicle should be taught to learn them to localize itself. Therefore, accurate and reliable lane marking semantic segmentation in the imagery of roads and highways is needed to achieve such goals. We use airborne imagery which can capture a large area in a short period of time by introducing an aerial lane marking dataset. In this work, we propose a Symmetric Fully Convolutional Neural Network enhanced by Wavelet Transform in order to automatically carry out lane marking segmentation in aerial imagery. Due to a heavily unbalanced problem in terms of number of lane marking pixels compared with background pixels, we use a customized loss function as well as a new type of data augmentation step. We achieve a very high accuracy in pixel-wise localization of lane markings without using 3rd-party information. In this work, we introduce the first high-quality dataset used within our experiments which contains a broad range of situations and classes of lane markings representative of current transportation systems. This dataset will be publicly available and hence, it can be used as the benchmark dataset for future algorithms within this domain.
Towards Multi-class Object Detection in Unconstrained Remote Sensing Imagery
Nov 01, 2018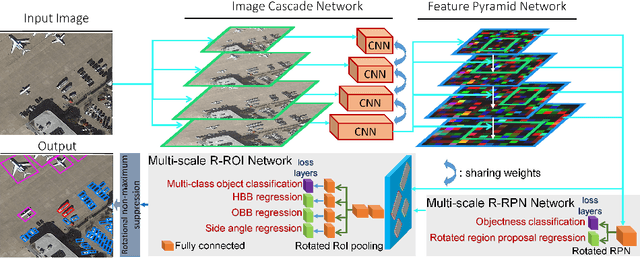
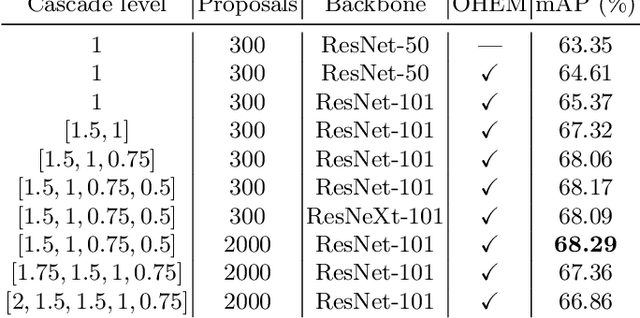
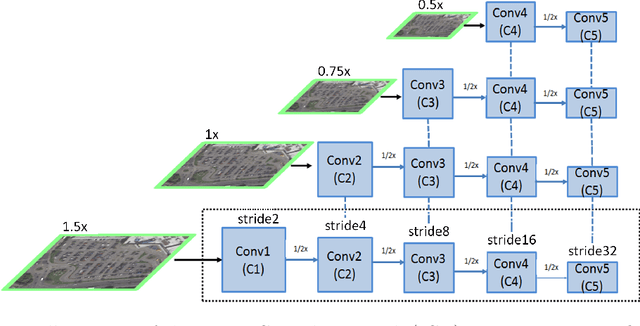

Automatic multi-class object detection in remote sensing images in unconstrained scenarios is of high interest for several applications including traffic monitoring and disaster management. The huge variation in object scale, orientation, category, and complex backgrounds, as well as the different camera sensors pose great challenges for current algorithms. In this work, we propose a new method consisting of a novel joint image cascade and feature pyramid network with multi-size convolution kernels to extract multi-scale strong and weak semantic features. These features are fed into rotation-based region proposal and region of interest networks to produce object detections. Finally, rotational non-maximum suppression is applied to remove redundant detections. During training, we minimize joint horizontal and oriented bounding box loss functions, as well as a novel loss that enforces oriented boxes to be rectangular. Our method achieves 68.16% mAP on horizontal and 72.45% mAP on oriented bounding box detection tasks on the challenging DOTA dataset, outperforming all published methods by a large margin (+6% and +12% absolute improvement, respectively). Furthermore, it generalizes to two other datasets, NWPU VHR-10 and UCAS-AOD, and achieves competitive results with the baselines even when trained on DOTA. Our method can be deployed in multi-class object detection applications, regardless of the image and object scales and orientations, making it a great choice for unconstrained aerial and satellite imagery.
Artificial Generation of Big Data for Improving Image Classification: A Generative Adversarial Network Approach on SAR Data
Nov 06, 2017
Very High Spatial Resolution (VHSR) large-scale SAR image databases are still an unresolved issue in the Remote Sensing field. In this work, we propose such a dataset and use it to explore patch-based classification in urban and periurban areas, considering 7 distinct semantic classes. In this context, we investigate the accuracy of large CNN classification models and pre-trained networks for SAR imaging systems. Furthermore, we propose a Generative Adversarial Network (GAN) for SAR image generation and test, whether the synthetic data can actually improve classification accuracy.
Authorship Analysis based on Data Compression
Feb 14, 2014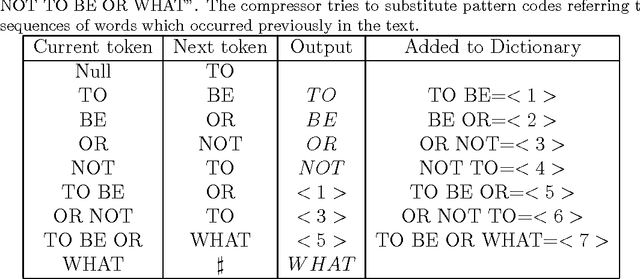

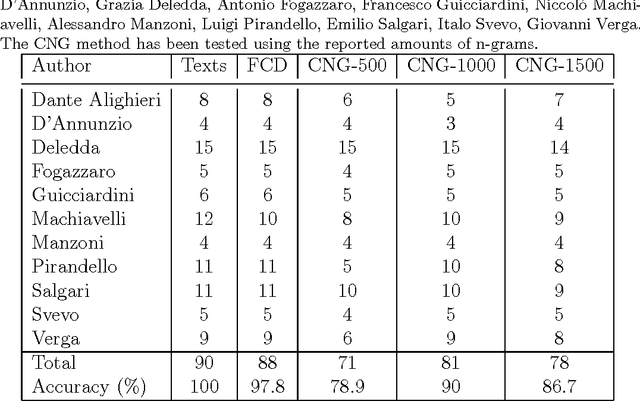
This paper proposes to perform authorship analysis using the Fast Compression Distance (FCD), a similarity measure based on compression with dictionaries directly extracted from the written texts. The FCD computes a similarity between two documents through an effective binary search on the intersection set between the two related dictionaries. In the reported experiments the proposed method is applied to documents which are heterogeneous in style, written in five different languages and coming from different historical periods. Results are comparable to the state of the art and outperform traditional compression-based methods.