 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Building Roof Type Classification: A Domain-Specific Self-Supervised Approach
Mar 28, 2025



Accurate classification of building roof types from aerial imagery is crucial for various remote sensing applications, including urban planning, disaster management, and infrastructure monitoring. However, this task is often hindered by the limited availability of labeled data for supervised learning approaches. To address this challenge, this paper investigates the effectiveness of self supervised learning with EfficientNet architectures, known for their computational efficiency, for building roof type classification. We propose a novel framework that incorporates a Convolutional Block Attention Module (CBAM) to enhance the feature extraction capabilities of EfficientNet. Furthermore, we explore the benefits of pretraining on a domain-specific dataset, the Aerial Image Dataset (AID), compared to ImageNet pretraining. Our experimental results demonstrate the superiority of our approach. Employing Simple Framework for Contrastive Learning of Visual Representations (SimCLR) with EfficientNet-B3 and CBAM achieves a 95.5% accuracy on our validation set, matching the performance of state-of-the-art transformer-based models while utilizing significantly fewer parameters. We also provide a comprehensive evaluation on two challenging test sets, demonstrating the generalization capability of our method. Notably, our findings highlight the effectiveness of domain-specific pretraining, consistently leading to higher accuracy compared to models pretrained on the generic ImageNet dataset. Our work establishes EfficientNet based self-supervised learning as a computationally efficient and highly effective approach for building roof type classification, particularly beneficial in scenarios with limited labeled data.
HiRes-FusedMIM: A High-Resolution RGB-DSM Pre-trained Model for Building-Level Remote Sensing Applications
Mar 24, 2025
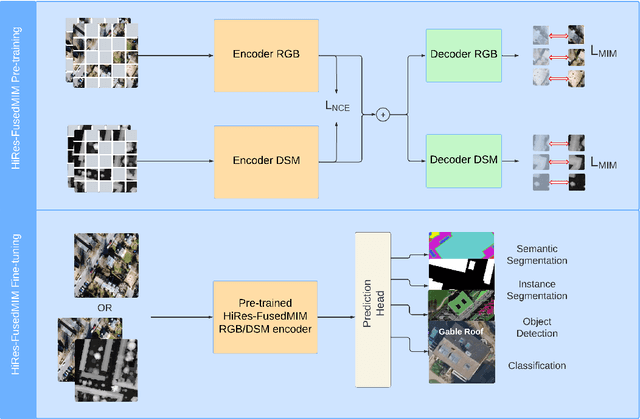
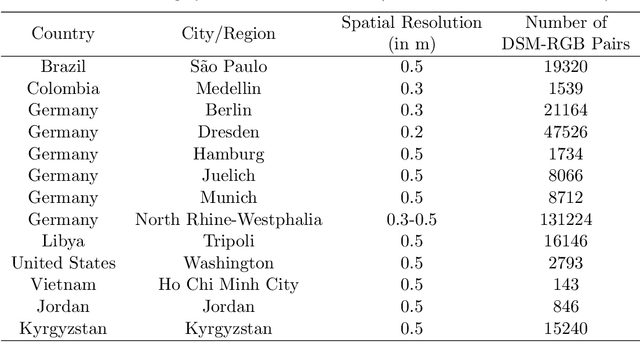

Recent advances in self-supervised learning have led to the development of foundation models that have significantly advanced performance in various computer vision tasks. However, despite their potential, these models often overlook the crucial role of high-resolution digital surface models (DSMs) in understanding urban environments, particularly for building-level analysis, which is essential for applications like digital twins. To address this gap, we introduce HiRes-FusedMIM, a novel pre-trained model specifically designed to leverage the rich information contained within high-resolution RGB and DSM data. HiRes-FusedMIM utilizes a dual-encoder simple masked image modeling (SimMIM) architecture with a multi-objective loss function that combines reconstruction and contrastive objectives, enabling it to learn powerful, joint representations from both modalities. We conducted a comprehensive evaluation of HiRes-FusedMIM on a diverse set of downstream tasks, including classification, semantic segmentation, and instance segmentation. Our results demonstrate that: 1) HiRes-FusedMIM outperforms previous state-of-the-art geospatial methods on several building-related datasets, including WHU Aerial and LoveDA, demonstrating its effectiveness in capturing and leveraging fine-grained building information; 2) Incorporating DSMs during pre-training consistently improves performance compared to using RGB data alone, highlighting the value of elevation information for building-level analysis; 3) The dual-encoder architecture of HiRes-FusedMIM, with separate encoders for RGB and DSM data, significantly outperforms a single-encoder model on the Vaihingen segmentation task, indicating the benefits of learning specialized representations for each modality. To facilitate further research and applications in this direction, we will publicly release the trained model weights.
PolyRoof: Precision Roof Polygonization in Urban Residential Building with Graph Neural Networks
Mar 13, 2025The growing demand for detailed building roof data has driven the development of automated extraction methods to overcome the inefficiencies of traditional approaches, particularly in handling complex variations in building geometries. Re:PolyWorld, which integrates point detection with graph neural networks, presents a promising solution for reconstructing high-detail building roof vector data. This study enhances Re:PolyWorld's performance on complex urban residential structures by incorporating attention-based backbones and additional area segmentation loss. Despite dataset limitations, our experiments demonstrated improvements in point position accuracy (1.33 pixels) and line distance accuracy (14.39 pixels), along with a notable increase in the reconstruction score to 91.99%. These findings highlight the potential of advanced neural network architectures in addressing the challenges of complex urban residential geometries.
Can Location Embeddings Enhance Super-Resolution of Satellite Imagery?
Jan 27, 2025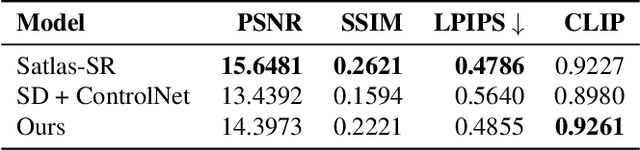
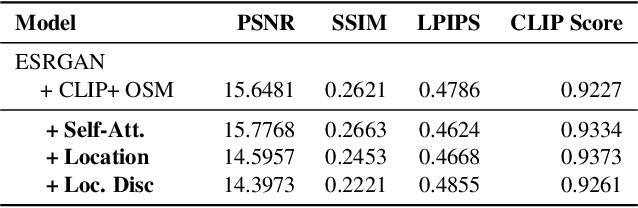

Publicly available satellite imagery, such as Sentinel- 2, often lacks the spatial resolution required for accurate analysis of remote sensing tasks including urban planning and disaster response. Current super-resolution techniques are typically trained on limited datasets, leading to poor generalization across diverse geographic regions. In this work, we propose a novel super-resolution framework that enhances generalization by incorporating geographic context through location embeddings. Our framework employs Generative Adversarial Networks (GANs) and incorporates techniques from diffusion models to enhance image quality. Furthermore, we address tiling artifacts by integrating information from neighboring images, enabling the generation of seamless, high-resolution outputs. We demonstrate the effectiveness of our method on the building segmentation task, showing significant improvements over state-of-the-art methods and highlighting its potential for real-world applications.
Dfilled: Repurposing Edge-Enhancing Diffusion for Guided DSM Void Filling
Jan 26, 2025



Digital Surface Models (DSMs) are essential for accurately representing Earth's topography in geospatial analyses. DSMs capture detailed elevations of natural and manmade features, crucial for applications like urban planning, vegetation studies, and 3D reconstruction. However, DSMs derived from stereo satellite imagery often contain voids or missing data due to occlusions, shadows, and lowsignal areas. Previous studies have primarily focused on void filling for digital elevation models (DEMs) and Digital Terrain Models (DTMs), employing methods such as inverse distance weighting (IDW), kriging, and spline interpolation. While effective for simpler terrains, these approaches often fail to handle the intricate structures present in DSMs. To overcome these limitations, we introduce Dfilled, a guided DSM void filling method that leverages optical remote sensing images through edge-enhancing diffusion. Dfilled repurposes deep anisotropic diffusion models, which originally designed for super-resolution tasks, to inpaint DSMs. Additionally, we utilize Perlin noise to create inpainting masks that mimic natural void patterns in DSMs. Experimental evaluations demonstrate that Dfilled surpasses traditional interpolation methods and deep learning approaches in DSM void filling tasks. Both quantitative and qualitative assessments highlight the method's ability to manage complex features and deliver accurate, visually coherent results.
SyntStereo2Real: Edge-Aware GAN for Remote Sensing Image-to-Image Translation while Maintaining Stereo Constraint
Apr 14, 2024



In the field of remote sensing, the scarcity of stereo-matched and particularly lack of accurate ground truth data often hinders the training of deep neural networks. The use of synthetically generated images as an alternative, alleviates this problem but suffers from the problem of domain generalization. Unifying the capabilities of image-to-image translation and stereo-matching presents an effective solution to address the issue of domain generalization. Current methods involve combining two networks, an unpaired image-to-image translation network and a stereo-matching network, while jointly optimizing them. We propose an edge-aware GAN-based network that effectively tackles both tasks simultaneously. We obtain edge maps of input images from the Sobel operator and use it as an additional input to the encoder in the generator to enforce geometric consistency during translation. We additionally include a warping loss calculated from the translated images to maintain the stereo consistency. We demonstrate that our model produces qualitatively and quantitatively superior results than existing models, and its applicability extends to diverse domains, including autonomous driving.
Real-GDSR: Real-World Guided DSM Super-Resolution via Edge-Enhancing Residual Network
Apr 05, 2024A low-resolution digital surface model (DSM) features distinctive attributes impacted by noise, sensor limitations and data acquisition conditions, which failed to be replicated using simple interpolation methods like bicubic. This causes super-resolution models trained on synthetic data does not perform effectively on real ones. Training a model on real low and high resolution DSMs pairs is also a challenge because of the lack of information. On the other hand, the existence of other imaging modalities of the same scene can be used to enrich the information needed for large-scale super-resolution. In this work, we introduce a novel methodology to address the intricacies of real-world DSM super-resolution, named REAL-GDSR, breaking down this ill-posed problem into two steps. The first step involves the utilization of a residual local refinement network. This strategic approach departs from conventional methods that trained to directly predict height values instead of the differences (residuals) and utilize large receptive fields in their networks. The second step introduces a diffusion-based technique that enhances the results on a global scale, with a primary focus on smoothing and edge preservation. Our experiments underscore the effectiveness of the proposed method. We conduct a comprehensive evaluation, comparing it to recent state-of-the-art techniques in the domain of real-world DSM super-resolution (SR). Our approach consistently outperforms these existing methods, as evidenced through qualitative and quantitative assessments.
Machine-learned 3D Building Vectorization from Satellite Imagery
Apr 13, 2021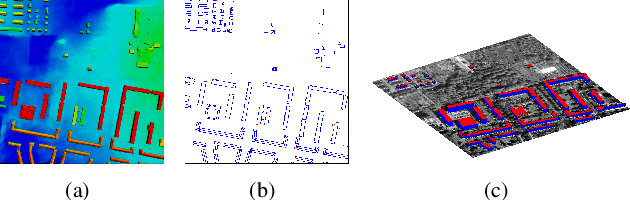
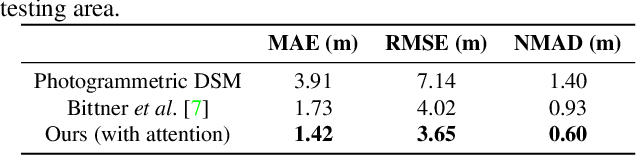
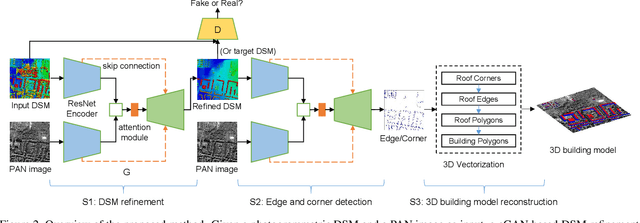
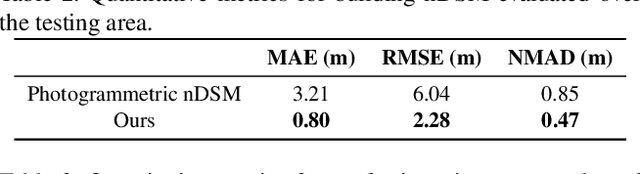
We propose a machine learning based approach for automatic 3D building reconstruction and vectorization. Taking a single-channel photogrammetric digital surface model (DSM) and panchromatic (PAN) image as input, we first filter out non-building objects and refine the building shapes of input DSM with a conditional generative adversarial network (cGAN). The refined DSM and the input PAN image are then used through a semantic segmentation network to detect edges and corners of building roofs. Later, a set of vectorization algorithms are proposed to build roof polygons. Finally, the height information from the refined DSM is added to the polygons to obtain a fully vectorized level of detail (LoD)-2 building model. We verify the effectiveness of our method on large-scale satellite images, where we obtain state-of-the-art performance.
Machine-learned Regularization and Polygonization of Building Segmentation Masks
Aug 03, 2020
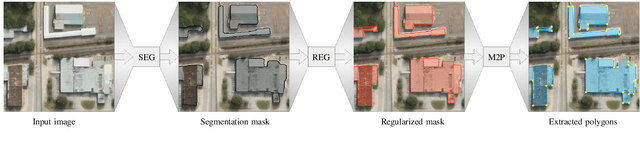
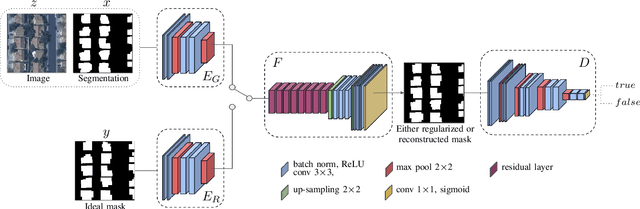
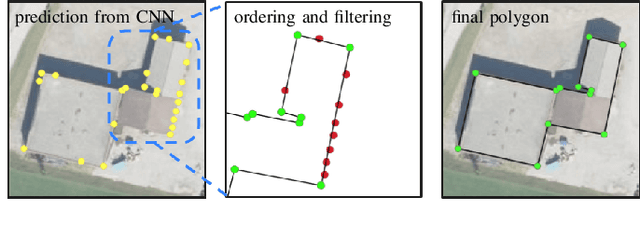
We propose a machine learning based approach for automatic regularization and polygonization of building segmentation masks. Taking an image as input, we first predict building segmentation maps exploiting generic fully convolutional network (FCN). A generative adversarial network (GAN) is then involved to perform a regularization of building boundaries to make them more realistic, i.e., having more rectilinear outlines which construct right angles if required. This is achieved through the interplay between the discriminator which gives a probability of input image being true and generator that learns from discriminator's response to create more realistic images. Finally, we train the backbone convolutional neural network (CNN) which is adapted to predict sparse outcomes corresponding to building corners out of regularized building segmentation results. Experiments on three building segmentation datasets demonstrate that the proposed method is not only capable of obtaining accurate results, but also of producing visually pleasing building outlines parameterized as polygons.
Map-Repair: Deep Cadastre Maps Alignment and Temporal Inconsistencies Fix in Satellite Images
Jul 24, 2020
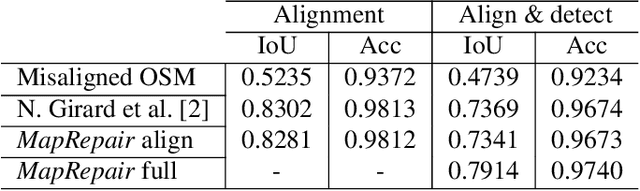
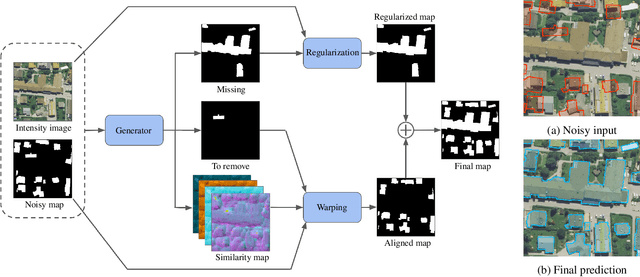

In the fast developing countries it is hard to trace new buildings construction or old structures destruction and, as a result, to keep the up-to-date cadastre maps. Moreover, due to the complexity of urban regions or inconsistency of data used for cadastre maps extraction, the errors in form of misalignment is a common problem. In this work, we propose an end-to-end deep learning approach which is able to solve inconsistencies between the input intensity image and the available building footprints by correcting label noises and, at the same time, misalignments if needed. The obtained results demonstrate the robustness of the proposed method to even severely misaligned examples that makes it potentially suitable for real applications, like OpenStreetMap correction.