 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Building Roof Type Classification: A Domain-Specific Self-Supervised Approach
Mar 28, 2025



Accurate classification of building roof types from aerial imagery is crucial for various remote sensing applications, including urban planning, disaster management, and infrastructure monitoring. However, this task is often hindered by the limited availability of labeled data for supervised learning approaches. To address this challenge, this paper investigates the effectiveness of self supervised learning with EfficientNet architectures, known for their computational efficiency, for building roof type classification. We propose a novel framework that incorporates a Convolutional Block Attention Module (CBAM) to enhance the feature extraction capabilities of EfficientNet. Furthermore, we explore the benefits of pretraining on a domain-specific dataset, the Aerial Image Dataset (AID), compared to ImageNet pretraining. Our experimental results demonstrate the superiority of our approach. Employing Simple Framework for Contrastive Learning of Visual Representations (SimCLR) with EfficientNet-B3 and CBAM achieves a 95.5% accuracy on our validation set, matching the performance of state-of-the-art transformer-based models while utilizing significantly fewer parameters. We also provide a comprehensive evaluation on two challenging test sets, demonstrating the generalization capability of our method. Notably, our findings highlight the effectiveness of domain-specific pretraining, consistently leading to higher accuracy compared to models pretrained on the generic ImageNet dataset. Our work establishes EfficientNet based self-supervised learning as a computationally efficient and highly effective approach for building roof type classification, particularly beneficial in scenarios with limited labeled data.
HiRes-FusedMIM: A High-Resolution RGB-DSM Pre-trained Model for Building-Level Remote Sensing Applications
Mar 24, 2025
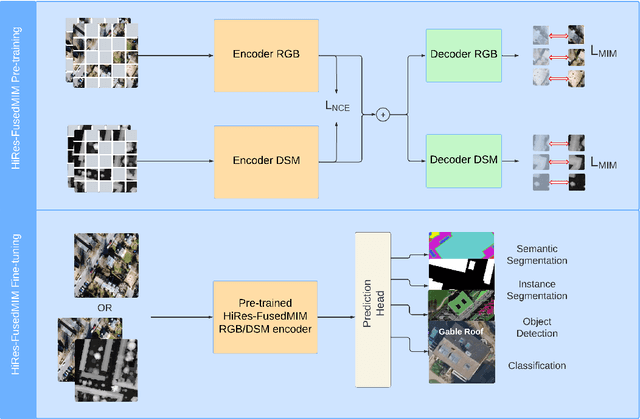

Recent advances in self-supervised learning have led to the development of foundation models that have significantly advanced performance in various computer vision tasks. However, despite their potential, these models often overlook the crucial role of high-resolution digital surface models (DSMs) in understanding urban environments, particularly for building-level analysis, which is essential for applications like digital twins. To address this gap, we introduce HiRes-FusedMIM, a novel pre-trained model specifically designed to leverage the rich information contained within high-resolution RGB and DSM data. HiRes-FusedMIM utilizes a dual-encoder simple masked image modeling (SimMIM) architecture with a multi-objective loss function that combines reconstruction and contrastive objectives, enabling it to learn powerful, joint representations from both modalities. We conducted a comprehensive evaluation of HiRes-FusedMIM on a diverse set of downstream tasks, including classification, semantic segmentation, and instance segmentation. Our results demonstrate that: 1) HiRes-FusedMIM outperforms previous state-of-the-art geospatial methods on several building-related datasets, including WHU Aerial and LoveDA, demonstrating its effectiveness in capturing and leveraging fine-grained building information; 2) Incorporating DSMs during pre-training consistently improves performance compared to using RGB data alone, highlighting the value of elevation information for building-level analysis; 3) The dual-encoder architecture of HiRes-FusedMIM, with separate encoders for RGB and DSM data, significantly outperforms a single-encoder model on the Vaihingen segmentation task, indicating the benefits of learning specialized representations for each modality. To facilitate further research and applications in this direction, we will publicly release the trained model weights.