 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDrones4Good: Supporting Disaster Relief Through Remote Sensing and AI
Aug 09, 2023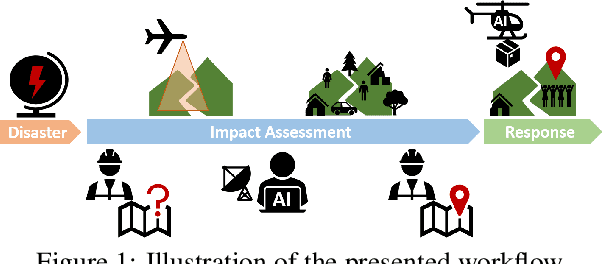



In order to respond effectively in the aftermath of a disaster, emergency services and relief organizations rely on timely and accurate information about the affected areas. Remote sensing has the potential to significantly reduce the time and effort required to collect such information by enabling a rapid survey of large areas. To achieve this, the main challenge is the automatic extraction of relevant information from remotely sensed data. In this work, we show how the combination of drone-based data with deep learning methods enables automated and large-scale situation assessment. In addition, we demonstrate the integration of onboard image processing techniques for the deployment of autonomous drone-based aid delivery. The results show the feasibility of a rapid and large-scale image analysis in the field, and that onboard image processing can increase the safety of drone-based aid deliveries.
Multiple Pedestrians and Vehicles Tracking in Aerial Imagery: A Comprehensive Study
Oct 19, 2020
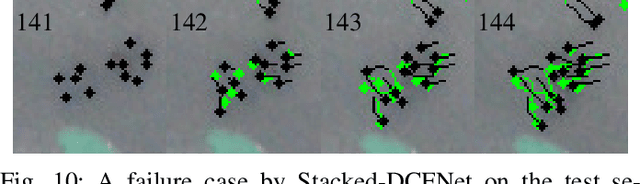
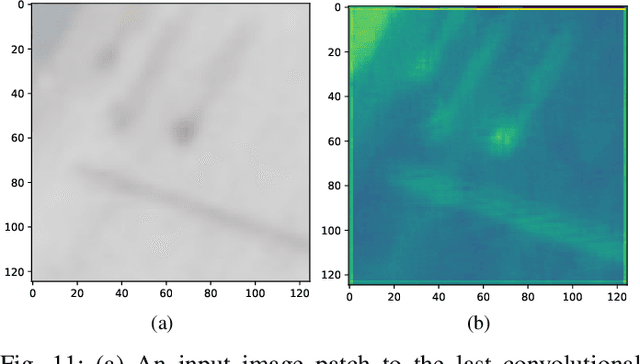
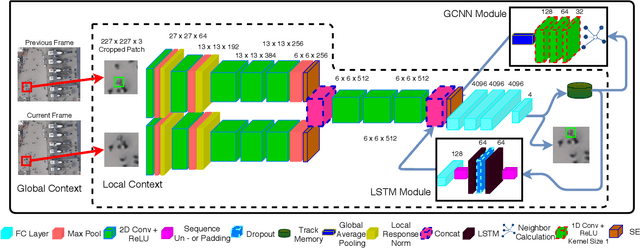
In this paper, we address various challenges in multi-pedestrian and vehicle tracking in high-resolution aerial imagery by intensive evaluation of a number of traditional and Deep Learning based Single- and Multi-Object Tracking methods. We also describe our proposed Deep Learning based Multi-Object Tracking method AerialMPTNet that fuses appearance, temporal, and graphical information using a Siamese Neural Network, a Long Short-Term Memory, and a Graph Convolutional Neural Network module for a more accurate and stable tracking. Moreover, we investigate the influence of the Squeeze-and-Excitation layers and Online Hard Example Mining on the performance of AerialMPTNet. To the best of our knowledge, we are the first in using these two for a regression-based Multi-Object Tracking. Additionally, we studied and compared the L1 and Huber loss functions. In our experiments, we extensively evaluate AerialMPTNet on three aerial Multi-Object Tracking datasets, namely AerialMPT and KIT AIS pedestrian and vehicle datasets. Qualitative and quantitative results show that AerialMPTNet outperforms all previous methods for the pedestrian datasets and achieves competitive results for the vehicle dataset. In addition, Long Short-Term Memory and Graph Convolutional Neural Network modules enhance the tracking performance. Moreover, using Squeeze-and-Excitation and Online Hard Example Mining significantly helps for some cases while degrades the results for other cases. In addition, according to the results, L1 yields better results with respect to Huber loss for most of the scenarios. The presented results provide a deep insight into challenges and opportunities of the aerial Multi-Object Tracking domain, paving the way for future research.
EAGLE: Large-scale Vehicle Detection Dataset inReal-World Scenarios using Aerial Imagery
Jul 17, 2020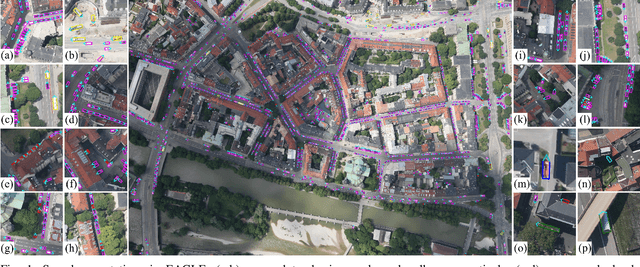
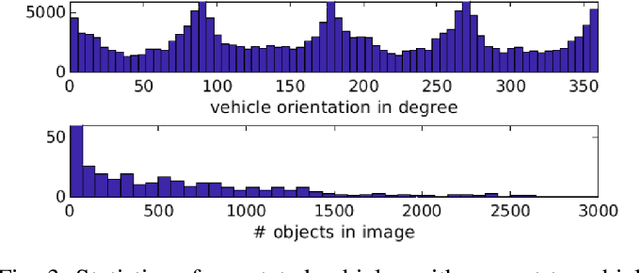
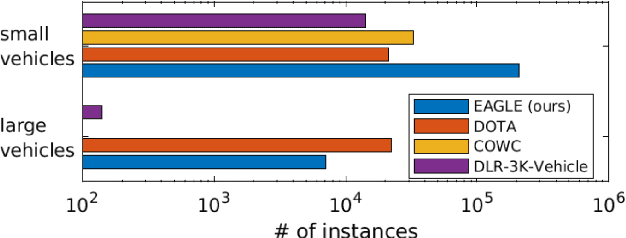
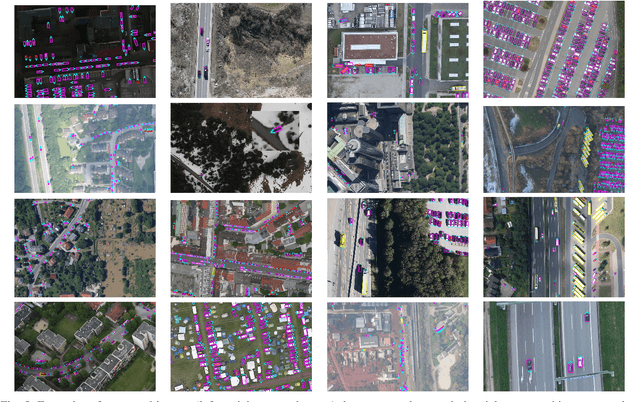
Multi-class vehicle detection from airborne imagery with orientation estimation is an important task in the near and remote vision domains with applications in traffic monitoring and disaster management. In the last decade, we have witnessed significant progress in object detection in ground imagery, but it is still in its infancy in airborne imagery, mostly due to the scarcity of diverse and large-scale datasets. Despite being a useful tool for different applications, current airborne datasets only partially reflect the challenges of real-world scenarios. To address this issue, we introduce EAGLE (oriEnted vehicle detection using Aerial imaGery in real-worLd scEnarios), a large-scale dataset for multi-class vehicle detection with object orientation information in aerial imagery. It features high-resolution aerial images composed of different real-world situations with a wide variety of camera sensor, resolution, flight altitude, weather, illumination, haze, shadow, time, city, country, occlusion, and camera angle. The annotation was done by airborne imagery experts with small- and large-vehicle classes. EAGLE contains 215,986 instances annotated with oriented bounding boxes defined by four points and orientation, making it by far the largest dataset to date in this task. It also supports researches on the haze and shadow removal as well as super-resolution and in-painting applications. We define three tasks: detection by (1) horizontal bounding boxes, (2) rotated bounding boxes, and (3) oriented bounding boxes. We carried out several experiments to evaluate several state-of-the-art methods in object detection on our dataset to form a baseline. Experiments show that the EAGLE dataset accurately reflects real-world situations and correspondingly challenging applications.
SkyScapes -- Fine-Grained Semantic Understanding of Aerial Scenes
Jul 12, 2020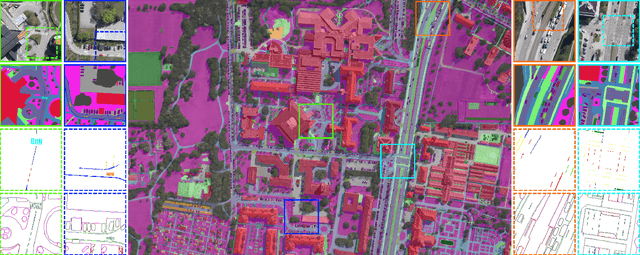
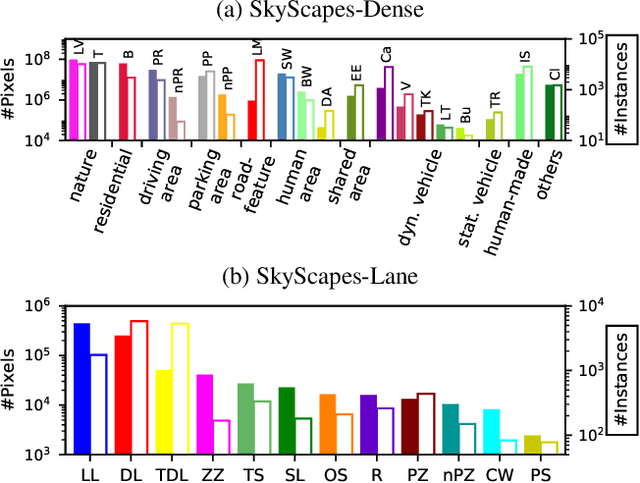
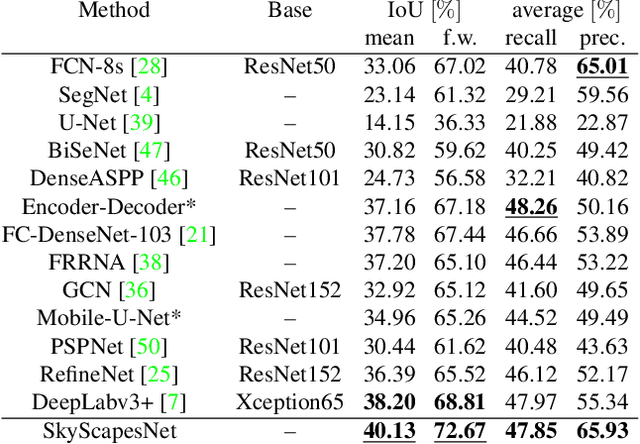
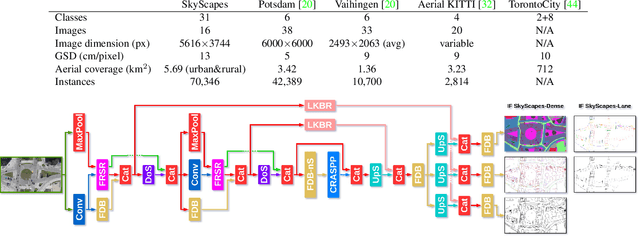
Understanding the complex urban infrastructure with centimeter-level accuracy is essential for many applications from autonomous driving to mapping, infrastructure monitoring, and urban management. Aerial images provide valuable information over a large area instantaneously; nevertheless, no current dataset captures the complexity of aerial scenes at the level of granularity required by real-world applications. To address this, we introduce SkyScapes, an aerial image dataset with highly-accurate, fine-grained annotations for pixel-level semantic labeling. SkyScapes provides annotations for 31 semantic categories ranging from large structures, such as buildings, roads and vegetation, to fine details, such as 12 (sub-)categories of lane markings. We have defined two main tasks on this dataset: dense semantic segmentation and multi-class lane-marking prediction. We carry out extensive experiments to evaluate state-of-the-art segmentation methods on SkyScapes. Existing methods struggle to deal with the wide range of classes, object sizes, scales, and fine details present. We therefore propose a novel multi-task model, which incorporates semantic edge detection and is better tuned for feature extraction from a wide range of scales. This model achieves notable improvements over the baselines in region outlines and level of detail on both tasks.
AerialMPTNet: Multi-Pedestrian Tracking in Aerial Imagery Using Temporal and Graphical Features
Jun 27, 2020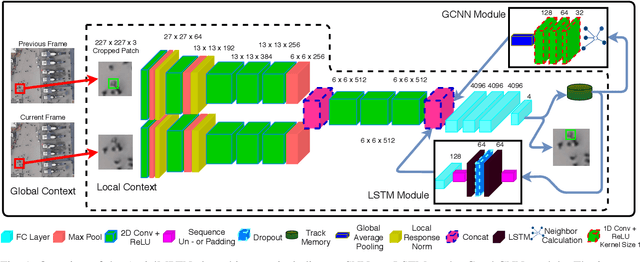

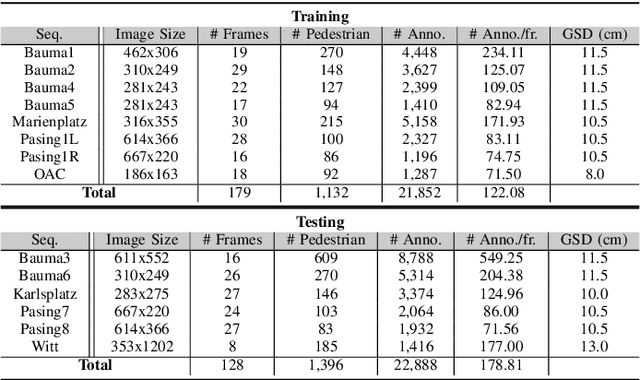

Multi-pedestrian tracking in aerial imagery has several applications such as large-scale event monitoring, disaster management, search-and-rescue missions, and as input into predictive crowd dynamic models. Due to the challenges such as the large number and the tiny size of the pedestrians (e.g., 4 x 4 pixels) with their similar appearances as well as different scales and atmospheric conditions of the images with their extremely low frame rates (e.g., 2 fps), current state-of-the-art algorithms including the deep learning-based ones are unable to perform well. In this paper, we propose AerialMPTNet, a novel approach for multi-pedestrian tracking in geo-referenced aerial imagery by fusing appearance features from a Siamese Neural Network, movement predictions from a Long Short-Term Memory, and pedestrian interconnections from a GraphCNN. In addition, to address the lack of diverse aerial pedestrian tracking datasets, we introduce the Aerial Multi-Pedestrian Tracking (AerialMPT) dataset consisting of 307 frames and 44,740 pedestrians annotated. We believe that AerialMPT is the largest and most diverse dataset to this date and will be released publicly. We evaluate AerialMPTNet on AerialMPT and KIT AIS, and benchmark with several state-of-the-art tracking methods. Results indicate that AerialMPTNet significantly outperforms other methods on accuracy and time-efficiency.
ShuffleDet: Real-Time Vehicle Detection Network in On-board Embedded UAV Imagery
Nov 15, 2018
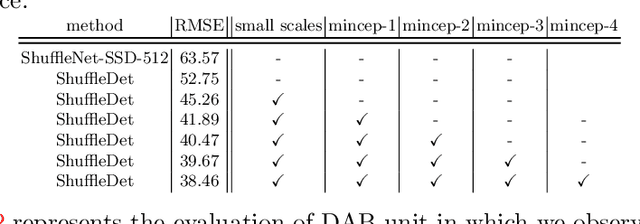


On-board real-time vehicle detection is of great significance for UAVs and other embedded mobile platforms. We propose a computationally inexpensive detection network for vehicle detection in UAV imagery which we call ShuffleDet. In order to enhance the speed-wise performance, we construct our method primarily using channel shuffling and grouped convolutions. We apply inception modules and deformable modules to consider the size and geometric shape of the vehicles. ShuffleDet is evaluated on CARPK and PUCPR+ datasets and compared against the state-of-the-art real-time object detection networks. ShuffleDet achieves 3.8 GFLOPs while it provides competitive performance on test sets of both datasets. We show that our algorithm achieves real-time performance by running at the speed of 14 frames per second on NVIDIA Jetson TX2 showing high potential for this method for real-time processing in UAVs.
Aerial LaneNet: Lane Marking Semantic Segmentation in Aerial Imagery using Wavelet-Enhanced Cost-sensitive Symmetric Fully Convolutional Neural Networks
Nov 01, 2018

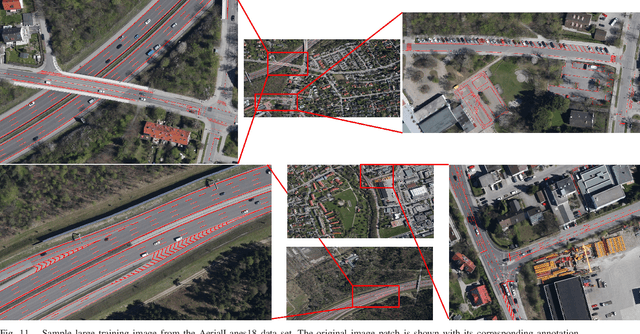
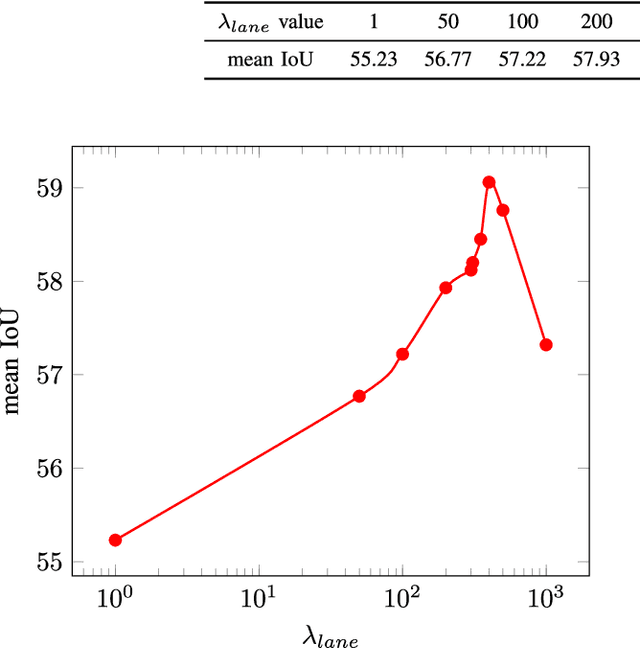
The knowledge about the placement and appearance of lane markings is a prerequisite for the creation of maps with high precision, necessary for autonomous driving, infrastructure monitoring, lane-wise traffic management, and urban planning. Lane markings are one of the important components of such maps. Lane markings convey the rules of roads to drivers. While these rules are learned by humans, an autonomous driving vehicle should be taught to learn them to localize itself. Therefore, accurate and reliable lane marking semantic segmentation in the imagery of roads and highways is needed to achieve such goals. We use airborne imagery which can capture a large area in a short period of time by introducing an aerial lane marking dataset. In this work, we propose a Symmetric Fully Convolutional Neural Network enhanced by Wavelet Transform in order to automatically carry out lane marking segmentation in aerial imagery. Due to a heavily unbalanced problem in terms of number of lane marking pixels compared with background pixels, we use a customized loss function as well as a new type of data augmentation step. We achieve a very high accuracy in pixel-wise localization of lane markings without using 3rd-party information. In this work, we introduce the first high-quality dataset used within our experiments which contains a broad range of situations and classes of lane markings representative of current transportation systems. This dataset will be publicly available and hence, it can be used as the benchmark dataset for future algorithms within this domain.
Towards Multi-class Object Detection in Unconstrained Remote Sensing Imagery
Nov 01, 2018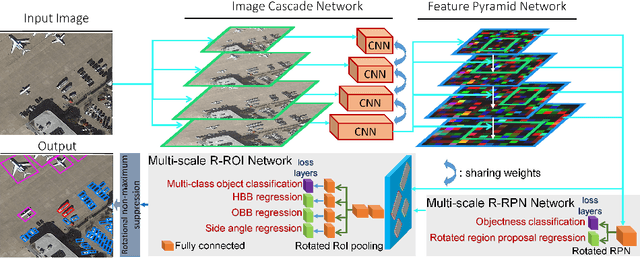
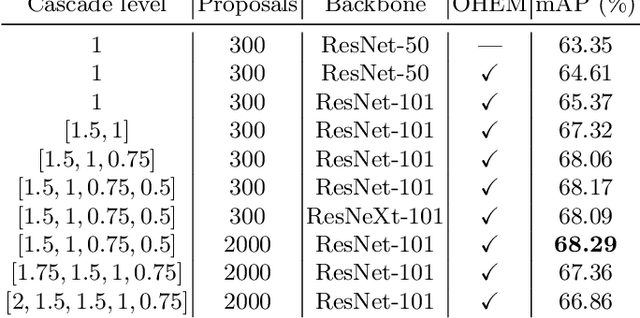
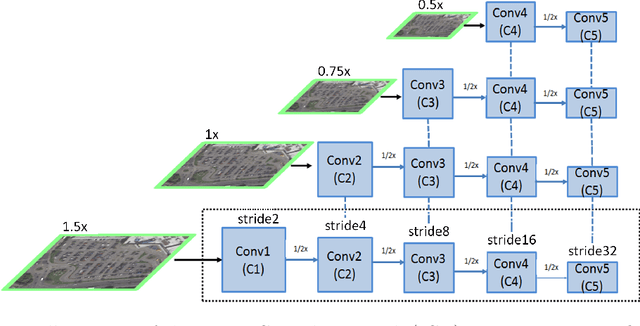

Automatic multi-class object detection in remote sensing images in unconstrained scenarios is of high interest for several applications including traffic monitoring and disaster management. The huge variation in object scale, orientation, category, and complex backgrounds, as well as the different camera sensors pose great challenges for current algorithms. In this work, we propose a new method consisting of a novel joint image cascade and feature pyramid network with multi-size convolution kernels to extract multi-scale strong and weak semantic features. These features are fed into rotation-based region proposal and region of interest networks to produce object detections. Finally, rotational non-maximum suppression is applied to remove redundant detections. During training, we minimize joint horizontal and oriented bounding box loss functions, as well as a novel loss that enforces oriented boxes to be rectangular. Our method achieves 68.16% mAP on horizontal and 72.45% mAP on oriented bounding box detection tasks on the challenging DOTA dataset, outperforming all published methods by a large margin (+6% and +12% absolute improvement, respectively). Furthermore, it generalizes to two other datasets, NWPU VHR-10 and UCAS-AOD, and achieves competitive results with the baselines even when trained on DOTA. Our method can be deployed in multi-class object detection applications, regardless of the image and object scales and orientations, making it a great choice for unconstrained aerial and satellite imagery.
Road Segmentation in SAR Satellite Images with Deep Fully-Convolutional Neural Networks
Aug 16, 2018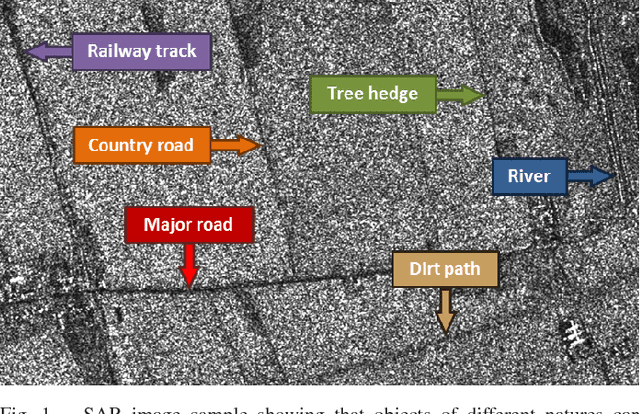

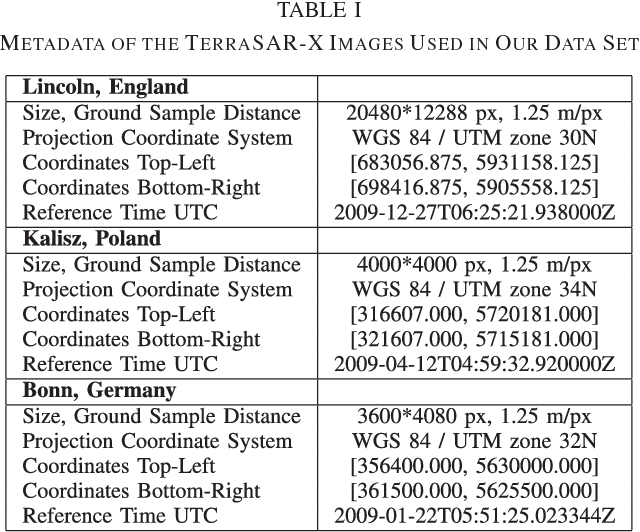
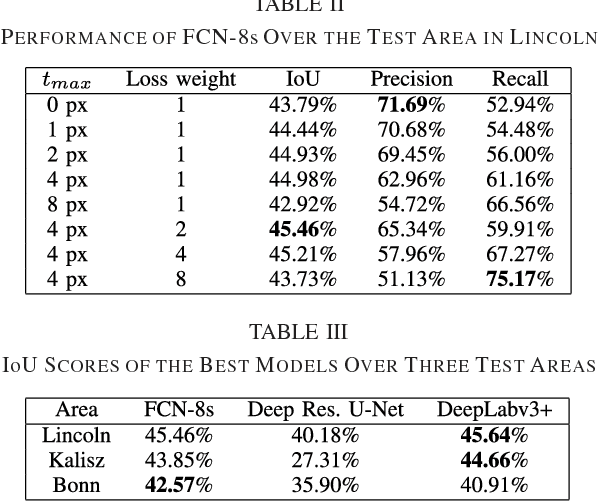
Remote sensing is extensively used in cartography. As transportation networks grow and change, extracting roads automatically from satellite images is crucial to keep maps up-to-date. Synthetic Aperture Radar satellites can provide high resolution topographical maps. However roads are difficult to identify in these data as they look visually similar to targets such as rivers and railways. Most road extraction methods on Synthetic Aperture Radar images still rely on a prior segmentation performed by classical computer vision algorithms. Few works study the potential of deep learning techniques, despite their successful applications to optical imagery. This letter presents an evaluation of Fully-Convolutional Neural Networks for road segmentation in SAR images. We study the relative performance of early and state-of-the-art networks after carefully enhancing their sensitivity towards thin objects by adding spatial tolerance rules. Our models shows promising results, successfully extracting most of the roads in our test dataset. This shows that, although Fully-Convolutional Neural Networks natively lack efficiency for road segmentation, they are capable of good results if properly tuned. As the segmentation quality does not scale well with the increasing depth of the networks, the design of specialized architectures for roads extraction should yield better performances.
Advanced Steel Microstructural Classification by Deep Learning Methods
Feb 15, 2018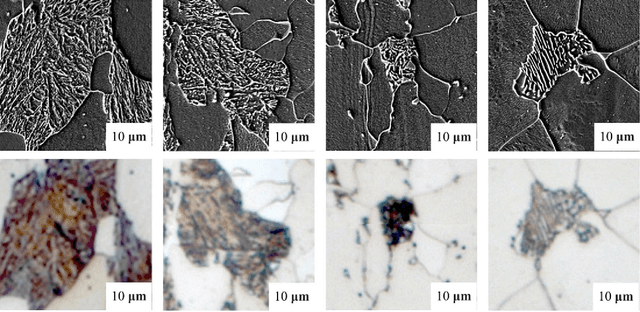


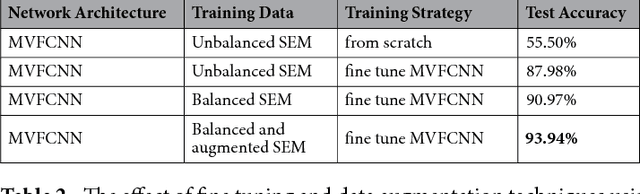
The inner structure of a material is called microstructure. It stores the genesis of a material and determines all its physical and chemical properties. While microstructural characterization is widely spread and well known, the microstructural classification is mostly done manually by human experts, which gives rise to uncertainties due to subjectivity. Since the microstructure could be a combination of different phases or constituents with complex substructures its automatic classification is very challenging and only a few prior studies exist. Prior works focused on designed and engineered features by experts and classified microstructures separately from the feature extraction step. Recently, Deep Learning methods have shown strong performance in vision applications by learning the features from data together with the classification step. In this work, we propose a Deep Learning method for microstructural classification in the examples of certain microstructural constituents of low carbon steel. This novel method employs pixel-wise segmentation via Fully Convolutional Neural Networks (FCNN) accompanied by a max-voting scheme. Our system achieves 93.94% classification accuracy, drastically outperforming the state-of-the-art method of 48.89% accuracy. Beyond the strong performance of our method, this line of research offers a more robust and first of all objective way for the difficult task of steel quality appreciation.