 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe 2nd Workshop on Maritime Computer Vision 2024
Nov 23, 2023



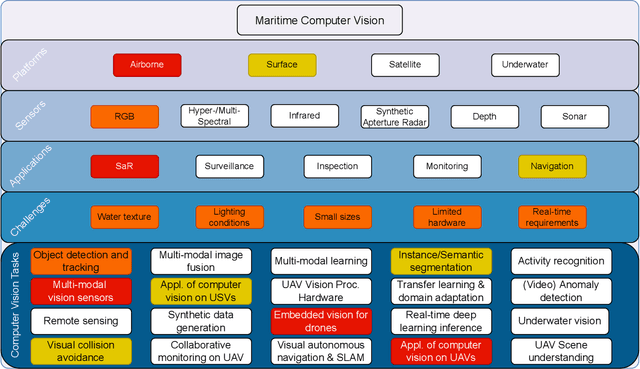
The 2nd Workshop on Maritime Computer Vision (MaCVi) 2024 addresses maritime computer vision for Unmanned Aerial Vehicles (UAV) and Unmanned Surface Vehicles (USV). Three challenges categories are considered: (i) UAV-based Maritime Object Tracking with Re-identification, (ii) USV-based Maritime Obstacle Segmentation and Detection, (iii) USV-based Maritime Boat Tracking. The USV-based Maritime Obstacle Segmentation and Detection features three sub-challenges, including a new embedded challenge addressing efficicent inference on real-world embedded devices. This report offers a comprehensive overview of the findings from the challenges. We provide both statistical and qualitative analyses, evaluating trends from over 195 submissions. All datasets, evaluation code, and the leaderboard are available to the public at https://macvi.org/workshop/macvi24.
1st Workshop on Maritime Computer Vision 2023: Challenge Results
Nov 28, 2022

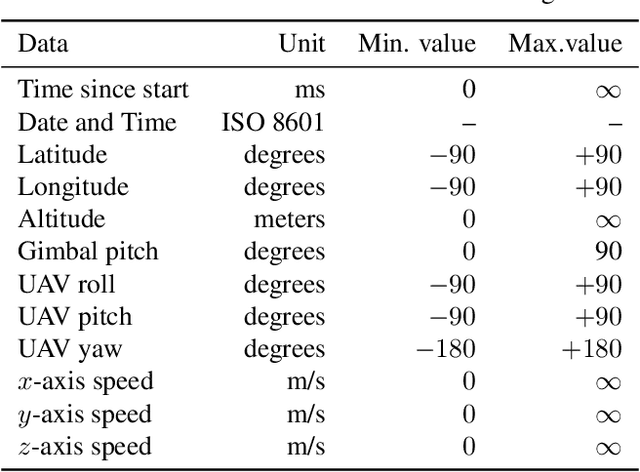
The 1$^{\text{st}}$ Workshop on Maritime Computer Vision (MaCVi) 2023 focused on maritime computer vision for Unmanned Aerial Vehicles (UAV) and Unmanned Surface Vehicle (USV), and organized several subchallenges in this domain: (i) UAV-based Maritime Object Detection, (ii) UAV-based Maritime Object Tracking, (iii) USV-based Maritime Obstacle Segmentation and (iv) USV-based Maritime Obstacle Detection. The subchallenges were based on the SeaDronesSee and MODS benchmarks. This report summarizes the main findings of the individual subchallenges and introduces a new benchmark, called SeaDronesSee Object Detection v2, which extends the previous benchmark by including more classes and footage. We provide statistical and qualitative analyses, and assess trends in the best-performing methodologies of over 130 submissions. The methods are summarized in the appendix. The datasets, evaluation code and the leaderboard are publicly available at https://seadronessee.cs.uni-tuebingen.de/macvi.
SkyScapes -- Fine-Grained Semantic Understanding of Aerial Scenes
Jul 12, 2020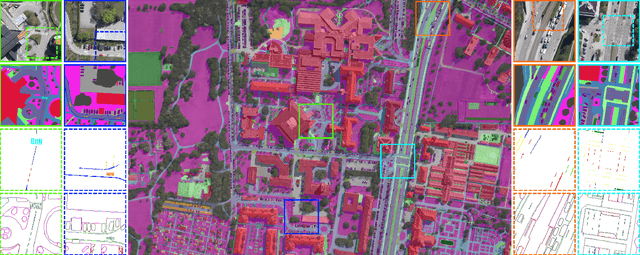
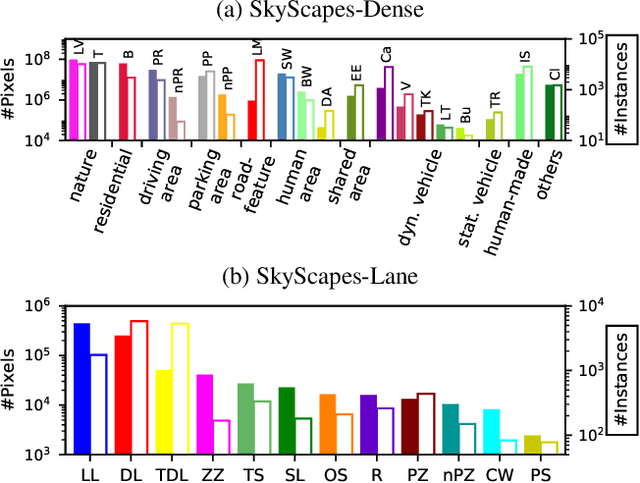
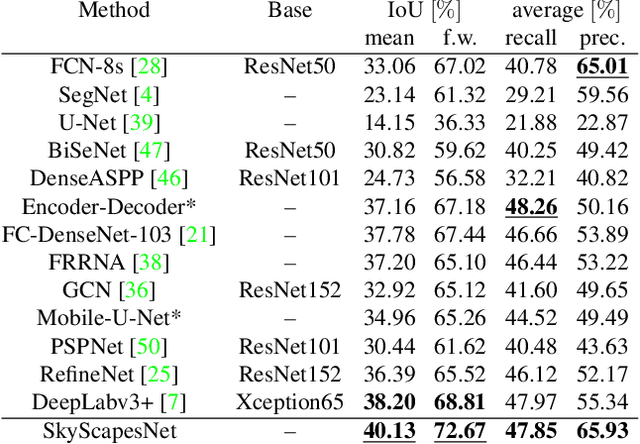
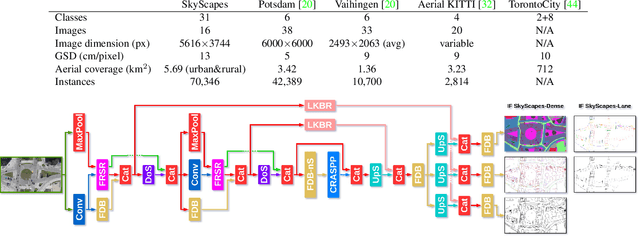
Understanding the complex urban infrastructure with centimeter-level accuracy is essential for many applications from autonomous driving to mapping, infrastructure monitoring, and urban management. Aerial images provide valuable information over a large area instantaneously; nevertheless, no current dataset captures the complexity of aerial scenes at the level of granularity required by real-world applications. To address this, we introduce SkyScapes, an aerial image dataset with highly-accurate, fine-grained annotations for pixel-level semantic labeling. SkyScapes provides annotations for 31 semantic categories ranging from large structures, such as buildings, roads and vegetation, to fine details, such as 12 (sub-)categories of lane markings. We have defined two main tasks on this dataset: dense semantic segmentation and multi-class lane-marking prediction. We carry out extensive experiments to evaluate state-of-the-art segmentation methods on SkyScapes. Existing methods struggle to deal with the wide range of classes, object sizes, scales, and fine details present. We therefore propose a novel multi-task model, which incorporates semantic edge detection and is better tuned for feature extraction from a wide range of scales. This model achieves notable improvements over the baselines in region outlines and level of detail on both tasks.
A Systematic Evaluation of Recent Deep Learning Architectures for Fine-Grained Vehicle Classification
Jun 08, 2018Fine-grained vehicle classification is the task of classifying make, model, and year of a vehicle. This is a very challenging task, because vehicles of different types but similar color and viewpoint can often look much more similar than vehicles of same type but differing color and viewpoint. Vehicle make, model, and year in com- bination with vehicle color - are of importance in several applications such as vehicle search, re-identification, tracking, and traffic analysis. In this work we investigate the suitability of several recent landmark convolutional neural network (CNN) architectures, which have shown top results on large scale image classification tasks, for the task of fine-grained classification of vehicles. We compare the performance of the networks VGG16, several ResNets, Inception architectures, the recent DenseNets, and MobileNet. For classification we use the Stanford Cars-196 dataset which features 196 different types of vehicles. We investigate several aspects of CNN training, such as data augmentation and training from scratch vs. fine-tuning. Importantly, we introduce no aspects in the architectures or training process which are specific to vehicle classification. Our final model achieves a state-of-the-art classification accuracy of 94.6% outperforming all related works, even approaches which are specifically tailored for the task, e.g. by including vehicle part detections.