 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Robustness and Chain-of-Thought Consistency of RL-Finetuned VLMs
Feb 13, 2026Reinforcement learning (RL) fine-tuning has become a key technique for enhancing large language models (LLMs) on reasoning-intensive tasks, motivating its extension to vision language models (VLMs). While RL-tuned VLMs improve on visual reasoning benchmarks, they remain vulnerable to weak visual grounding, hallucinations, and over-reliance on textual cues. We show that simple, controlled textual perturbations--misleading captions or incorrect chain-of-thought (CoT) traces--cause substantial drops in robustness and confidence, and that these effects are more pronounced when CoT consistency is taken into account across open-source multimodal reasoning models. Entropy-based metrics further show that these perturbations reshape model uncertainty and probability mass on the correct option, exposing model-specific trends in miscalibration. To better understand these vulnerabilities, we further analyze RL fine-tuning dynamics and uncover an accuracy-faithfulness trade-off: fine-tuning raises benchmark accuracy, but can simultaneously erode the reliability of the accompanying CoT and its robustness to contextual shifts. Although adversarial augmentation improves robustness, it does not by itself prevent faithfulness drift. Incorporating a faithfulness-aware reward can restore alignment between answers and reasoning, but when paired with augmentation, training risks collapsing onto shortcut strategies and robustness remains elusive. Together, these findings highlight the limitations of accuracy-only evaluations and motivate training and assessment protocols that jointly emphasize correctness, robustness, and the faithfulness of visually grounded reasoning.
UniHPR: Unified Human Pose Representation via Singular Value Contrastive Learning
Oct 21, 2025In recent years, there has been a growing interest in developing effective alignment pipelines to generate unified representations from different modalities for multi-modal fusion and generation. As an important component of Human-Centric applications, Human Pose representations are critical in many downstream tasks, such as Human Pose Estimation, Action Recognition, Human-Computer Interaction, Object tracking, etc. Human Pose representations or embeddings can be extracted from images, 2D keypoints, 3D skeletons, mesh models, and lots of other modalities. Yet, there are limited instances where the correlation among all of those representations has been clearly researched using a contrastive paradigm. In this paper, we propose UniHPR, a unified Human Pose Representation learning pipeline, which aligns Human Pose embeddings from images, 2D and 3D human poses. To align more than two data representations at the same time, we propose a novel singular value-based contrastive learning loss, which better aligns different modalities and further boosts performance. To evaluate the effectiveness of the aligned representation, we choose 2D and 3D Human Pose Estimation (HPE) as our evaluation tasks. In our evaluation, with a simple 3D human pose decoder, UniHPR achieves remarkable performance metrics: MPJPE 49.9mm on the Human3.6M dataset and PA-MPJPE 51.6mm on the 3DPW dataset with cross-domain evaluation. Meanwhile, we are able to achieve 2D and 3D pose retrieval with our unified human pose representations in Human3.6M dataset, where the retrieval error is 9.24mm in MPJPE.
Bayesian Optimization for Controlled Image Editing via LLMs
Feb 26, 2025



In the rapidly evolving field of image generation, achieving precise control over generated content and maintaining semantic consistency remain significant limitations, particularly concerning grounding techniques and the necessity for model fine-tuning. To address these challenges, we propose BayesGenie, an off-the-shelf approach that integrates Large Language Models (LLMs) with Bayesian Optimization to facilitate precise and user-friendly image editing. Our method enables users to modify images through natural language descriptions without manual area marking, while preserving the original image's semantic integrity. Unlike existing techniques that require extensive pre-training or fine-tuning, our approach demonstrates remarkable adaptability across various LLMs through its model-agnostic design. BayesGenie employs an adapted Bayesian optimization strategy to automatically refine the inference process parameters, achieving high-precision image editing with minimal user intervention. Through extensive experiments across diverse scenarios, we demonstrate that our framework significantly outperforms existing methods in both editing accuracy and semantic preservation, as validated using different LLMs including Claude3 and GPT-4.
PackDiT: Joint Human Motion and Text Generation via Mutual Prompting
Jan 27, 2025



Human motion generation has advanced markedly with the advent of diffusion models. Most recent studies have concentrated on generating motion sequences based on text prompts, commonly referred to as text-to-motion generation. However, the bidirectional generation of motion and text, enabling tasks such as motion-to-text alongside text-to-motion, has been largely unexplored. This capability is essential for aligning diverse modalities and supports unconditional generation. In this paper, we introduce PackDiT, the first diffusion-based generative model capable of performing various tasks simultaneously, including motion generation, motion prediction, text generation, text-to-motion, motion-to-text, and joint motion-text generation. Our core innovation leverages mutual blocks to integrate multiple diffusion transformers (DiTs) across different modalities seamlessly. We train PackDiT on the HumanML3D dataset, achieving state-of-the-art text-to-motion performance with an FID score of 0.106, along with superior results in motion prediction and in-between tasks. Our experiments further demonstrate that diffusion models are effective for motion-to-text generation, achieving performance comparable to that of autoregressive models.
Graph Canvas for Controllable 3D Scene Generation
Nov 27, 2024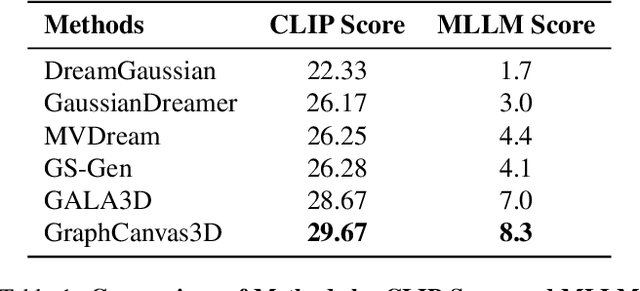
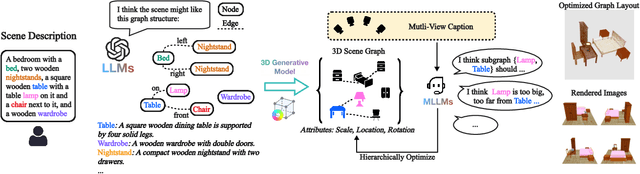
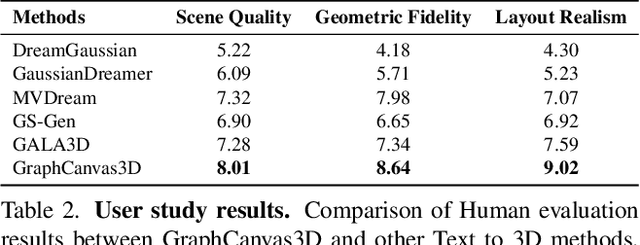
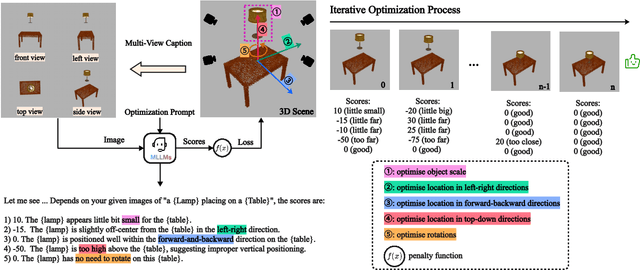
Spatial intelligence is foundational to AI systems that interact with the physical world, particularly in 3D scene generation and spatial comprehension. Current methodologies for 3D scene generation often rely heavily on predefined datasets, and struggle to adapt dynamically to changing spatial relationships. In this paper, we introduce \textbf{GraphCanvas3D}, a programmable, extensible, and adaptable framework for controllable 3D scene generation. Leveraging in-context learning, GraphCanvas3D enables dynamic adaptability without the need for retraining, supporting flexible and customizable scene creation. Our framework employs hierarchical, graph-driven scene descriptions, representing spatial elements as graph nodes and establishing coherent relationships among objects in 3D environments. Unlike conventional approaches, which are constrained in adaptability and often require predefined input masks or retraining for modifications, GraphCanvas3D allows for seamless object manipulation and scene adjustments on the fly. Additionally, GraphCanvas3D supports 4D scene generation, incorporating temporal dynamics to model changes over time. Experimental results and user studies demonstrate that GraphCanvas3D enhances usability, flexibility, and adaptability for scene generation. Our code and models are available on the project website: https://github.com/ILGLJ/Graph-Canvas.
Human Motion Instruction Tuning
Nov 25, 2024



This paper presents LLaMo (Large Language and Human Motion Assistant), a multimodal framework for human motion instruction tuning. In contrast to conventional instruction-tuning approaches that convert non-linguistic inputs, such as video or motion sequences, into language tokens, LLaMo retains motion in its native form for instruction tuning. This method preserves motion-specific details that are often diminished in tokenization, thereby improving the model's ability to interpret complex human behaviors. By processing both video and motion data alongside textual inputs, LLaMo enables a flexible, human-centric analysis. Experimental evaluations across high-complexity domains, including human behaviors and professional activities, indicate that LLaMo effectively captures domain-specific knowledge, enhancing comprehension and prediction in motion-intensive scenarios. We hope LLaMo offers a foundation for future multimodal AI systems with broad applications, from sports analytics to behavioral prediction. Our code and models are available on the project website: https://github.com/ILGLJ/LLaMo.
SAMURAI: Adapting Segment Anything Model for Zero-Shot Visual Tracking with Motion-Aware Memory
Nov 18, 2024The Segment Anything Model 2 (SAM 2) has demonstrated strong performance in object segmentation tasks but faces challenges in visual object tracking, particularly when managing crowded scenes with fast-moving or self-occluding objects. Furthermore, the fixed-window memory approach in the original model does not consider the quality of memories selected to condition the image features for the next frame, leading to error propagation in videos. This paper introduces SAMURAI, an enhanced adaptation of SAM 2 specifically designed for visual object tracking. By incorporating temporal motion cues with the proposed motion-aware memory selection mechanism, SAMURAI effectively predicts object motion and refines mask selection, achieving robust, accurate tracking without the need for retraining or fine-tuning. SAMURAI operates in real-time and demonstrates strong zero-shot performance across diverse benchmark datasets, showcasing its ability to generalize without fine-tuning. In evaluations, SAMURAI achieves significant improvements in success rate and precision over existing trackers, with a 7.1% AUC gain on LaSOT$_{\text{ext}}$ and a 3.5% AO gain on GOT-10k. Moreover, it achieves competitive results compared to fully supervised methods on LaSOT, underscoring its robustness in complex tracking scenarios and its potential for real-world applications in dynamic environments. Code and results are available at https://github.com/yangchris11/samurai.
GTA: Global Tracklet Association for Multi-Object Tracking in Sports
Nov 12, 2024



Multi-object tracking in sports scenarios has become one of the focal points in computer vision, experiencing significant advancements through the integration of deep learning techniques. Despite these breakthroughs, challenges remain, such as accurately re-identifying players upon re-entry into the scene and minimizing ID switches. In this paper, we propose an appearance-based global tracklet association algorithm designed to enhance tracking performance by splitting tracklets containing multiple identities and connecting tracklets seemingly from the same identity. This method can serve as a plug-and-play refinement tool for any multi-object tracker to further boost their performance. The proposed method achieved a new state-of-the-art performance on the SportsMOT dataset with HOTA score of 81.04%. Similarly, on the SoccerNet dataset, our method enhanced multiple trackers' performance, consistently increasing the HOTA score from 79.41% to 83.11%. These significant and consistent improvements across different trackers and datasets underscore our proposed method's potential impact on the application of sports player tracking. We open-source our project codebase at https://github.com/sjc042/gta-link.git.
The Role of Deductive and Inductive Reasoning in Large Language Models
Oct 03, 2024



Large Language Models (LLMs) have achieved substantial progress in artificial intelligence, particularly in reasoning tasks. However, their reliance on static prompt structures, coupled with limited dynamic reasoning capabilities, often constrains their adaptability to complex and evolving problem spaces. In this paper, we propose the Deductive and InDuctive(DID) method, which enhances LLM reasoning by dynamically integrating both deductive and inductive reasoning within the prompt construction process. Drawing inspiration from cognitive science, the DID approach mirrors human adaptive reasoning mechanisms, offering a flexible framework that allows the model to adjust its reasoning pathways based on task context and performance. We empirically validate the efficacy of DID on established datasets such as AIW and MR-GSM8K, as well as on our custom dataset, Holiday Puzzle, which presents tasks about different holiday date calculating challenges. By leveraging DID's hybrid prompt strategy, we demonstrate significant improvements in both solution accuracy and reasoning quality, achieved without imposing substantial computational overhead. Our findings suggest that DID provides a more robust and cognitively aligned framework for reasoning in LLMs, contributing to the development of advanced LLM-driven problem-solving strategies informed by cognitive science models.
ToddlerAct: A Toddler Action Recognition Dataset for Gross Motor Development Assessment
Aug 31, 2024Assessing gross motor development in toddlers is crucial for understanding their physical development and identifying potential developmental delays or disorders. However, existing datasets for action recognition primarily focus on adults, lacking the diversity and specificity required for accurate assessment in toddlers. In this paper, we present ToddlerAct, a toddler gross motor action recognition dataset, aiming to facilitate research in early childhood development. The dataset consists of video recordings capturing a variety of gross motor activities commonly observed in toddlers aged under three years old. We describe the data collection process, annotation methodology, and dataset characteristics. Furthermore, we benchmarked multiple state-of-the-art methods including image-based and skeleton-based action recognition methods on our datasets. Our findings highlight the importance of domain-specific datasets for accurate assessment of gross motor development in toddlers and lay the foundation for future research in this critical area. Our dataset will be available at https://github.com/ipl-uw/ToddlerAct.