 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Sliced-Wasserstein Framework on Correlation Matrices for EEG Decoding
Jun 04, 2026Electroencephalography (EEG) offers noninvasive, millisecond resolution recordings of neuronal activity and is widely used in neuroscience and healthcare. Many EEG decoding pipelines rely on covariance descriptors for their robustness to noise, but such representations are sensitive to channel-wise scaling. Recent studies have therefore advocated full-rank correlation matrices as a scale-invariant alternative for EEG decoding. In this paper, we propose a general framework for Sliced Wasserstein (SW) discrepancies on manifolds endowed with Pullback Euclidean Metrics (PEMs), termed Pullback Euclidean Metric Sliced Wasserstein (PEMSW). Within this framework, we instantiate two Correlation Sliced-Wasserstein (CorSW) discrepancies on the manifold of full-rank correlation matrices under two recently introduced correlation geometries, \textit{i.e.}, the Off-Log Metric (OLM) and Log-Scaled Metric (LSM). Building on CorSW, we further develop a domain generalization (DG) framework for EEG decoding. Experiments on three EEG datasets demonstrate improved generalization under distribution shifts, with low training overhead and no additional inference cost. The source code is available at https://github.com/ChenHu-ML/CorSW.
Unified Value Alignment for Generative Recommendation in Industrial Advertising
May 07, 2026Generative Recommendation (GR) reformulates recommendation as a next-token generation problem and has shown promise in industrial applications. However, extending GR to industrial advertising is non-trivial because the system must optimize not only user interest but also commercial value. Existing GR pipelines remain largely semantics-centric, making it difficult to align value signals across tokenization, decoding, and online serving. To address this issue, we propose UniVA, a Unified Value Alignment framework for advertising recommendation. We first introduce a Commercial SID tokenizer that injects value-related attributes into SID construction, yielding value-discriminative item representations. We then develop a Generation-as-Ranking SID Decoder jointly optimized by supervised learning and eCPM-aware reinforcement learning, which fuses value scores into next-item SID generation to perform generation and ranking in one decoding process. Finally, we design a value-guided personalized beam search that reuses generation-as-ranking logits as online value guidance and applies a personalized trie tree to constrain decoding to request-valid SID paths. Experiments on the Tencent WeChat Channels advertising platform show that UniVA achieves a 37.04\% improvement in offline Hit Rate@100 over the baseline and a 1.5\% GMV lift in online A/B tests.
RAM: Recover Any 3D Human Motion in-the-Wild
Mar 20, 2026RAM incorporates a motion-aware semantic tracker with adaptive Kalman filtering to achieve robust identity association under severe occlusions and dynamic interactions. A memory-augmented Temporal HMR module further enhances human motion reconstruction by injecting spatio-temporal priors for consistent and smooth motion estimation. Moreover, a lightweight Predictor module forecasts future poses to maintain reconstruction continuity, while a gated combiner adaptively fuses reconstructed and predicted features to ensure coherence and robustness. Experiments on in-the-wild multi-person benchmarks such as PoseTrack and 3DPW, demonstrate that RAM substantially outperforms previous state-of-the-art in both Zero-shot tracking stability and 3D accuracy, offering a generalizable paradigm for markerless 3D human motion capture in-the-wild.
Multimodal Mixture-of-Experts with Retrieval Augmentation for Protein Active Site Identification
Mar 02, 2026Accurate identification of protein active sites at the residue level is crucial for understanding protein function and advancing drug discovery. However, current methods face two critical challenges: vulnerability in single-instance prediction due to sparse training data, and inadequate modality reliability estimation that leads to performance degradation when unreliable modalities dominate fusion processes. To address these challenges, we introduce Multimodal Mixture-of-Experts with Retrieval Augmentation (MERA), the first retrieval-augmented framework for protein active site identification. MERA employs hierarchical multi-expert retrieval that dynamically aggregates contextual information from chain, sequence, and active-site perspectives through residue-level mixture-of-experts gating. To prevent modality degradation, we propose a reliability-aware fusion strategy based on Dempster-Shafer evidence theory that quantifies modality trustworthiness through belief mass functions and learnable discounting coefficients, enabling principled multimodal integration. Extensive experiments on ProTAD-Gen and TS125 datasets demonstrate that MERA achieves state-of-the-art performance, with 90% AUPRC on active site prediction and significant gains on peptide-binding site identification, validating the effectiveness of retrieval-augmented multi-expert modeling and reliability-guided fusion.
PSGS: Text-driven Panorama Sliding Scene Generation via Gaussian Splatting
Jan 31, 2026Generating realistic 3D scenes from text is crucial for immersive applications like VR, AR, and gaming. While text-driven approaches promise efficiency, existing methods suffer from limited 3D-text data and inconsistent multi-view stitching, resulting in overly simplistic scenes. To address this, we propose PSGS, a two-stage framework for high-fidelity panoramic scene generation. First, a novel two-layer optimization architecture generates semantically coherent panoramas: a layout reasoning layer parses text into structured spatial relationships, while a self-optimization layer refines visual details via iterative MLLM feedback. Second, our panorama sliding mechanism initializes globally consistent 3D Gaussian Splatting point clouds by strategically sampling overlapping perspectives. By incorporating depth and semantic coherence losses during training, we greatly improve the quality and detail fidelity of rendered scenes. Our experiments demonstrate that PSGS outperforms existing methods in panorama generation and produces more appealing 3D scenes, offering a robust solution for scalable immersive content creation.
StegaVAR: Privacy-Preserving Video Action Recognition via Steganographic Domain Analysis
Dec 14, 2025



Despite the rapid progress of deep learning in video action recognition (VAR) in recent years, privacy leakage in videos remains a critical concern. Current state-of-the-art privacy-preserving methods often rely on anonymization. These methods suffer from (1) low concealment, where producing visually distorted videos that attract attackers' attention during transmission, and (2) spatiotemporal disruption, where degrading essential spatiotemporal features for accurate VAR. To address these issues, we propose StegaVAR, a novel framework that embeds action videos into ordinary cover videos and directly performs VAR in the steganographic domain for the first time. Throughout both data transmission and action analysis, the spatiotemporal information of hidden secret video remains complete, while the natural appearance of cover videos ensures the concealment of transmission. Considering the difficulty of steganographic domain analysis, we propose Secret Spatio-Temporal Promotion (STeP) and Cross-Band Difference Attention (CroDA) for analysis within the steganographic domain. STeP uses the secret video to guide spatiotemporal feature extraction in the steganographic domain during training. CroDA suppresses cover interference by capturing cross-band semantic differences. Experiments demonstrate that StegaVAR achieves superior VAR and privacy-preserving performance on widely used datasets. Moreover, our framework is effective for multiple steganographic models.
Learning Representation and Synergy Invariances: A Povable Framework for Generalized Multimodal Face Anti-Spoofing
Nov 18, 2025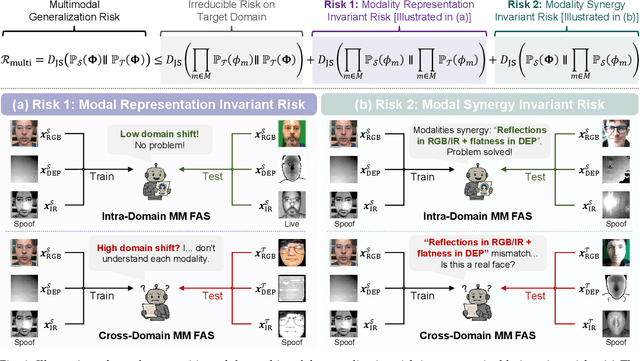

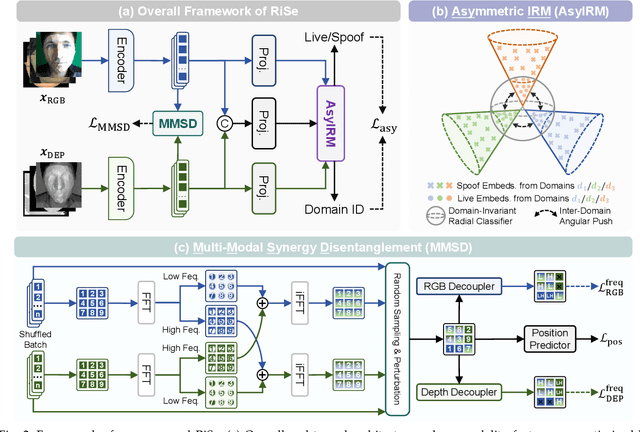
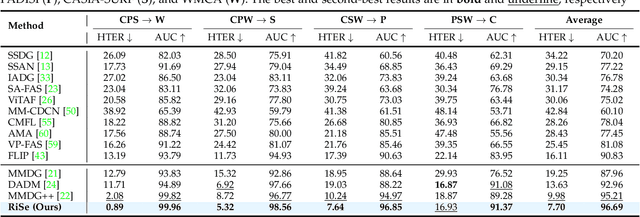
Multimodal Face Anti-Spoofing (FAS) methods, which integrate multiple visual modalities, often suffer even more severe performance degradation than unimodal FAS when deployed in unseen domains. This is mainly due to two overlooked risks that affect cross-domain multimodal generalization. The first is the modal representation invariant risk, i.e., whether representations remain generalizable under domain shift. We theoretically show that the inherent class asymmetry in FAS (diverse spoofs vs. compact reals) enlarges the upper bound of generalization error, and this effect is further amplified in multimodal settings. The second is the modal synergy invariant risk, where models overfit to domain-specific inter-modal correlations. Such spurious synergy cannot generalize to unseen attacks in target domains, leading to performance drops. To solve these issues, we propose a provable framework, namely Multimodal Representation and Synergy Invariance Learning (RiSe). For representation risk, RiSe introduces Asymmetric Invariant Risk Minimization (AsyIRM), which learns an invariant spherical decision boundary in radial space to fit asymmetric distributions, while preserving domain cues in angular space. For synergy risk, RiSe employs Multimodal Synergy Disentanglement (MMSD), a self-supervised task enhancing intrinsic, generalizable modal features via cross-sample mixing and disentanglement. Theoretical analysis and experiments verify RiSe, which achieves state-of-the-art cross-domain performance.
Causal Reasoning Elicits Controllable 3D Scene Generation
Sep 18, 2025



Existing 3D scene generation methods often struggle to model the complex logical dependencies and physical constraints between objects, limiting their ability to adapt to dynamic and realistic environments. We propose CausalStruct, a novel framework that embeds causal reasoning into 3D scene generation. Utilizing large language models (LLMs), We construct causal graphs where nodes represent objects and attributes, while edges encode causal dependencies and physical constraints. CausalStruct iteratively refines the scene layout by enforcing causal order to determine the placement order of objects and applies causal intervention to adjust the spatial configuration according to physics-driven constraints, ensuring consistency with textual descriptions and real-world dynamics. The refined scene causal graph informs subsequent optimization steps, employing a Proportional-Integral-Derivative(PID) controller to iteratively tune object scales and positions. Our method uses text or images to guide object placement and layout in 3D scenes, with 3D Gaussian Splatting and Score Distillation Sampling improving shape accuracy and rendering stability. Extensive experiments show that CausalStruct generates 3D scenes with enhanced logical coherence, realistic spatial interactions, and robust adaptability.
Mind2Matter: Creating 3D Models from EEG Signals
Apr 16, 2025The reconstruction of 3D objects from brain signals has gained significant attention in brain-computer interface (BCI) research. Current research predominantly utilizes functional magnetic resonance imaging (fMRI) for 3D reconstruction tasks due to its excellent spatial resolution. Nevertheless, the clinical utility of fMRI is limited by its prohibitive costs and inability to support real-time operations. In comparison, electroencephalography (EEG) presents distinct advantages as an affordable, non-invasive, and mobile solution for real-time brain-computer interaction systems. While recent advances in deep learning have enabled remarkable progress in image generation from neural data, decoding EEG signals into structured 3D representations remains largely unexplored. In this paper, we propose a novel framework that translates EEG recordings into 3D object reconstructions by leveraging neural decoding techniques and generative models. Our approach involves training an EEG encoder to extract spatiotemporal visual features, fine-tuning a large language model to interpret these features into descriptive multimodal outputs, and leveraging generative 3D Gaussians with layout-guided control to synthesize the final 3D structures. Experiments demonstrate that our model captures salient geometric and semantic features, paving the way for applications in brain-computer interfaces (BCIs), virtual reality, and neuroprosthetics.Our code is available in https://github.com/sddwwww/Mind2Matter.
Dense Point Clouds Matter: Dust-GS for Scene Reconstruction from Sparse Viewpoints
Sep 13, 2024



3D Gaussian Splatting (3DGS) has demonstrated remarkable performance in scene synthesis and novel view synthesis tasks. Typically, the initialization of 3D Gaussian primitives relies on point clouds derived from Structure-from-Motion (SfM) methods. However, in scenarios requiring scene reconstruction from sparse viewpoints, the effectiveness of 3DGS is significantly constrained by the quality of these initial point clouds and the limited number of input images. In this study, we present Dust-GS, a novel framework specifically designed to overcome the limitations of 3DGS in sparse viewpoint conditions. Instead of relying solely on SfM, Dust-GS introduces an innovative point cloud initialization technique that remains effective even with sparse input data. Our approach leverages a hybrid strategy that integrates an adaptive depth-based masking technique, thereby enhancing the accuracy and detail of reconstructed scenes. Extensive experiments conducted on several benchmark datasets demonstrate that Dust-GS surpasses traditional 3DGS methods in scenarios with sparse viewpoints, achieving superior scene reconstruction quality with a reduced number of input images.