 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEquivariant Learning for Unsupervised Image Dehazing
Jan 20, 2026Image Dehazing (ID) aims to produce a clear image from an observation contaminated by haze. Current ID methods typically rely on carefully crafted priors or extensive haze-free ground truth, both of which are expensive or impractical to acquire, particularly in the context of scientific imaging. We propose a new unsupervised learning framework called Equivariant Image Dehazing (EID) that exploits the symmetry of image signals to restore clarity to hazy observations. By enforcing haze consistency and systematic equivariance, EID can recover clear patterns directly from raw, hazy images. Additionally, we propose an adversarial learning strategy to model unknown haze physics and facilitate EID learning. Experiments on two scientific image dehazing benchmarks (including cell microscopy and medical endoscopy) and on natural image dehazing have demonstrated that EID significantly outperforms state-of-the-art approaches. By unifying equivariant learning with modelling haze physics, we hope that EID will enable more versatile and effective haze removal in scientific imaging. Code and datasets will be published.
SHARE: A Fully Unsupervised Framework for Single Hyperspectral Image Restoration
Jan 20, 2026Hyperspectral image (HSI) restoration is a fundamental challenge in computational imaging and computer vision. It involves ill-posed inverse problems, such as inpainting and super-resolution. Although deep learning methods have transformed the field through data-driven learning, their effectiveness hinges on access to meticulously curated ground-truth datasets. This fundamentally restricts their applicability in real-world scenarios where such data is unavailable. This paper presents SHARE (Single Hyperspectral Image Restoration with Equivariance), a fully unsupervised framework that unifies geometric equivariance principles with low-rank spectral modelling to eliminate the need for ground truth. SHARE's core concept is to exploit the intrinsic invariance of hyperspectral structures under differentiable geometric transformations (e.g. rotations and scaling) to derive self-supervision signals through equivariance consistency constraints. Our novel Dynamic Adaptive Spectral Attention (DASA) module further enhances this paradigm shift by explicitly encoding the global low-rank property of HSI and adaptively refining local spectral-spatial correlations through learnable attention mechanisms. Extensive experiments on HSI inpainting and super-resolution tasks demonstrate the effectiveness of SHARE. Our method outperforms many state-of-the-art unsupervised approaches and achieves performance comparable to that of supervised methods. We hope that our approach will shed new light on HSI restoration and broader scientific imaging scenarios. The code will be released at https://github.com/xuwayyy/SHARE.
Wavelet-based Bi-dimensional Aggregation Network for SAR Image Change Detection
Jul 18, 2024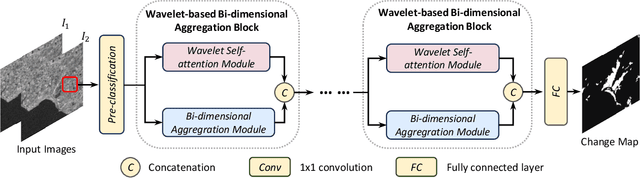
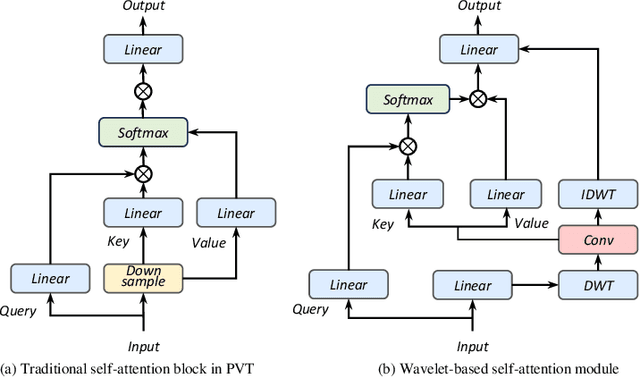
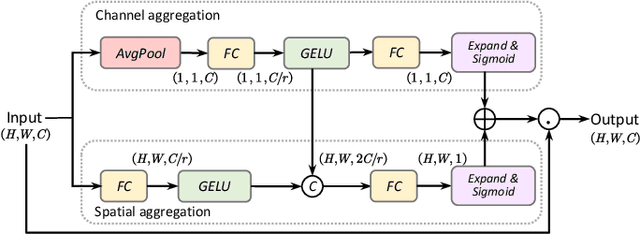

Synthetic aperture radar (SAR) image change detection is critical in remote sensing image analysis. Recently, the attention mechanism has been widely used in change detection tasks. However, existing attention mechanisms often employ down-sampling operations such as average pooling on the Key and Value components to enhance computational efficiency. These irreversible operations result in the loss of high-frequency components and other important information. To address this limitation, we develop Wavelet-based Bi-dimensional Aggregation Network (WBANet) for SAR image change detection. We design a wavelet-based self-attention block that includes discrete wavelet transform and inverse discrete wavelet transform operations on Key and Value components. Hence, the feature undergoes downsampling without any loss of information, while simultaneously enhancing local contextual awareness through an expanded receptive field. Additionally, we have incorporated a bi-dimensional aggregation module that boosts the non-linear representation capability by merging spatial and channel information via broadcast mechanism. Experimental results on three SAR datasets demonstrate that our WBANet significantly outperforms contemporary state-of-the-art methods. Specifically, our WBANet achieves 98.33\%, 96.65\%, and 96.62\% of percentage of correct classification (PCC) on the respective datasets, highlighting its superior performance. Source codes are available at \url{https://github.com/summitgao/WBANet}.
DriveMLM: Aligning Multi-Modal Large Language Models with Behavioral Planning States for Autonomous Driving
Dec 25, 2023

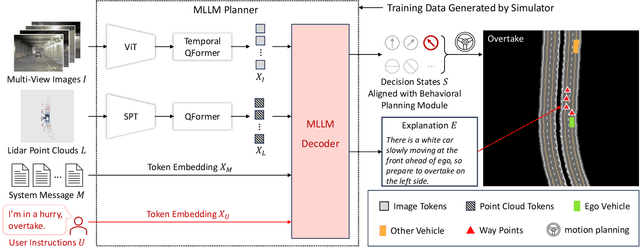
Large language models (LLMs) have opened up new possibilities for intelligent agents, endowing them with human-like thinking and cognitive abilities. In this work, we delve into the potential of large language models (LLMs) in autonomous driving (AD). We introduce DriveMLM, an LLM-based AD framework that can perform close-loop autonomous driving in realistic simulators. To this end, (1) we bridge the gap between the language decisions and the vehicle control commands by standardizing the decision states according to the off-the-shelf motion planning module. (2) We employ a multi-modal LLM (MLLM) to model the behavior planning module of a module AD system, which uses driving rules, user commands, and inputs from various sensors (e.g., camera, lidar) as input and makes driving decisions and provide explanations; This model can plug-and-play in existing AD systems such as Apollo for close-loop driving. (3) We design an effective data engine to collect a dataset that includes decision state and corresponding explanation annotation for model training and evaluation. We conduct extensive experiments and show that our model achieves 76.1 driving score on the CARLA Town05 Long, and surpasses the Apollo baseline by 4.7 points under the same settings, demonstrating the effectiveness of our model. We hope this work can serve as a baseline for autonomous driving with LLMs. Code and models shall be released at https://github.com/OpenGVLab/DriveMLM.
Think Twice before Driving: Towards Scalable Decoders for End-to-End Autonomous Driving
May 10, 2023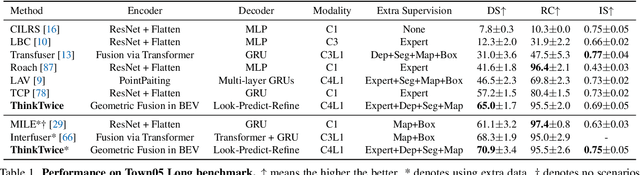
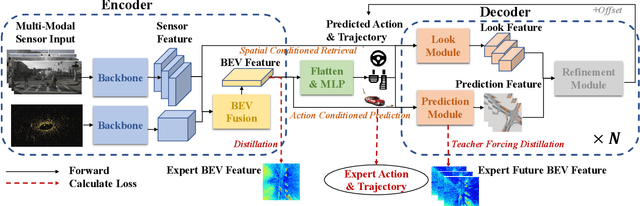

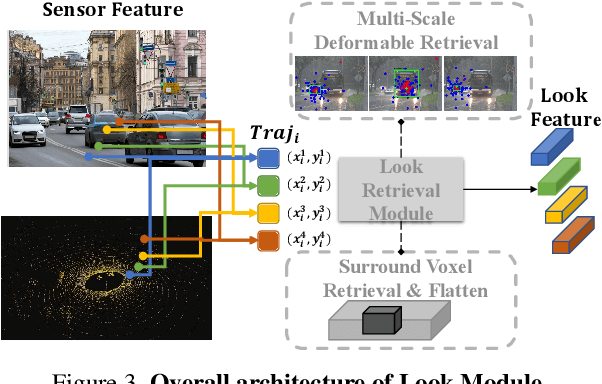
End-to-end autonomous driving has made impressive progress in recent years. Existing methods usually adopt the decoupled encoder-decoder paradigm, where the encoder extracts hidden features from raw sensor data, and the decoder outputs the ego-vehicle's future trajectories or actions. Under such a paradigm, the encoder does not have access to the intended behavior of the ego agent, leaving the burden of finding out safety-critical regions from the massive receptive field and inferring about future situations to the decoder. Even worse, the decoder is usually composed of several simple multi-layer perceptrons (MLP) or GRUs while the encoder is delicately designed (e.g., a combination of heavy ResNets or Transformer). Such an imbalanced resource-task division hampers the learning process. In this work, we aim to alleviate the aforementioned problem by two principles: (1) fully utilizing the capacity of the encoder; (2) increasing the capacity of the decoder. Concretely, we first predict a coarse-grained future position and action based on the encoder features. Then, conditioned on the position and action, the future scene is imagined to check the ramification if we drive accordingly. We also retrieve the encoder features around the predicted coordinate to obtain fine-grained information about the safety-critical region. Finally, based on the predicted future and the retrieved salient feature, we refine the coarse-grained position and action by predicting its offset from ground-truth. The above refinement module could be stacked in a cascaded fashion, which extends the capacity of the decoder with spatial-temporal prior knowledge about the conditioned future. We conduct experiments on the CARLA simulator and achieve state-of-the-art performance in closed-loop benchmarks. Extensive ablation studies demonstrate the effectiveness of each proposed module.
3D Data Augmentation for Driving Scenes on Camera
Mar 18, 2023



Driving scenes are extremely diverse and complicated that it is impossible to collect all cases with human effort alone. While data augmentation is an effective technique to enrich the training data, existing methods for camera data in autonomous driving applications are confined to the 2D image plane, which may not optimally increase data diversity in 3D real-world scenarios. To this end, we propose a 3D data augmentation approach termed Drive-3DAug, aiming at augmenting the driving scenes on camera in the 3D space. We first utilize Neural Radiance Field (NeRF) to reconstruct the 3D models of background and foreground objects. Then, augmented driving scenes can be obtained by placing the 3D objects with adapted location and orientation at the pre-defined valid region of backgrounds. As such, the training database could be effectively scaled up. However, the 3D object modeling is constrained to the image quality and the limited viewpoints. To overcome these problems, we modify the original NeRF by introducing a geometric rectified loss and a symmetric-aware training strategy. We evaluate our method for the camera-only monocular 3D detection task on the Waymo and nuScences datasets. The proposed data augmentation approach contributes to a gain of 1.7% and 1.4% in terms of detection accuracy, on Waymo and nuScences respectively. Furthermore, the constructed 3D models serve as digital driving assets and could be recycled for different detectors or other 3D perception tasks.
General Incremental Learning with Domain-aware Categorical Representations
Apr 08, 2022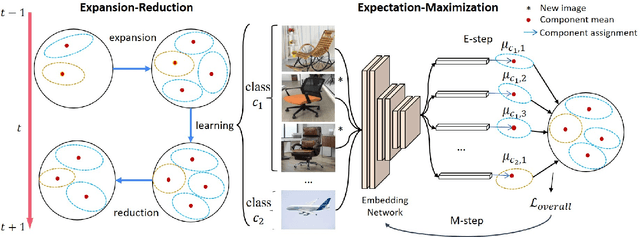
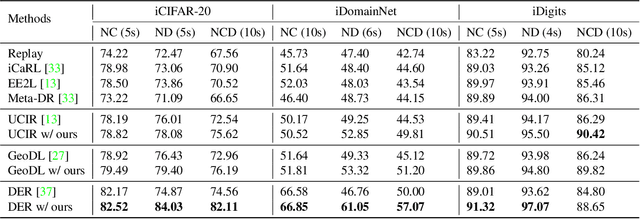
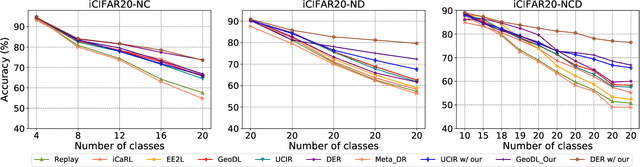

Continual learning is an important problem for achieving human-level intelligence in real-world applications as an agent must continuously accumulate knowledge in response to streaming data/tasks. In this work, we consider a general and yet under-explored incremental learning problem in which both the class distribution and class-specific domain distribution change over time. In addition to the typical challenges in class incremental learning, this setting also faces the intra-class stability-plasticity dilemma and intra-class domain imbalance problems. To address above issues, we develop a novel domain-aware continual learning method based on the EM framework. Specifically, we introduce a flexible class representation based on the von Mises-Fisher mixture model to capture the intra-class structure, using an expansion-and-reduction strategy to dynamically increase the number of components according to the class complexity. Moreover, we design a bi-level balanced memory to cope with data imbalances within and across classes, which combines with a distillation loss to achieve better inter- and intra-class stability-plasticity trade-off. We conduct exhaustive experiments on three benchmarks: iDigits, iDomainNet and iCIFAR-20. The results show that our approach consistently outperforms previous methods by a significant margin, demonstrating its superiority.
An EM Framework for Online Incremental Learning of Semantic Segmentation
Aug 08, 2021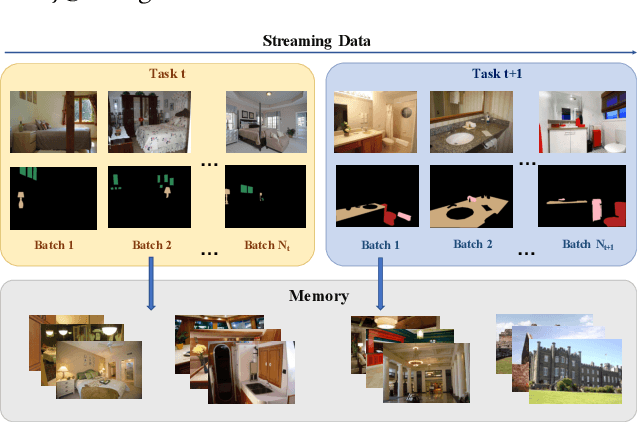
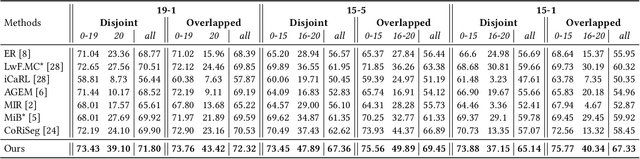
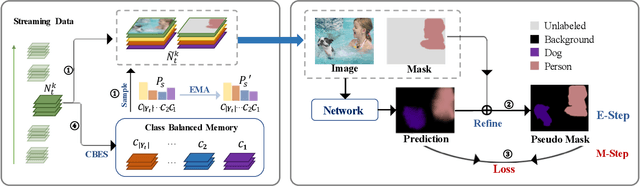
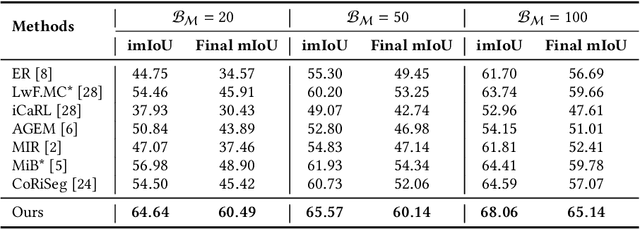
Incremental learning of semantic segmentation has emerged as a promising strategy for visual scene interpretation in the open- world setting. However, it remains challenging to acquire novel classes in an online fashion for the segmentation task, mainly due to its continuously-evolving semantic label space, partial pixelwise ground-truth annotations, and constrained data availability. To ad- dress this, we propose an incremental learning strategy that can fast adapt deep segmentation models without catastrophic forgetting, using a streaming input data with pixel annotations on the novel classes only. To this end, we develop a uni ed learning strategy based on the Expectation-Maximization (EM) framework, which integrates an iterative relabeling strategy that lls in the missing labels and a rehearsal-based incremental learning step that balances the stability-plasticity of the model. Moreover, our EM algorithm adopts an adaptive sampling method to select informative train- ing data and a class-balancing training strategy in the incremental model updates, both improving the e cacy of model learning. We validate our approach on the PASCAL VOC 2012 and ADE20K datasets, and the results demonstrate its superior performance over the existing incremental methods.
DER: Dynamically Expandable Representation for Class Incremental Learning
Mar 31, 2021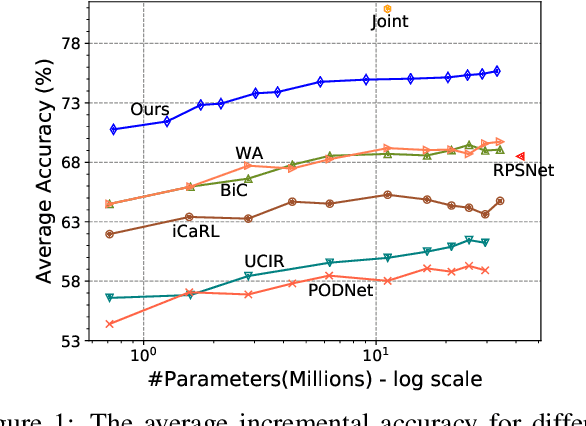
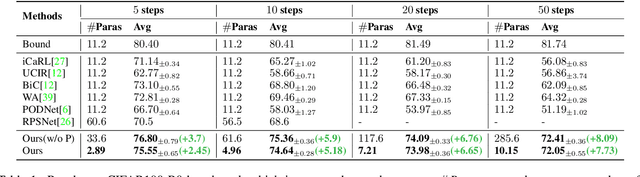
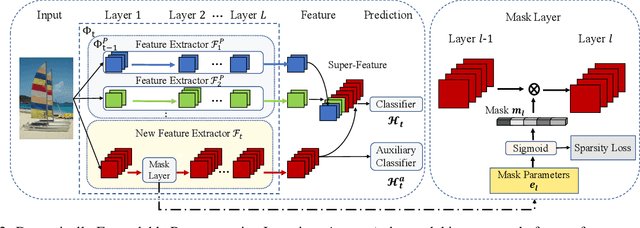

We address the problem of class incremental learning, which is a core step towards achieving adaptive vision intelligence. In particular, we consider the task setting of incremental learning with limited memory and aim to achieve better stability-plasticity trade-off. To this end, we propose a novel two-stage learning approach that utilizes a dynamically expandable representation for more effective incremental concept modeling. Specifically, at each incremental step, we freeze the previously learned representation and augment it with additional feature dimensions from a new learnable feature extractor. This enables us to integrate new visual concepts with retaining learned knowledge. We dynamically expand the representation according to the complexity of novel concepts by introducing a channel-level mask-based pruning strategy. Moreover, we introduce an auxiliary loss to encourage the model to learn diverse and discriminate features for novel concepts. We conduct extensive experiments on the three class incremental learning benchmarks and our method consistently outperforms other methods with a large margin.