 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse Video Generation Propels Real-World Beyond-the-View Vision-Language Navigation
Feb 05, 2026Why must vision-language navigation be bound to detailed and verbose language instructions? While such details ease decision-making, they fundamentally contradict the goal for navigation in the real-world. Ideally, agents should possess the autonomy to navigate in unknown environments guided solely by simple and high-level intents. Realizing this ambition introduces a formidable challenge: Beyond-the-View Navigation (BVN), where agents must locate distant, unseen targets without dense and step-by-step guidance. Existing large language model (LLM)-based methods, though adept at following dense instructions, often suffer from short-sighted behaviors due to their reliance on short-horimzon supervision. Simply extending the supervision horizon, however, destabilizes LLM training. In this work, we identify that video generation models inherently benefit from long-horizon supervision to align with language instructions, rendering them uniquely suitable for BVN tasks. Capitalizing on this insight, we propose introducing the video generation model into this field for the first time. Yet, the prohibitive latency for generating videos spanning tens of seconds makes real-world deployment impractical. To bridge this gap, we propose SparseVideoNav, achieving sub-second trajectory inference guided by a generated sparse future spanning a 20-second horizon. This yields a remarkable 27x speed-up compared to the unoptimized counterpart. Extensive real-world zero-shot experiments demonstrate that SparseVideoNav achieves 2.5x the success rate of state-of-the-art LLM baselines on BVN tasks and marks the first realization of such capability in challenging night scenes.
PlannerRFT: Reinforcing Diffusion Planners through Closed-Loop and Sample-Efficient Fine-Tuning
Jan 19, 2026Diffusion-based planners have emerged as a promising approach for human-like trajectory generation in autonomous driving. Recent works incorporate reinforcement fine-tuning to enhance the robustness of diffusion planners through reward-oriented optimization in a generation-evaluation loop. However, they struggle to generate multi-modal, scenario-adaptive trajectories, hindering the exploitation efficiency of informative rewards during fine-tuning. To resolve this, we propose PlannerRFT, a sample-efficient reinforcement fine-tuning framework for diffusion-based planners. PlannerRFT adopts a dual-branch optimization that simultaneously refines the trajectory distribution and adaptively guides the denoising process toward more promising exploration, without altering the original inference pipeline. To support parallel learning at scale, we develop nuMax, an optimized simulator that achieves 10 times faster rollout compared to native nuPlan. Extensive experiments shows that PlannerRFT yields state-of-the-art performance with distinct behaviors emerging during the learning process.
LatentVLA: Efficient Vision-Language Models for Autonomous Driving via Latent Action Prediction
Jan 09, 2026End-to-end autonomous driving models trained on largescale datasets perform well in common scenarios but struggle with rare, long-tail situations due to limited scenario diversity. Recent Vision-Language-Action (VLA) models leverage broad knowledge from pre-trained visionlanguage models to address this limitation, yet face critical challenges: (1) numerical imprecision in trajectory prediction due to discrete tokenization, (2) heavy reliance on language annotations that introduce linguistic bias and annotation burden, and (3) computational inefficiency from multi-step chain-of-thought reasoning hinders real-time deployment. We propose LatentVLA, a novel framework that employs self-supervised latent action prediction to train VLA models without language annotations, eliminating linguistic bias while learning rich driving representations from unlabeled trajectory data. Through knowledge distillation, LatentVLA transfers the generalization capabilities of VLA models to efficient vision-based networks, achieving both robust performance and real-time efficiency. LatentVLA establishes a new state-of-the-art on the NAVSIM benchmark with a PDMS score of 92.4 and demonstrates strong zeroshot generalization on the nuScenes benchmark.
WholeBodyVLA: Towards Unified Latent VLA for Whole-Body Loco-Manipulation Control
Dec 15, 2025Humanoid robots require precise locomotion and dexterous manipulation to perform challenging loco-manipulation tasks. Yet existing approaches, modular or end-to-end, are deficient in manipulation-aware locomotion. This confines the robot to a limited workspace, preventing it from performing large-space loco-manipulation. We attribute this to: (1) the challenge of acquiring loco-manipulation knowledge due to the scarcity of humanoid teleoperation data, and (2) the difficulty of faithfully and reliably executing locomotion commands, stemming from the limited precision and stability of existing RL controllers. To acquire richer loco-manipulation knowledge, we propose a unified latent learning framework that enables Vision-Language-Action (VLA) system to learn from low-cost action-free egocentric videos. Moreover, an efficient human data collection pipeline is devised to augment the dataset and scale the benefits. To execute the desired locomotion commands more precisely, we present a loco-manipulation-oriented (LMO) RL policy specifically tailored for accurate and stable core loco-manipulation movements, such as advancing, turning, and squatting. Building on these components, we introduce WholeBodyVLA, a unified framework for humanoid loco-manipulation. To the best of our knowledge, WholeBodyVLA is one of its kind enabling large-space humanoid loco-manipulation. It is verified via comprehensive experiments on the AgiBot X2 humanoid, outperforming prior baseline by 21.3%. It also demonstrates strong generalization and high extensibility across a broad range of tasks.
Cross-modal Fundus Image Registration under Large FoV Disparity
Dec 14, 2025Previous work on cross-modal fundus image registration (CMFIR) assumes small cross-modal Field-of-View (FoV) disparity. By contrast, this paper is targeted at a more challenging scenario with large FoV disparity, to which directly applying current methods fails. We propose Crop and Alignment for cross-modal fundus image Registration(CARe), a very simple yet effective method. Specifically, given an OCTA with smaller FoV as a source image and a wide-field color fundus photograph (wfCFP) as a target image, our Crop operation exploits the physiological structure of the retina to crop from the target image a sub-image with its FoV roughly aligned with that of the source. This operation allows us to re-purpose the previous small-FoV-disparity oriented methods for subsequent image registration. Moreover, we improve spatial transformation by a double-fitting based Alignment module that utilizes the classical RANSAC algorithm and polynomial-based coordinate fitting in a sequential manner. Extensive experiments on a newly developed test set of 60 OCTA-wfCFP pairs verify the viability of CARe for CMFIR.
Optimization-Guided Diffusion for Interactive Scene Generation
Dec 11, 2025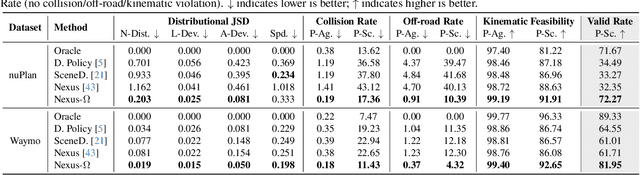
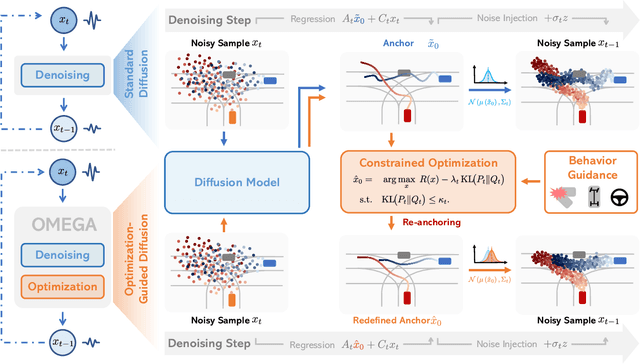
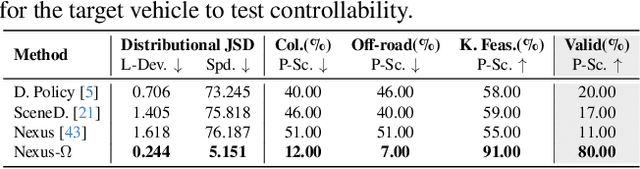
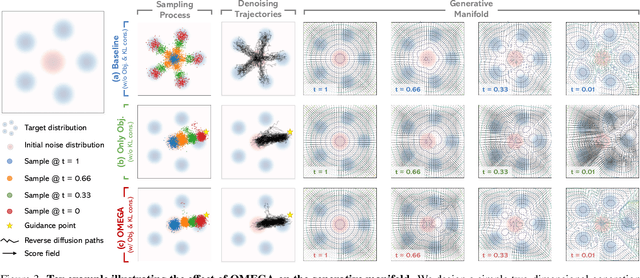
Realistic and diverse multi-agent driving scenes are crucial for evaluating autonomous vehicles, but safety-critical events which are essential for this task are rare and underrepresented in driving datasets. Data-driven scene generation offers a low-cost alternative by synthesizing complex traffic behaviors from existing driving logs. However, existing models often lack controllability or yield samples that violate physical or social constraints, limiting their usability. We present OMEGA, an optimization-guided, training-free framework that enforces structural consistency and interaction awareness during diffusion-based sampling from a scene generation model. OMEGA re-anchors each reverse diffusion step via constrained optimization, steering the generation towards physically plausible and behaviorally coherent trajectories. Building on this framework, we formulate ego-attacker interactions as a game-theoretic optimization in the distribution space, approximating Nash equilibria to generate realistic, safety-critical adversarial scenarios. Experiments on nuPlan and Waymo show that OMEGA improves generation realism, consistency, and controllability, increasing the ratio of physically and behaviorally valid scenes from 32.35% to 72.27% for free exploration capabilities, and from 11% to 80% for controllability-focused generation. Our approach can also generate $5\times$ more near-collision frames with a time-to-collision under three seconds while maintaining the overall scene realism.
SceneMaker: Open-set 3D Scene Generation with Decoupled De-occlusion and Pose Estimation Model
Dec 11, 2025We propose a decoupled 3D scene generation framework called SceneMaker in this work. Due to the lack of sufficient open-set de-occlusion and pose estimation priors, existing methods struggle to simultaneously produce high-quality geometry and accurate poses under severe occlusion and open-set settings. To address these issues, we first decouple the de-occlusion model from 3D object generation, and enhance it by leveraging image datasets and collected de-occlusion datasets for much more diverse open-set occlusion patterns. Then, we propose a unified pose estimation model that integrates global and local mechanisms for both self-attention and cross-attention to improve accuracy. Besides, we construct an open-set 3D scene dataset to further extend the generalization of the pose estimation model. Comprehensive experiments demonstrate the superiority of our decoupled framework on both indoor and open-set scenes. Our codes and datasets is released at https://idea-research.github.io/SceneMaker/.
SegDINO3D: 3D Instance Segmentation Empowered by Both Image-Level and Object-Level 2D Features
Sep 19, 2025In this paper, we present SegDINO3D, a novel Transformer encoder-decoder framework for 3D instance segmentation. As 3D training data is generally not as sufficient as 2D training images, SegDINO3D is designed to fully leverage 2D representation from a pre-trained 2D detection model, including both image-level and object-level features, for improving 3D representation. SegDINO3D takes both a point cloud and its associated 2D images as input. In the encoder stage, it first enriches each 3D point by retrieving 2D image features from its corresponding image views and then leverages a 3D encoder for 3D context fusion. In the decoder stage, it formulates 3D object queries as 3D anchor boxes and performs cross-attention from 3D queries to 2D object queries obtained from 2D images using the 2D detection model. These 2D object queries serve as a compact object-level representation of 2D images, effectively avoiding the challenge of keeping thousands of image feature maps in the memory while faithfully preserving the knowledge of the pre-trained 2D model. The introducing of 3D box queries also enables the model to modulate cross-attention using the predicted boxes for more precise querying. SegDINO3D achieves the state-of-the-art performance on the ScanNetV2 and ScanNet200 3D instance segmentation benchmarks. Notably, on the challenging ScanNet200 dataset, SegDINO3D significantly outperforms prior methods by +8.7 and +6.8 mAP on the validation and hidden test sets, respectively, demonstrating its superiority.
Is Diversity All You Need for Scalable Robotic Manipulation?
Jul 08, 2025Data scaling has driven remarkable success in foundation models for Natural Language Processing (NLP) and Computer Vision (CV), yet the principles of effective data scaling in robotic manipulation remain insufficiently understood. In this work, we investigate the nuanced role of data diversity in robot learning by examining three critical dimensions-task (what to do), embodiment (which robot to use), and expert (who demonstrates)-challenging the conventional intuition of "more diverse is better". Throughout extensive experiments on various robot platforms, we reveal that (1) task diversity proves more critical than per-task demonstration quantity, benefiting transfer from diverse pre-training tasks to novel downstream scenarios; (2) multi-embodiment pre-training data is optional for cross-embodiment transfer-models trained on high-quality single-embodiment data can efficiently transfer to different platforms, showing more desirable scaling property during fine-tuning than multi-embodiment pre-trained models; and (3) expert diversity, arising from individual operational preferences and stochastic variations in human demonstrations, can be confounding to policy learning, with velocity multimodality emerging as a key contributing factor. Based on this insight, we propose a distribution debiasing method to mitigate velocity ambiguity, the yielding GO-1-Pro achieves substantial performance gains of 15%, equivalent to using 2.5 times pre-training data. Collectively, these findings provide new perspectives and offer practical guidance on how to scale robotic manipulation datasets effectively.
ReSim: Reliable World Simulation for Autonomous Driving
Jun 11, 2025How can we reliably simulate future driving scenarios under a wide range of ego driving behaviors? Recent driving world models, developed exclusively on real-world driving data composed mainly of safe expert trajectories, struggle to follow hazardous or non-expert behaviors, which are rare in such data. This limitation restricts their applicability to tasks such as policy evaluation. In this work, we address this challenge by enriching real-world human demonstrations with diverse non-expert data collected from a driving simulator (e.g., CARLA), and building a controllable world model trained on this heterogeneous corpus. Starting with a video generator featuring a diffusion transformer architecture, we devise several strategies to effectively integrate conditioning signals and improve prediction controllability and fidelity. The resulting model, ReSim, enables Reliable Simulation of diverse open-world driving scenarios under various actions, including hazardous non-expert ones. To close the gap between high-fidelity simulation and applications that require reward signals to judge different actions, we introduce a Video2Reward module that estimates a reward from ReSim's simulated future. Our ReSim paradigm achieves up to 44% higher visual fidelity, improves controllability for both expert and non-expert actions by over 50%, and boosts planning and policy selection performance on NAVSIM by 2% and 25%, respectively.