 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTest-time Correction with Human Feedback: An Online 3D Detection System via Visual Prompting
Dec 10, 2024This paper introduces Test-time Correction (TTC) system, a novel online 3D detection system designated for online correction of test-time errors via human feedback, to guarantee the safety of deployed autonomous driving systems. Unlike well-studied offline 3D detectors frozen at inference, TTC explores the capability of instant online error rectification. By leveraging user feedback with interactive prompts at a frame, e.g., a simple click or draw of boxes, TTC could immediately update the corresponding detection results for future streaming inputs, even though the model is deployed with fixed parameters. This enables autonomous driving systems to adapt to new scenarios immediately and decrease deployment risks reliably without additional expensive training. To achieve such TTC system, we equip existing 3D detectors with Online Adapter (OA) module, a prompt-driven query generator for online correction. At the core of OA module are visual prompts, images of missed object-of-interest for guiding the corresponding detection and subsequent tracking. Those visual prompts, belonging to missed objects through online inference, are maintained by the visual prompt buffer for continuous error correction in subsequent frames. By doing so, TTC consistently detects online missed objects and immediately lowers driving risks. It achieves reliable, versatile, and adaptive driving autonomy. Extensive experiments demonstrate significant gain on instant error rectification over pre-trained 3D detectors, even in challenging scenarios with limited labels, zero-shot detection, and adverse conditions. We hope this work would inspire the community to investigate online rectification systems for autonomous driving post-deployment. Code would be publicly shared.
On the Integration of Optical Flow and Action Recognition
Dec 22, 2017
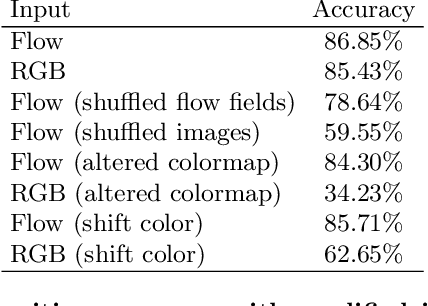

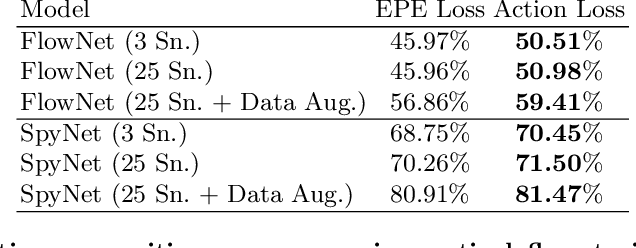
Most of the top performing action recognition methods use optical flow as a "black box" input. Here we take a deeper look at the combination of flow and action recognition, and investigate why optical flow is helpful, what makes a flow method good for action recognition, and how we can make it better. In particular, we investigate the impact of different flow algorithms and input transformations to better understand how these affect a state-of-the-art action recognition method. Furthermore, we fine tune two neural-network flow methods end-to-end on the most widely used action recognition dataset (UCF101). Based on these experiments, we make the following five observations: 1) optical flow is useful for action recognition because it is invariant to appearance, 2) optical flow methods are optimized to minimize end-point-error (EPE), but the EPE of current methods is not well correlated with action recognition performance, 3) for the flow methods tested, accuracy at boundaries and at small displacements is most correlated with action recognition performance, 4) training optical flow to minimize classification error instead of minimizing EPE improves recognition performance, and 5) optical flow learned for the task of action recognition differs from traditional optical flow especially inside the human body and at the boundary of the body. These observations may encourage optical flow researchers to look beyond EPE as a goal and guide action recognition researchers to seek better motion cues, leading to a tighter integration of the optical flow and action recognition communities.