 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAiEDA: An Open-Source AI-Aided Design Library for Design-to-Vector
Nov 08, 2025Recent research has demonstrated that artificial intelligence (AI) can assist electronic design automation (EDA) in improving both the quality and efficiency of chip design. But current AI for EDA (AI-EDA) infrastructures remain fragmented, lacking comprehensive solutions for the entire data pipeline from design execution to AI integration. Key challenges include fragmented flow engines that generate raw data, heterogeneous file formats for data exchange, non-standardized data extraction methods, and poorly organized data storage. This work introduces a unified open-source library for EDA (AiEDA) that addresses these issues. AiEDA integrates multiple design-to-vector data representation techniques that transform diverse chip design data into universal multi-level vector representations, establishing an AI-aided design (AAD) paradigm optimized for AI-EDA workflows. AiEDA provides complete physical design flows with programmatic data extraction and standardized Python interfaces bridging EDA datasets and AI frameworks. Leveraging the AiEDA library, we generate iDATA, a 600GB dataset of structured data derived from 50 real chip designs (28nm), and validate its effectiveness through seven representative AAD tasks spanning prediction, generation, optimization and analysis. The code is publicly available at https://github.com/OSCC-Project/AiEDA, while the full iDATA dataset is being prepared for public release, providing a foundation for future AI-EDA research.
MTGS: Multi-Traversal Gaussian Splatting
Mar 16, 2025

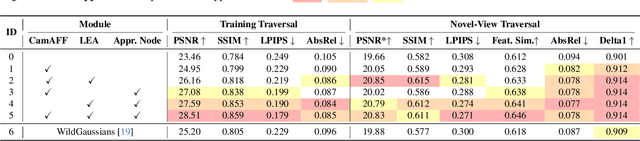

Multi-traversal data, commonly collected through daily commutes or by self-driving fleets, provides multiple viewpoints for scene reconstruction within a road block. This data offers significant potential for high-quality novel view synthesis, which is crucial for applications such as autonomous vehicle simulators. However, inherent challenges in multi-traversal data often result in suboptimal reconstruction quality, including variations in appearance and the presence of dynamic objects. To address these issues, we propose Multi-Traversal Gaussian Splatting (MTGS), a novel approach that reconstructs high-quality driving scenes from arbitrarily collected multi-traversal data by modeling a shared static geometry while separately handling dynamic elements and appearance variations. Our method employs a multi-traversal dynamic scene graph with a shared static node and traversal-specific dynamic nodes, complemented by color correction nodes with learnable spherical harmonics coefficient residuals. This approach enables high-fidelity novel view synthesis and provides flexibility to navigate any viewpoint. We conduct extensive experiments on a large-scale driving dataset, nuPlan, with multi-traversal data. Our results demonstrate that MTGS improves LPIPS by 23.5% and geometry accuracy by 46.3% compared to single-traversal baselines. The code and data would be available to the public.
Vista: A Generalizable Driving World Model with High Fidelity and Versatile Controllability
May 27, 2024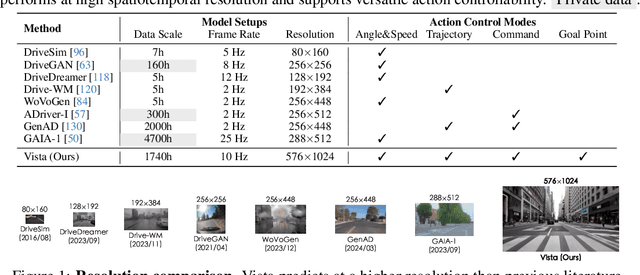


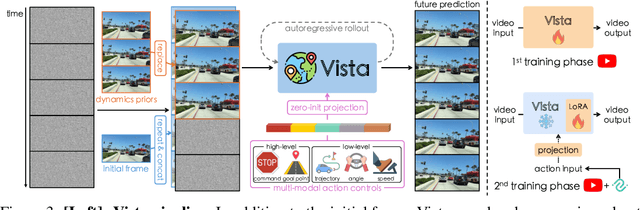
World models can foresee the outcomes of different actions, which is of paramount importance for autonomous driving. Nevertheless, existing driving world models still have limitations in generalization to unseen environments, prediction fidelity of critical details, and action controllability for flexible application. In this paper, we present Vista, a generalizable driving world model with high fidelity and versatile controllability. Based on a systematic diagnosis of existing methods, we introduce several key ingredients to address these limitations. To accurately predict real-world dynamics at high resolution, we propose two novel losses to promote the learning of moving instances and structural information. We also devise an effective latent replacement approach to inject historical frames as priors for coherent long-horizon rollouts. For action controllability, we incorporate a versatile set of controls from high-level intentions (command, goal point) to low-level maneuvers (trajectory, angle, and speed) through an efficient learning strategy. After large-scale training, the capabilities of Vista can seamlessly generalize to different scenarios. Extensive experiments on multiple datasets show that Vista outperforms the most advanced general-purpose video generator in over 70% of comparisons and surpasses the best-performing driving world model by 55% in FID and 27% in FVD. Moreover, for the first time, we utilize the capacity of Vista itself to establish a generalizable reward for real-world action evaluation without accessing the ground truth actions.
Generalized Predictive Model for Autonomous Driving
Mar 14, 2024

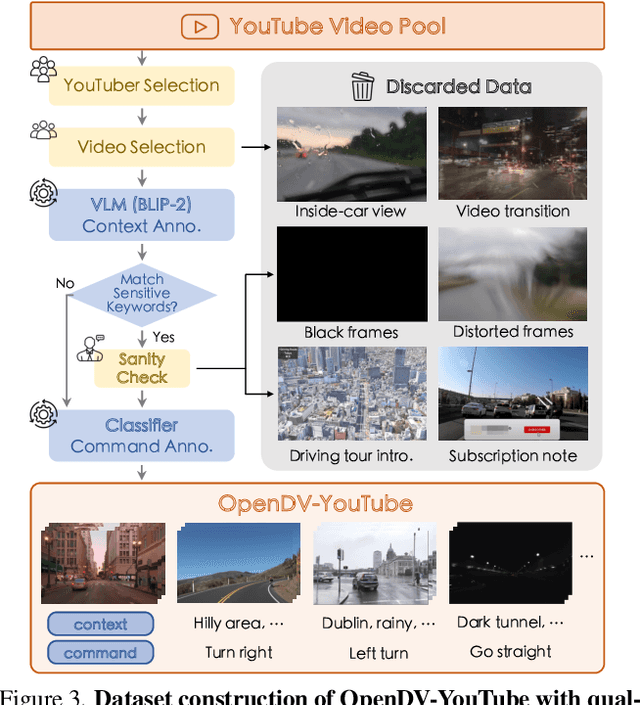

In this paper, we introduce the first large-scale video prediction model in the autonomous driving discipline. To eliminate the restriction of high-cost data collection and empower the generalization ability of our model, we acquire massive data from the web and pair it with diverse and high-quality text descriptions. The resultant dataset accumulates over 2000 hours of driving videos, spanning areas all over the world with diverse weather conditions and traffic scenarios. Inheriting the merits from recent latent diffusion models, our model, dubbed GenAD, handles the challenging dynamics in driving scenes with novel temporal reasoning blocks. We showcase that it can generalize to various unseen driving datasets in a zero-shot manner, surpassing general or driving-specific video prediction counterparts. Furthermore, GenAD can be adapted into an action-conditioned prediction model or a motion planner, holding great potential for real-world driving applications.