 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperparameter Optimization of Constraint Programming Solvers
Jan 16, 2026The performance of constraint programming solvers is highly sensitive to the choice of their hyperparameters. Manually finding the best solver configuration is a difficult, time-consuming task that typically requires expert knowledge. In this paper, we introduce probe and solve algorithm, a novel two-phase framework for automated hyperparameter optimization integrated into the CPMpy library. This approach partitions the available time budget into two phases: a probing phase that explores different sets of hyperparameters using configurable hyperparameter optimization methods, followed by a solving phase where the best configuration found is used to tackle the problem within the remaining time. We implement and compare two hyperparameter optimization methods within the probe and solve algorithm: Bayesian optimization and Hamming distance search. We evaluate the algorithm on two different constraint programming solvers, ACE and Choco, across 114 combinatorial problem instances, comparing their performance against the solver's default configurations. Results show that using Bayesian optimization, the algorithm outperforms the solver's default configurations, improving solution quality for ACE in 25.4% of instances and matching the default performance in 57.9%, and for Choco, achieving superior results in 38.6% of instances. It also consistently surpasses Hamming distance search within the same framework, confirming the advantage of model-based exploration over simple local search. Overall, the probe and solve algorithm offers a practical, resource-aware approach for tuning constraint solvers that yields robust improvements across diverse problem types.
Lightweight Trustworthy Distributed Clustering
Apr 14, 2025Ensuring data trustworthiness within individual edge nodes while facilitating collaborative data processing poses a critical challenge in edge computing systems (ECS), particularly in resource-constrained scenarios such as autonomous systems sensor networks, industrial IoT, and smart cities. This paper presents a lightweight, fully distributed k-means clustering algorithm specifically adapted for edge environments, leveraging a distributed averaging approach with additive secret sharing, a secure multiparty computation technique, during the cluster center update phase to ensure the accuracy and trustworthiness of data across nodes.
Multi-objective methods in Federated Learning: A survey and taxonomy
Feb 05, 2025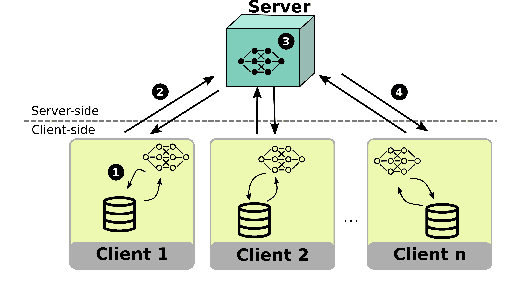

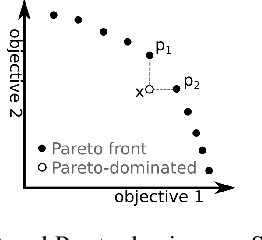

The Federated Learning paradigm facilitates effective distributed machine learning in settings where training data is decentralized across multiple clients. As the popularity of the strategy grows, increasingly complex real-world problems emerge, many of which require balancing conflicting demands such as fairness, utility, and resource consumption. Recent works have begun to recognise the use of a multi-objective perspective in answer to this challenge. However, this novel approach of combining federated methods with multi-objective optimisation has never been discussed in the broader context of both fields. In this work, we offer a first clear and systematic overview of the different ways the two fields can be integrated. We propose a first taxonomy on the use of multi-objective methods in connection with Federated Learning, providing a targeted survey of the state-of-the-art and proposing unambiguous labels to categorise contributions. Given the developing nature of this field, our taxonomy is designed to provide a solid basis for further research, capturing existing works while anticipating future additions. Finally, we outline open challenges and possible directions for further research.
FedPref: Federated Learning Across Heterogeneous Multi-objective Preferences
Jan 23, 2025



Federated Learning (FL) is a distributed machine learning strategy, developed for settings where training data is owned by distributed devices and cannot be shared. FL circumvents this constraint by carrying out model training in distribution. The parameters of these local models are shared intermittently among participants and aggregated to enhance model accuracy. This strategy has been rapidly adopted by the industry in efforts to overcome privacy and resource constraints in model training. However, the application of FL to real-world settings brings additional challenges associated with heterogeneity between participants. Research into mitigating these difficulties in FL has largely focused on only two types of heterogeneity: the unbalanced distribution of training data, and differences in client resources. Yet more types of heterogeneity are becoming relevant as the capability of FL expands to cover more complex problems, from the tuning of LLMs to enabling machine learning on edge devices. In this work, we discuss a novel type of heterogeneity that is likely to become increasingly relevant in future applications: this is preference heterogeneity, emerging when clients learn under multiple objectives, with different importance assigned to each objective on different clients. In this work, we discuss the implications of this type of heterogeneity and propose FedPref, a first algorithm designed to facilitate personalised FL in this setting. We demonstrate the effectiveness of the algorithm across different problems, preference distributions and model architectures. In addition, we introduce a new analytical point of view, based on multi-objective metrics, for evaluating the performance of FL algorithms in this setting beyond the traditional client-focused metrics. We perform a second experimental analysis based in this view, and show that FedPref outperforms compared algorithms.
A Unified Hyperparameter Optimization Pipeline for Transformer-Based Time Series Forecasting Models
Jan 02, 2025



Transformer-based models for time series forecasting (TSF) have attracted significant attention in recent years due to their effectiveness and versatility. However, these models often require extensive hyperparameter optimization (HPO) to achieve the best possible performance, and a unified pipeline for HPO in transformer-based TSF remains lacking. In this paper, we present one such pipeline and conduct extensive experiments on several state-of-the-art (SOTA) transformer-based TSF models. These experiments are conducted on standard benchmark datasets to evaluate and compare the performance of different models, generating practical insights and examples. Our pipeline is generalizable beyond transformer-based architectures and can be applied to other SOTA models, such as Mamba and TimeMixer, as demonstrated in our experiments. The goal of this work is to provide valuable guidance to both industry practitioners and academic researchers in efficiently identifying optimal hyperparameters suited to their specific domain applications. The code and complete experimental results are available on GitHub.
Trustworthiness of Stochastic Gradient Descent in Distributed Learning
Oct 28, 2024
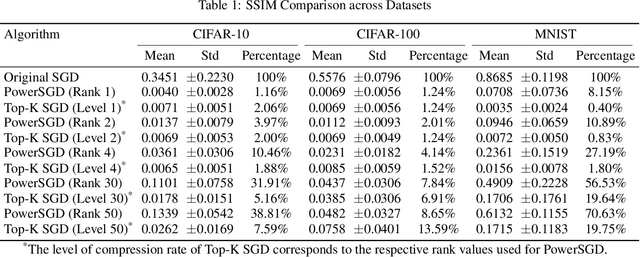
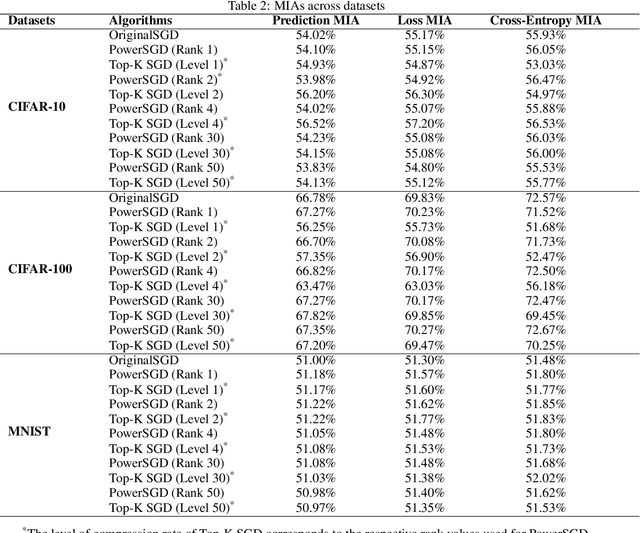
Distributed learning (DL) leverages multiple nodes to accelerate training, enabling the efficient optimization of large-scale models. Stochastic Gradient Descent (SGD), a key optimization algorithm, plays a central role in this process. However, communication bottlenecks often limit scalability and efficiency, leading to the increasing adoption of compressed SGD techniques to alleviate these challenges. Despite addressing communication overheads, compressed SGD introduces trustworthiness concerns, as gradient exchanges among nodes are vulnerable to attacks like gradient inversion (GradInv) and membership inference attacks (MIA). The trustworthiness of compressed SGD remains underexplored, leaving important questions about its reliability unanswered. In this paper, we provide a trustworthiness evaluation of compressed versus uncompressed SGD. Specifically, we conduct empirical studies using GradInv attacks, revealing that compressed SGD demonstrates significantly higher resistance to privacy leakage compared to uncompressed SGD. Moreover, our findings suggest that MIA may not be a reliable metric for assessing privacy risks in machine learning.
Dataset | Mindset = Explainable AI | Interpretable AI
Aug 22, 2024We often use "explainable" Artificial Intelligence (XAI)" and "interpretable AI (IAI)" interchangeably when we apply various XAI tools for a given dataset to explain the reasons that underpin machine learning (ML) outputs. However, these notions can sometimes be confusing because interpretation often has a subjective connotation, while explanations lean towards objective facts. We argue that XAI is a subset of IAI. The concept of IAI is beyond the sphere of a dataset. It includes the domain of a mindset. At the core of this ambiguity is the duality of reasons, in which we can reason either outwards or inwards. When directed outwards, we want the reasons to make sense through the laws of nature. When turned inwards, we want the reasons to be happy, guided by the laws of the heart. While XAI and IAI share reason as the common notion for the goal of transparency, clarity, fairness, reliability, and accountability in the context of ethical AI and trustworthy AI (TAI), their differences lie in that XAI emphasizes the post-hoc analysis of a dataset, and IAI requires a priori mindset of abstraction. This hypothesis can be proved by empirical experiments based on an open dataset and harnessed by High-Performance Computing (HPC). The demarcation of XAI and IAI is indispensable because it would be impossible to determine regulatory policies for many AI applications, especially in healthcare, human resources, banking, and finance. We aim to clarify these notions and lay the foundation of XAI, IAI, EAI, and TAI for many practitioners and policymakers in future AI applications and research.
Heterogeneity: An Open Challenge for Federated On-board Machine Learning
Aug 13, 2024
The design of satellite missions is currently undergoing a paradigm shift from the historical approach of individualised monolithic satellites towards distributed mission configurations, consisting of multiple small satellites. With a rapidly growing number of such satellites now deployed in orbit, each collecting large amounts of data, interest in on-board orbital edge computing is rising. Federated Learning is a promising distributed computing approach in this context, allowing multiple satellites to collaborate efficiently in training on-board machine learning models. Though recent works on the use of Federated Learning in orbital edge computing have focused largely on homogeneous satellite constellations, Federated Learning could also be employed to allow heterogeneous satellites to form ad-hoc collaborations, e.g. in the case of communications satellites operated by different providers. Such an application presents additional challenges to the Federated Learning paradigm, arising largely from the heterogeneity of such a system. In this position paper, we offer a systematic review of these challenges in the context of the cross-provider use case, giving a brief overview of the state-of-the-art for each, and providing an entry point for deeper exploration of each issue.
Survey and Taxonomy: The Role of Data-Centric AI in Transformer-Based Time Series Forecasting
Jul 29, 2024Alongside the continuous process of improving AI performance through the development of more sophisticated models, researchers have also focused their attention to the emerging concept of data-centric AI, which emphasizes the important role of data in a systematic machine learning training process. Nonetheless, the development of models has also continued apace. One result of this progress is the development of the Transformer Architecture, which possesses a high level of capability in multiple domains such as Natural Language Processing (NLP), Computer Vision (CV) and Time Series Forecasting (TSF). Its performance is, however, heavily dependent on input data preprocessing and output data evaluation, justifying a data-centric approach to future research. We argue that data-centric AI is essential for training AI models, particularly for transformer-based TSF models efficiently. However, there is a gap regarding the integration of transformer-based TSF and data-centric AI. This survey aims to pin down this gap via the extensive literature review based on the proposed taxonomy. We review the previous research works from a data-centric AI perspective and we intend to lay the foundation work for the future development of transformer-based architecture and data-centric AI.
Training Green AI Models Using Elite Samples
Feb 19, 2024



The substantial increase in AI model training has considerable environmental implications, mandating more energy-efficient and sustainable AI practices. On the one hand, data-centric approaches show great potential towards training energy-efficient AI models. On the other hand, instance selection methods demonstrate the capability of training AI models with minimised training sets and negligible performance degradation. Despite the growing interest in both topics, the impact of data-centric training set selection on energy efficiency remains to date unexplored. This paper presents an evolutionary-based sampling framework aimed at (i) identifying elite training samples tailored for datasets and model pairs, (ii) comparing model performance and energy efficiency gains against typical model training practice, and (iii) investigating the feasibility of this framework for fostering sustainable model training practices. To evaluate the proposed framework, we conducted an empirical experiment including 8 commonly used AI classification models and 25 publicly available datasets. The results showcase that by considering 10% elite training samples, the models' performance can show a 50% improvement and remarkable energy savings of 98% compared to the common training practice.