 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-objective methods in Federated Learning: A survey and taxonomy
Feb 05, 2025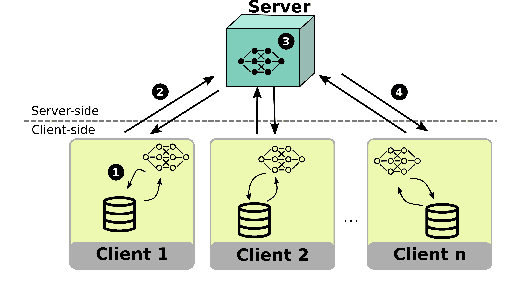


The Federated Learning paradigm facilitates effective distributed machine learning in settings where training data is decentralized across multiple clients. As the popularity of the strategy grows, increasingly complex real-world problems emerge, many of which require balancing conflicting demands such as fairness, utility, and resource consumption. Recent works have begun to recognise the use of a multi-objective perspective in answer to this challenge. However, this novel approach of combining federated methods with multi-objective optimisation has never been discussed in the broader context of both fields. In this work, we offer a first clear and systematic overview of the different ways the two fields can be integrated. We propose a first taxonomy on the use of multi-objective methods in connection with Federated Learning, providing a targeted survey of the state-of-the-art and proposing unambiguous labels to categorise contributions. Given the developing nature of this field, our taxonomy is designed to provide a solid basis for further research, capturing existing works while anticipating future additions. Finally, we outline open challenges and possible directions for further research.
FedPref: Federated Learning Across Heterogeneous Multi-objective Preferences
Jan 23, 2025



Federated Learning (FL) is a distributed machine learning strategy, developed for settings where training data is owned by distributed devices and cannot be shared. FL circumvents this constraint by carrying out model training in distribution. The parameters of these local models are shared intermittently among participants and aggregated to enhance model accuracy. This strategy has been rapidly adopted by the industry in efforts to overcome privacy and resource constraints in model training. However, the application of FL to real-world settings brings additional challenges associated with heterogeneity between participants. Research into mitigating these difficulties in FL has largely focused on only two types of heterogeneity: the unbalanced distribution of training data, and differences in client resources. Yet more types of heterogeneity are becoming relevant as the capability of FL expands to cover more complex problems, from the tuning of LLMs to enabling machine learning on edge devices. In this work, we discuss a novel type of heterogeneity that is likely to become increasingly relevant in future applications: this is preference heterogeneity, emerging when clients learn under multiple objectives, with different importance assigned to each objective on different clients. In this work, we discuss the implications of this type of heterogeneity and propose FedPref, a first algorithm designed to facilitate personalised FL in this setting. We demonstrate the effectiveness of the algorithm across different problems, preference distributions and model architectures. In addition, we introduce a new analytical point of view, based on multi-objective metrics, for evaluating the performance of FL algorithms in this setting beyond the traditional client-focused metrics. We perform a second experimental analysis based in this view, and show that FedPref outperforms compared algorithms.
A Unified Hyperparameter Optimization Pipeline for Transformer-Based Time Series Forecasting Models
Jan 02, 2025



Transformer-based models for time series forecasting (TSF) have attracted significant attention in recent years due to their effectiveness and versatility. However, these models often require extensive hyperparameter optimization (HPO) to achieve the best possible performance, and a unified pipeline for HPO in transformer-based TSF remains lacking. In this paper, we present one such pipeline and conduct extensive experiments on several state-of-the-art (SOTA) transformer-based TSF models. These experiments are conducted on standard benchmark datasets to evaluate and compare the performance of different models, generating practical insights and examples. Our pipeline is generalizable beyond transformer-based architectures and can be applied to other SOTA models, such as Mamba and TimeMixer, as demonstrated in our experiments. The goal of this work is to provide valuable guidance to both industry practitioners and academic researchers in efficiently identifying optimal hyperparameters suited to their specific domain applications. The code and complete experimental results are available on GitHub.
Search Strategy Generation for Branch and Bound Using Genetic Programming
Dec 12, 2024



Branch-and-Bound (B\&B) is an exact method in integer programming that recursively divides the search space into a tree. During the resolution process, determining the next subproblem to explore within the tree-known as the search strategy-is crucial. Hand-crafted heuristics are commonly used, but none are effective over all problem classes. Recent approaches utilizing neural networks claim to make more intelligent decisions but are computationally expensive. In this paper, we introduce GP2S (Genetic Programming for Search Strategy), a novel machine learning approach that automatically generates a B\&B search strategy heuristic, aiming to make intelligent decisions while being computationally lightweight. We define a policy as a function that evaluates the quality of a B\&B node by combining features from the node and the problem; the search strategy policy is then defined by a best-first search based on this node ranking. The policy space is explored using a genetic programming algorithm, and the policy that achieves the best performance on a training set is selected. We compare our approach with the standard method of the SCIP solver, a recent graph neural network-based method, and handcrafted heuristics. Our first evaluation includes three types of primal hard problems, tested on instances similar to the training set and on larger instances. Our method is at most 2\% slower than the best baseline and consistently outperforms SCIP, achieving an average speedup of 11.3\%. Additionally, GP2S is tested on the MIPLIB 2017 dataset, generating multiple heuristics from different subsets of instances. It exceeds SCIP's average performance in 7 out of 10 cases across 15 times more instances and under a time limit 15 times longer, with some GP2S methods leading on most experiments in terms of the number of feasible solutions or optimality gap.
Heterogeneity: An Open Challenge for Federated On-board Machine Learning
Aug 13, 2024
The design of satellite missions is currently undergoing a paradigm shift from the historical approach of individualised monolithic satellites towards distributed mission configurations, consisting of multiple small satellites. With a rapidly growing number of such satellites now deployed in orbit, each collecting large amounts of data, interest in on-board orbital edge computing is rising. Federated Learning is a promising distributed computing approach in this context, allowing multiple satellites to collaborate efficiently in training on-board machine learning models. Though recent works on the use of Federated Learning in orbital edge computing have focused largely on homogeneous satellite constellations, Federated Learning could also be employed to allow heterogeneous satellites to form ad-hoc collaborations, e.g. in the case of communications satellites operated by different providers. Such an application presents additional challenges to the Federated Learning paradigm, arising largely from the heterogeneity of such a system. In this position paper, we offer a systematic review of these challenges in the context of the cross-provider use case, giving a brief overview of the state-of-the-art for each, and providing an entry point for deeper exploration of each issue.
MOMAland: A Set of Benchmarks for Multi-Objective Multi-Agent Reinforcement Learning
Jul 23, 2024



Many challenging tasks such as managing traffic systems, electricity grids, or supply chains involve complex decision-making processes that must balance multiple conflicting objectives and coordinate the actions of various independent decision-makers (DMs). One perspective for formalising and addressing such tasks is multi-objective multi-agent reinforcement learning (MOMARL). MOMARL broadens reinforcement learning (RL) to problems with multiple agents each needing to consider multiple objectives in their learning process. In reinforcement learning research, benchmarks are crucial in facilitating progress, evaluation, and reproducibility. The significance of benchmarks is underscored by the existence of numerous benchmark frameworks developed for various RL paradigms, including single-agent RL (e.g., Gymnasium), multi-agent RL (e.g., PettingZoo), and single-agent multi-objective RL (e.g., MO-Gymnasium). To support the advancement of the MOMARL field, we introduce MOMAland, the first collection of standardised environments for multi-objective multi-agent reinforcement learning. MOMAland addresses the need for comprehensive benchmarking in this emerging field, offering over 10 diverse environments that vary in the number of agents, state representations, reward structures, and utility considerations. To provide strong baselines for future research, MOMAland also includes algorithms capable of learning policies in such settings.
Training Green AI Models Using Elite Samples
Feb 19, 2024



The substantial increase in AI model training has considerable environmental implications, mandating more energy-efficient and sustainable AI practices. On the one hand, data-centric approaches show great potential towards training energy-efficient AI models. On the other hand, instance selection methods demonstrate the capability of training AI models with minimised training sets and negligible performance degradation. Despite the growing interest in both topics, the impact of data-centric training set selection on energy efficiency remains to date unexplored. This paper presents an evolutionary-based sampling framework aimed at (i) identifying elite training samples tailored for datasets and model pairs, (ii) comparing model performance and energy efficiency gains against typical model training practice, and (iii) investigating the feasibility of this framework for fostering sustainable model training practices. To evaluate the proposed framework, we conducted an empirical experiment including 8 commonly used AI classification models and 25 publicly available datasets. The results showcase that by considering 10% elite training samples, the models' performance can show a 50% improvement and remarkable energy savings of 98% compared to the common training practice.
An ARGoS plug-in for the Crazyflie drone
Jan 30, 2024We present a new plug-in for the ARGoS swarm robotic simulator to implement the Crazyflie drone, including its controllers, sensors, and some expansion decks. We have based our development on the former Spiri drone, upgrading the position controller, adding a new speed controller, LED ring, onboard camera, and battery discharge model. We have compared this new plug-in in terms of accuracy and efficiency with data obtained from real Crazyflie drones. All our experiments showed that the proposed plug-in worked well, presenting high levels of accuracy. We believe that this is an important contribution to robot simulations which will extend ARGoS capabilities through the use of our proposed, open-source plug-in.
Constraint Model for the Satellite Image Mosaic Selection Problem
Dec 07, 2023



Satellite imagery solutions are widely used to study and monitor different regions of the Earth. However, a single satellite image can cover only a limited area. In cases where a larger area of interest is studied, several images must be stitched together to create a single larger image, called a mosaic, that can cover the area. Today, with the increasing number of satellite images available for commercial use, selecting the images to build the mosaic is challenging, especially when the user wants to optimize one or more parameters, such as the total cost and the cloud coverage percentage in the mosaic. More precisely, for this problem the input is an area of interest, several satellite images intersecting the area, a list of requirements relative to the image and the mosaic, such as cloud coverage percentage, image resolution, and a list of objectives to optimize. We contribute to the constraint and mixed integer lineal programming formulation of this new problem, which we call the \textit{satellite image mosaic selection problem}, which is a multi-objective extension of the polygon cover problem. We propose a dataset of realistic and challenging instances, where the images were captured by the satellite constellations SPOT, Pl\'eiades and Pl\'eiades Neo. We evaluate and compare the two proposed models and show their efficiency for large instances, up to 200 images.
* This paper contains minor corrections from the original document presented at the 29th International Conference on Principles and Practice of Constraint Programming (CP 2023). Minor corrections in Figures 5a and 5b that do not affect the analysis result. Minor typo corrections in Appendix A
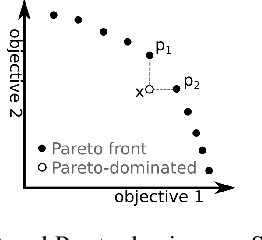
Multi-Objective Reinforcement Learning based on Decomposition: A taxonomy and framework
Nov 21, 2023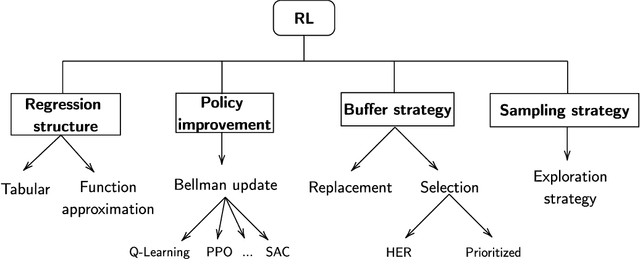

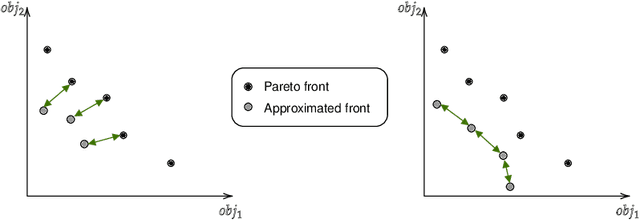

Multi-objective reinforcement learning (MORL) extends traditional RL by seeking policies making different compromises among conflicting objectives. The recent surge of interest in MORL has led to diverse studies and solving methods, often drawing from existing knowledge in multi-objective optimization based on decomposition (MOO/D). Yet, a clear categorization based on both RL and MOO/D is lacking in the existing literature. Consequently, MORL researchers face difficulties when trying to classify contributions within a broader context due to the absence of a standardized taxonomy. To tackle such an issue, this paper introduces Multi-Objective Reinforcement Learning based on Decomposition (MORL/D), a novel methodology bridging RL and MOO literature. A comprehensive taxonomy for MORL/D is presented, providing a structured foundation for categorizing existing and potential MORL works. The introduced taxonomy is then used to scrutinize MORL research, enhancing clarity and conciseness through well-defined categorization. Moreover, a flexible framework derived from the taxonomy is introduced. This framework accommodates diverse instantiations using tools from both RL and MOO/D. Implementation across various configurations demonstrates its versatility, assessed against benchmark problems. Results indicate MORL/D instantiations achieve comparable performance with significantly greater versatility than current state-of-the-art approaches. By presenting the taxonomy and framework, this paper offers a comprehensive perspective and a unified vocabulary for MORL. This not only facilitates the identification of algorithmic contributions but also lays the groundwork for novel research avenues in MORL, contributing to the continued advancement of this field.