 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLightweight Trustworthy Distributed Clustering
Apr 14, 2025Ensuring data trustworthiness within individual edge nodes while facilitating collaborative data processing poses a critical challenge in edge computing systems (ECS), particularly in resource-constrained scenarios such as autonomous systems sensor networks, industrial IoT, and smart cities. This paper presents a lightweight, fully distributed k-means clustering algorithm specifically adapted for edge environments, leveraging a distributed averaging approach with additive secret sharing, a secure multiparty computation technique, during the cluster center update phase to ensure the accuracy and trustworthiness of data across nodes.
A Unified Hyperparameter Optimization Pipeline for Transformer-Based Time Series Forecasting Models
Jan 02, 2025



Transformer-based models for time series forecasting (TSF) have attracted significant attention in recent years due to their effectiveness and versatility. However, these models often require extensive hyperparameter optimization (HPO) to achieve the best possible performance, and a unified pipeline for HPO in transformer-based TSF remains lacking. In this paper, we present one such pipeline and conduct extensive experiments on several state-of-the-art (SOTA) transformer-based TSF models. These experiments are conducted on standard benchmark datasets to evaluate and compare the performance of different models, generating practical insights and examples. Our pipeline is generalizable beyond transformer-based architectures and can be applied to other SOTA models, such as Mamba and TimeMixer, as demonstrated in our experiments. The goal of this work is to provide valuable guidance to both industry practitioners and academic researchers in efficiently identifying optimal hyperparameters suited to their specific domain applications. The code and complete experimental results are available on GitHub.
Trustworthiness of Stochastic Gradient Descent in Distributed Learning
Oct 28, 2024
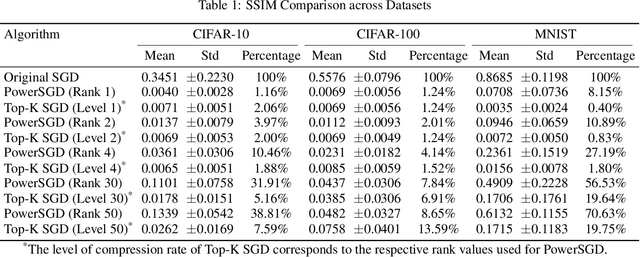
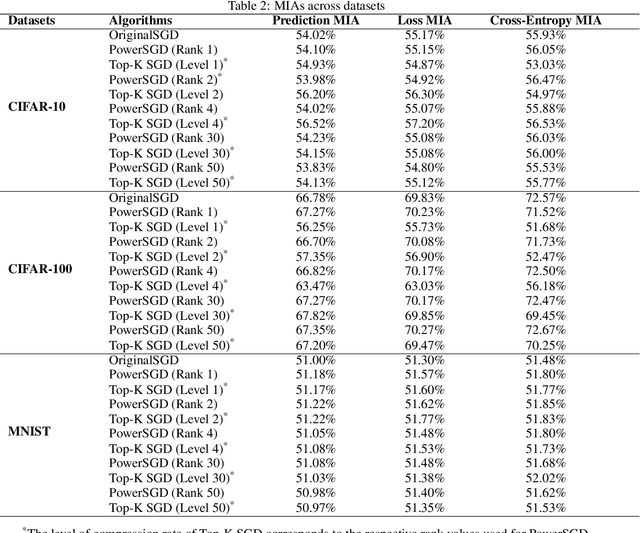
Distributed learning (DL) leverages multiple nodes to accelerate training, enabling the efficient optimization of large-scale models. Stochastic Gradient Descent (SGD), a key optimization algorithm, plays a central role in this process. However, communication bottlenecks often limit scalability and efficiency, leading to the increasing adoption of compressed SGD techniques to alleviate these challenges. Despite addressing communication overheads, compressed SGD introduces trustworthiness concerns, as gradient exchanges among nodes are vulnerable to attacks like gradient inversion (GradInv) and membership inference attacks (MIA). The trustworthiness of compressed SGD remains underexplored, leaving important questions about its reliability unanswered. In this paper, we provide a trustworthiness evaluation of compressed versus uncompressed SGD. Specifically, we conduct empirical studies using GradInv attacks, revealing that compressed SGD demonstrates significantly higher resistance to privacy leakage compared to uncompressed SGD. Moreover, our findings suggest that MIA may not be a reliable metric for assessing privacy risks in machine learning.
Dataset | Mindset = Explainable AI | Interpretable AI
Aug 22, 2024We often use "explainable" Artificial Intelligence (XAI)" and "interpretable AI (IAI)" interchangeably when we apply various XAI tools for a given dataset to explain the reasons that underpin machine learning (ML) outputs. However, these notions can sometimes be confusing because interpretation often has a subjective connotation, while explanations lean towards objective facts. We argue that XAI is a subset of IAI. The concept of IAI is beyond the sphere of a dataset. It includes the domain of a mindset. At the core of this ambiguity is the duality of reasons, in which we can reason either outwards or inwards. When directed outwards, we want the reasons to make sense through the laws of nature. When turned inwards, we want the reasons to be happy, guided by the laws of the heart. While XAI and IAI share reason as the common notion for the goal of transparency, clarity, fairness, reliability, and accountability in the context of ethical AI and trustworthy AI (TAI), their differences lie in that XAI emphasizes the post-hoc analysis of a dataset, and IAI requires a priori mindset of abstraction. This hypothesis can be proved by empirical experiments based on an open dataset and harnessed by High-Performance Computing (HPC). The demarcation of XAI and IAI is indispensable because it would be impossible to determine regulatory policies for many AI applications, especially in healthcare, human resources, banking, and finance. We aim to clarify these notions and lay the foundation of XAI, IAI, EAI, and TAI for many practitioners and policymakers in future AI applications and research.
Survey and Taxonomy: The Role of Data-Centric AI in Transformer-Based Time Series Forecasting
Jul 29, 2024Alongside the continuous process of improving AI performance through the development of more sophisticated models, researchers have also focused their attention to the emerging concept of data-centric AI, which emphasizes the important role of data in a systematic machine learning training process. Nonetheless, the development of models has also continued apace. One result of this progress is the development of the Transformer Architecture, which possesses a high level of capability in multiple domains such as Natural Language Processing (NLP), Computer Vision (CV) and Time Series Forecasting (TSF). Its performance is, however, heavily dependent on input data preprocessing and output data evaluation, justifying a data-centric approach to future research. We argue that data-centric AI is essential for training AI models, particularly for transformer-based TSF models efficiently. However, there is a gap regarding the integration of transformer-based TSF and data-centric AI. This survey aims to pin down this gap via the extensive literature review based on the proposed taxonomy. We review the previous research works from a data-centric AI perspective and we intend to lay the foundation work for the future development of transformer-based architecture and data-centric AI.
Transformer Multivariate Forecasting: Less is More?
Dec 30, 2023In the domain of multivariate forecasting, transformer models stand out as powerful apparatus, displaying exceptional capabilities in handling messy datasets from real-world contexts. However, the inherent complexity of these datasets, characterized by numerous variables and lengthy temporal sequences, poses challenges, including increased noise and extended model runtime. This paper focuses on reducing redundant information to elevate forecasting accuracy while optimizing runtime efficiency. We propose a novel transformer forecasting framework enhanced by Principal Component Analysis (PCA) to tackle this challenge. The framework is evaluated by five state-of-the-art (SOTA) models and four diverse real-world datasets. Our experimental results demonstrate the framework's ability to minimize prediction errors across all models and datasets while significantly reducing runtime. From the model perspective, one of the PCA-enhanced models: PCA+Crossformer, reduces mean square errors (MSE) by 33.3% and decreases runtime by 49.2% on average. From the dataset perspective, the framework delivers 14.3% MSE and 76.6% runtime reduction on Electricity datasets, as well as 4.8% MSE and 86.9% runtime reduction on Traffic datasets. This study aims to advance various SOTA models and enhance transformer-based time series forecasting for intricate data.
Trustworthy AI: Deciding What to Decide
Nov 21, 2023When engaging in strategic decision-making, we are frequently confronted with overwhelming information and data. The situation can be further complicated when certain pieces of evidence contradict each other or become paradoxical. The primary challenge is how to determine which information can be trusted when we adopt Artificial Intelligence (AI) systems for decision-making. This issue is known as deciding what to decide or Trustworthy AI. However, the AI system itself is often considered an opaque black box. We propose a new approach to address this issue by introducing a novel framework of Trustworthy AI (TAI) encompassing three crucial components of AI: representation space, loss function, and optimizer. Each component is loosely coupled with four TAI properties. Altogether, the framework consists of twelve TAI properties. We aim to use this framework to conduct the TAI experiments by quantitive and qualitative research methods to satisfy TAI properties for the decision-making context. The framework allows us to formulate an optimal prediction model trained by the given dataset for applying the strategic investment decision of credit default swaps (CDS) in the technology sector. Finally, we provide our view of the future direction of TAI research
Survey of Trustworthy AI: A Meta Decision of AI
Jun 12, 2023When making strategic decisions, we are often confronted with overwhelming information to process. The situation can be further complicated when some pieces of evidence are contradicted each other or paradoxical. The challenge then becomes how to determine which information is useful and which ones should be eliminated. This process is known as meta-decision. Likewise, when it comes to using Artificial Intelligence (AI) systems for strategic decision-making, placing trust in the AI itself becomes a meta-decision, given that many AI systems are viewed as opaque "black boxes" that process large amounts of data. Trusting an opaque system involves deciding on the level of Trustworthy AI (TAI). We propose a new approach to address this issue by introducing a novel taxonomy or framework of TAI, which encompasses three crucial domains: articulate, authentic, and basic for different levels of trust. To underpin these domains, we create ten dimensions to measure trust: explainability/transparency, fairness/diversity, generalizability, privacy, data governance, safety/robustness, accountability, reproducibility, reliability, and sustainability. We aim to use this taxonomy to conduct a comprehensive survey and explore different TAI approaches from a strategic decision-making perspective.
The Emerging Artificial Intelligence Protocol for Hierarchical Information Network
Feb 22, 2023



The recent development of artificial intelligence enables a machine to achieve a human level of intelligence. Problem-solving and decision-making are two mental abilities to measure human intelligence. Many scholars have proposed different models. However, there is a gap in establishing an AI-oriented hierarchical model with a multilevel abstraction. This study proposes a novel model known as the emerged AI protocol that consists of seven distinct layers capable of providing an optimal and explainable solution for a given problem.
* 6 pages, 4 figures, 1 table