 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePathwise Test-Time Correction for Autoregressive Long Video Generation
Feb 05, 2026Distilled autoregressive diffusion models facilitate real-time short video synthesis but suffer from severe error accumulation during long-sequence generation. While existing Test-Time Optimization (TTO) methods prove effective for images or short clips, we identify that they fail to mitigate drift in extended sequences due to unstable reward landscapes and the hypersensitivity of distilled parameters. To overcome these limitations, we introduce Test-Time Correction (TTC), a training-free alternative. Specifically, TTC utilizes the initial frame as a stable reference anchor to calibrate intermediate stochastic states along the sampling trajectory. Extensive experiments demonstrate that our method seamlessly integrates with various distilled models, extending generation lengths with negligible overhead while matching the quality of resource-intensive training-based methods on 30-second benchmarks.
LIVE: Long-horizon Interactive Video World Modeling
Feb 03, 2026Autoregressive video world models predict future visual observations conditioned on actions. While effective over short horizons, these models often struggle with long-horizon generation, as small prediction errors accumulate over time. Prior methods alleviate this by introducing pre-trained teacher models and sequence-level distribution matching, which incur additional computational cost and fail to prevent error propagation beyond the training horizon. In this work, we propose LIVE, a Long-horizon Interactive Video world modEl that enforces bounded error accumulation via a novel cycle-consistency objective, thereby eliminating the need for teacher-based distillation. Specifically, LIVE first performs a forward rollout from ground-truth frames and then applies a reverse generation process to reconstruct the initial state. The diffusion loss is subsequently computed on the reconstructed terminal state, providing an explicit constraint on long-horizon error propagation. Moreover, we provide an unified view that encompasses different approaches and introduce progressive training curriculum to stabilize training. Experiments demonstrate that LIVE achieves state-of-the-art performance on long-horizon benchmarks, generating stable, high-quality videos far beyond training rollout lengths.
Denoising Vision Transformer Autoencoder with Spectral Self-Regularization
Nov 16, 2025Variational autoencoders (VAEs) typically encode images into a compact latent space, reducing computational cost but introducing an optimization dilemma: a higher-dimensional latent space improves reconstruction fidelity but often hampers generative performance. Recent methods attempt to address this dilemma by regularizing high-dimensional latent spaces using external vision foundation models (VFMs). However, it remains unclear how high-dimensional VAE latents affect the optimization of generative models. To our knowledge, our analysis is the first to reveal that redundant high-frequency components in high-dimensional latent spaces hinder the training convergence of diffusion models and, consequently, degrade generation quality. To alleviate this problem, we propose a spectral self-regularization strategy to suppress redundant high-frequency noise while simultaneously preserving reconstruction quality. The resulting Denoising-VAE, a ViT-based autoencoder that does not rely on VFMs, produces cleaner, lower-noise latents, leading to improved generative quality and faster optimization convergence. We further introduce a spectral alignment strategy to facilitate the optimization of Denoising-VAE-based generative models. Our complete method enables diffusion models to converge approximately 2$\times$ faster than with SD-VAE, while achieving state-of-the-art reconstruction quality (rFID = 0.28, PSNR = 27.26) and competitive generation performance (gFID = 1.82) on the ImageNet 256$\times$256 benchmark.
FB-4D: Spatial-Temporal Coherent Dynamic 3D Content Generation with Feature Banks
Mar 26, 2025With the rapid advancements in diffusion models and 3D generation techniques, dynamic 3D content generation has become a crucial research area. However, achieving high-fidelity 4D (dynamic 3D) generation with strong spatial-temporal consistency remains a challenging task. Inspired by recent findings that pretrained diffusion features capture rich correspondences, we propose FB-4D, a novel 4D generation framework that integrates a Feature Bank mechanism to enhance both spatial and temporal consistency in generated frames. In FB-4D, we store features extracted from previous frames and fuse them into the process of generating subsequent frames, ensuring consistent characteristics across both time and multiple views. To ensure a compact representation, the Feature Bank is updated by a proposed dynamic merging mechanism. Leveraging this Feature Bank, we demonstrate for the first time that generating additional reference sequences through multiple autoregressive iterations can continuously improve generation performance. Experimental results show that FB-4D significantly outperforms existing methods in terms of rendering quality, spatial-temporal consistency, and robustness. It surpasses all multi-view generation tuning-free approaches by a large margin and achieves performance on par with training-based methods.
Diffusion-based Visual Anagram as Multi-task Learning
Dec 03, 2024



Visual anagrams are images that change appearance upon transformation, like flipping or rotation. With the advent of diffusion models, generating such optical illusions can be achieved by averaging noise across multiple views during the reverse denoising process. However, we observe two critical failure modes in this approach: (i) concept segregation, where concepts in different views are independently generated, which can not be considered a true anagram, and (ii) concept domination, where certain concepts overpower others. In this work, we cast the visual anagram generation problem in a multi-task learning setting, where different viewpoint prompts are analogous to different tasks,and derive denoising trajectories that align well across tasks simultaneously. At the core of our designed framework are two newly introduced techniques, where (i) an anti-segregation optimization strategy that promotes overlap in cross-attention maps between different concepts, and (ii) a noise vector balancing method that adaptively adjusts the influence of different tasks. Additionally, we observe that directly averaging noise predictions yields suboptimal performance because statistical properties may not be preserved, prompting us to derive a noise variance rectification method. Extensive qualitative and quantitative experiments demonstrate our method's superior ability to generate visual anagrams spanning diverse concepts.
Ctrl-U: Robust Conditional Image Generation via Uncertainty-aware Reward Modeling
Oct 15, 2024



In this paper, we focus on the task of conditional image generation, where an image is synthesized according to user instructions. The critical challenge underpinning this task is ensuring both the fidelity of the generated images and their semantic alignment with the provided conditions. To tackle this issue, previous studies have employed supervised perceptual losses derived from pre-trained models, i.e., reward models, to enforce alignment between the condition and the generated result. However, we observe one inherent shortcoming: considering the diversity of synthesized images, the reward model usually provides inaccurate feedback when encountering newly generated data, which can undermine the training process. To address this limitation, we propose an uncertainty-aware reward modeling, called Ctrl-U, including uncertainty estimation and uncertainty-aware regularization, designed to reduce the adverse effects of imprecise feedback from the reward model. Given the inherent cognitive uncertainty within reward models, even images generated under identical conditions often result in a relatively large discrepancy in reward loss. Inspired by the observation, we explicitly leverage such prediction variance as an uncertainty indicator. Based on the uncertainty estimation, we regularize the model training by adaptively rectifying the reward. In particular, rewards with lower uncertainty receive higher loss weights, while those with higher uncertainty are given reduced weights to allow for larger variability. The proposed uncertainty regularization facilitates reward fine-tuning through consistency construction. Extensive experiments validate the effectiveness of our methodology in improving the controllability and generation quality, as well as its scalability across diverse conditional scenarios. Code will soon be available at https://grenoble-zhang.github.io/Ctrl-U-Page/.
FairDiff: Fair Segmentation with Point-Image Diffusion
Jul 08, 2024

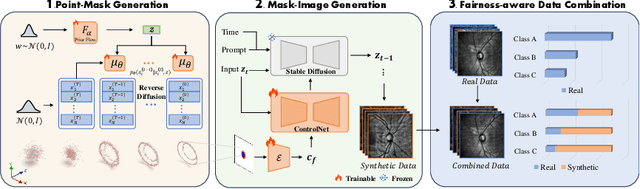

Fairness is an important topic for medical image analysis, driven by the challenge of unbalanced training data among diverse target groups and the societal demand for equitable medical quality. In response to this issue, our research adopts a data-driven strategy-enhancing data balance by integrating synthetic images. However, in terms of generating synthetic images, previous works either lack paired labels or fail to precisely control the boundaries of synthetic images to be aligned with those labels. To address this, we formulate the problem in a joint optimization manner, in which three networks are optimized towards the goal of empirical risk minimization and fairness maximization. On the implementation side, our solution features an innovative Point-Image Diffusion architecture, which leverages 3D point clouds for improved control over mask boundaries through a point-mask-image synthesis pipeline. This method outperforms significantly existing techniques in synthesizing scanning laser ophthalmoscopy (SLO) fundus images. By combining synthetic data with real data during the training phase using a proposed Equal Scale approach, our model achieves superior fairness segmentation performance compared to the state-of-the-art fairness learning models. Code is available at https://github.com/wenyi-li/FairDiff.
Infrared Small Target Detection Using Double-Weighted Multi-Granularity Patch Tensor Model With Tensor-Train Decomposition
Oct 09, 2023Infrared small target detection plays an important role in the remote sensing fields. Therefore, many detection algorithms have been proposed, in which the infrared patch-tensor (IPT) model has become a mainstream tool due to its excellent performance. However, most IPT-based methods face great challenges, such as inaccurate measure of the tensor low-rankness and poor robustness to complex scenes, which will leadto poor detection performance. In order to solve these problems, this paper proposes a novel double-weighted multi-granularity infrared patch tensor (DWMGIPT) model. First, to capture different granularity information of tensor from multiple modes, a multi-granularity infrared patch tensor (MGIPT) model is constructed by collecting nonoverlapping patches and tensor augmentation based on the tensor train (TT) decomposition. Second, to explore the latent structure of tensor more efficiently, we utilize the auto-weighted mechanism to balance the importance of information at different granularity. Then, the steering kernel (SK) is employed to extract local structure prior, which suppresses background interference such as strong edges and noise. Finally, an efficient optimization algorithm based on the alternating direction method of multipliers (ADMM) is presented to solve the model. Extensive experiments in various challenging scenes show that the proposed algorithm is robust to noise and different scenes. Compared with the other eight state-of-the-art methods, different evaluation metrics demonstrate that our method achieves better detection performance in various complex scenes.