 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFB-4D: Spatial-Temporal Coherent Dynamic 3D Content Generation with Feature Banks
Mar 26, 2025With the rapid advancements in diffusion models and 3D generation techniques, dynamic 3D content generation has become a crucial research area. However, achieving high-fidelity 4D (dynamic 3D) generation with strong spatial-temporal consistency remains a challenging task. Inspired by recent findings that pretrained diffusion features capture rich correspondences, we propose FB-4D, a novel 4D generation framework that integrates a Feature Bank mechanism to enhance both spatial and temporal consistency in generated frames. In FB-4D, we store features extracted from previous frames and fuse them into the process of generating subsequent frames, ensuring consistent characteristics across both time and multiple views. To ensure a compact representation, the Feature Bank is updated by a proposed dynamic merging mechanism. Leveraging this Feature Bank, we demonstrate for the first time that generating additional reference sequences through multiple autoregressive iterations can continuously improve generation performance. Experimental results show that FB-4D significantly outperforms existing methods in terms of rendering quality, spatial-temporal consistency, and robustness. It surpasses all multi-view generation tuning-free approaches by a large margin and achieves performance on par with training-based methods.
La-SoftMoE CLIP for Unified Physical-Digital Face Attack Detection
Aug 23, 2024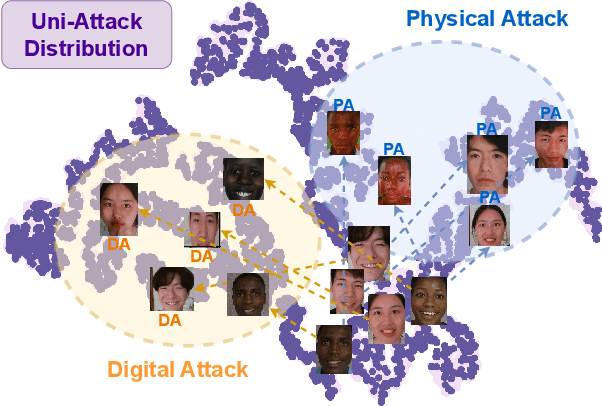
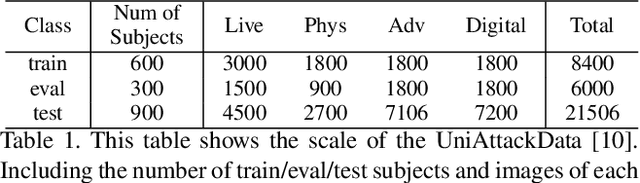
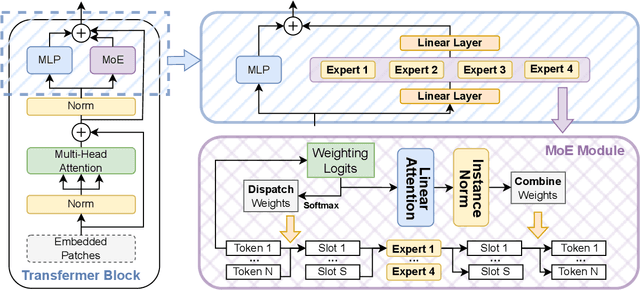

Facial recognition systems are susceptible to both physical and digital attacks, posing significant security risks. Traditional approaches often treat these two attack types separately due to their distinct characteristics. Thus, when being combined attacked, almost all methods could not deal. Some studies attempt to combine the sparse data from both types of attacks into a single dataset and try to find a common feature space, which is often impractical due to the space is difficult to be found or even non-existent. To overcome these challenges, we propose a novel approach that uses the sparse model to handle sparse data, utilizing different parameter groups to process distinct regions of the sparse feature space. Specifically, we employ the Mixture of Experts (MoE) framework in our model, expert parameters are matched to tokens with varying weights during training and adaptively activated during testing. However, the traditional MoE struggles with the complex and irregular classification boundaries of this problem. Thus, we introduce a flexible self-adapting weighting mechanism, enabling the model to better fit and adapt. In this paper, we proposed La-SoftMoE CLIP, which allows for more flexible adaptation to the Unified Attack Detection (UAD) task, significantly enhancing the model's capability to handle diversity attacks. Experiment results demonstrate that our proposed method has SOTA performance.
A Unified Framework for Iris Anti-Spoofing: Introducing IrisGeneral Dataset and Masked-MoE Method
Aug 19, 2024



Iris recognition is widely used in high-security scenarios due to its stability and distinctiveness. However, the acquisition of iris images typically requires near-infrared illumination and near-infrared band filters, leading to significant and consistent differences in imaging across devices. This underscores the importance of developing cross-domain capabilities in iris anti-spoofing methods. Despite this need, there is no dataset available that comprehensively evaluates the generalization ability of the iris anti-spoofing task. To address this gap, we propose the IrisGeneral dataset, which includes 10 subsets, belonging to 7 databases, published by 4 institutions, collected with 6 types of devices. IrisGeneral is designed with three protocols, aimed at evaluating average performance, cross-racial generalization, and cross-device generalization of iris anti-spoofing models. To tackle the challenge of integrating multiple sub-datasets in IrisGeneral, we employ multiple parameter sets to learn from the various subsets. Specifically, we utilize the Mixture of Experts (MoE) to fit complex data distributions using multiple sub-neural networks. To further enhance the generalization capabilities, we introduce a novel method Masked-MoE (MMoE). It randomly masks a portion of tokens for some experts and requires their outputs to be similar to the unmasked experts, which improves the generalization ability and effectively mitigates the overfitting issue produced by MoE. We selected ResNet50, VIT-B/16, CLIP, and FLIP as representative models and benchmarked them on the IrisGeneral dataset. Experimental results demonstrate that our proposed MMoE with CLIP achieves the best performance on IrisGeneral.