 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeW2T: LoRA Weights Already Know What They Can Do
Mar 16, 2026Each LoRA checkpoint compactly stores task-specific updates in low-rank weight matrices, offering an efficient way to adapt large language models to new tasks and domains. In principle, these weights already encode what the adapter does and how well it performs. In this paper, we ask whether this information can be read directly from the weights, without running the base model or accessing training data. A key obstacle is that a single LoRA update can be factorized in infinitely many ways. Without resolving this ambiguity, models trained on the factors may fit the particular factorization rather than the underlying update. To this end, we propose \methodfull, which maps each LoRA update to a provably canonical form via QR decomposition followed by SVD, so that all equivalent factorizations share the same representation. The resulting components are then tokenized and processed by a Transformer to produce a weight-space embedding. Across language and vision LoRA collections, W2T achieves strong results on attribute classification, performance prediction, and adapter retrieval, demonstrating that LoRA weights reliably indicate model behavior once factorization ambiguity is removed. Code is available at https://github.com/xiaolonghan2000/Weight2Token.
PUGS: Zero-shot Physical Understanding with Gaussian Splatting
Feb 17, 2025
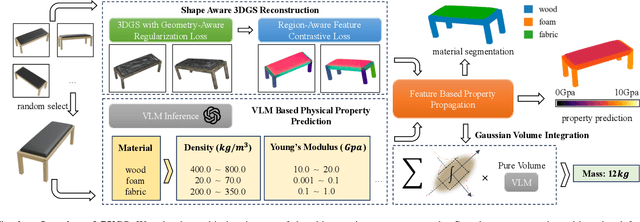


Current robotic systems can understand the categories and poses of objects well. But understanding physical properties like mass, friction, and hardness, in the wild, remains challenging. We propose a new method that reconstructs 3D objects using the Gaussian splatting representation and predicts various physical properties in a zero-shot manner. We propose two techniques during the reconstruction phase: a geometry-aware regularization loss function to improve the shape quality and a region-aware feature contrastive loss function to promote region affinity. Two other new techniques are designed during inference: a feature-based property propagation module and a volume integration module tailored for the Gaussian representation. Our framework is named as zero-shot physical understanding with Gaussian splatting, or PUGS. PUGS achieves new state-of-the-art results on the standard benchmark of ABO-500 mass prediction. We provide extensive quantitative ablations and qualitative visualization to demonstrate the mechanism of our designs. We show the proposed methodology can help address challenging real-world grasping tasks. Our codes, data, and models are available at https://github.com/EverNorif/PUGS
Ctrl-U: Robust Conditional Image Generation via Uncertainty-aware Reward Modeling
Oct 15, 2024



In this paper, we focus on the task of conditional image generation, where an image is synthesized according to user instructions. The critical challenge underpinning this task is ensuring both the fidelity of the generated images and their semantic alignment with the provided conditions. To tackle this issue, previous studies have employed supervised perceptual losses derived from pre-trained models, i.e., reward models, to enforce alignment between the condition and the generated result. However, we observe one inherent shortcoming: considering the diversity of synthesized images, the reward model usually provides inaccurate feedback when encountering newly generated data, which can undermine the training process. To address this limitation, we propose an uncertainty-aware reward modeling, called Ctrl-U, including uncertainty estimation and uncertainty-aware regularization, designed to reduce the adverse effects of imprecise feedback from the reward model. Given the inherent cognitive uncertainty within reward models, even images generated under identical conditions often result in a relatively large discrepancy in reward loss. Inspired by the observation, we explicitly leverage such prediction variance as an uncertainty indicator. Based on the uncertainty estimation, we regularize the model training by adaptively rectifying the reward. In particular, rewards with lower uncertainty receive higher loss weights, while those with higher uncertainty are given reduced weights to allow for larger variability. The proposed uncertainty regularization facilitates reward fine-tuning through consistency construction. Extensive experiments validate the effectiveness of our methodology in improving the controllability and generation quality, as well as its scalability across diverse conditional scenarios. Code will soon be available at https://grenoble-zhang.github.io/Ctrl-U-Page/.
Spectrum of non-Hermitian deep-Hebbian neural networks
Aug 24, 2022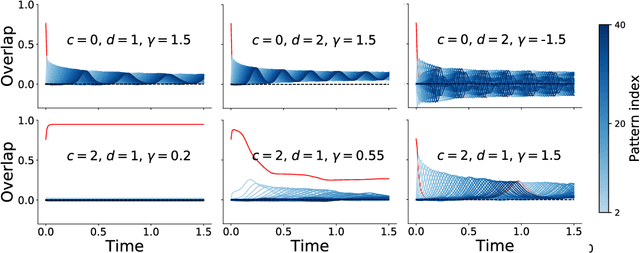
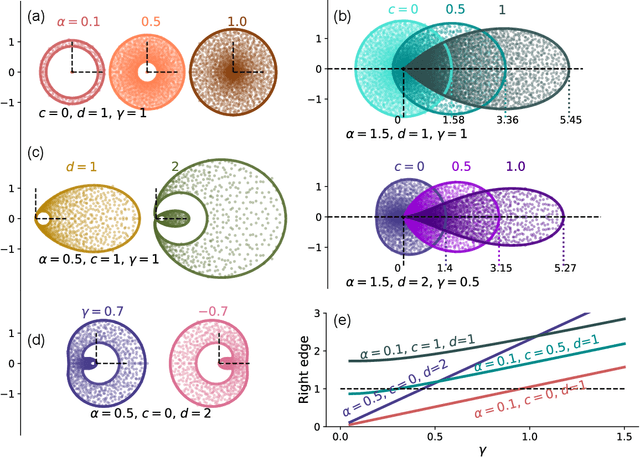
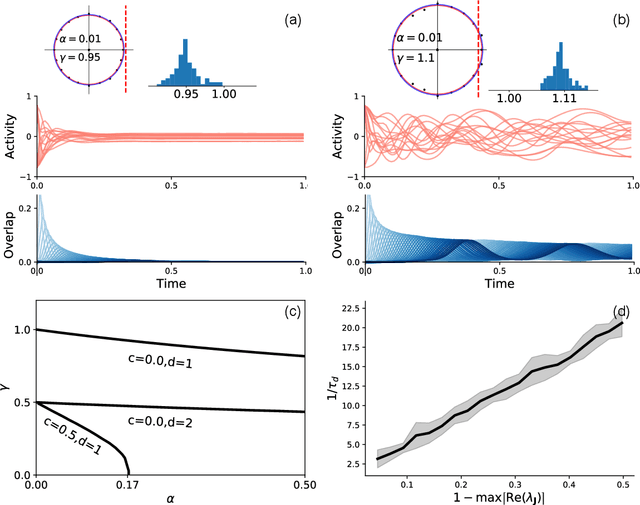
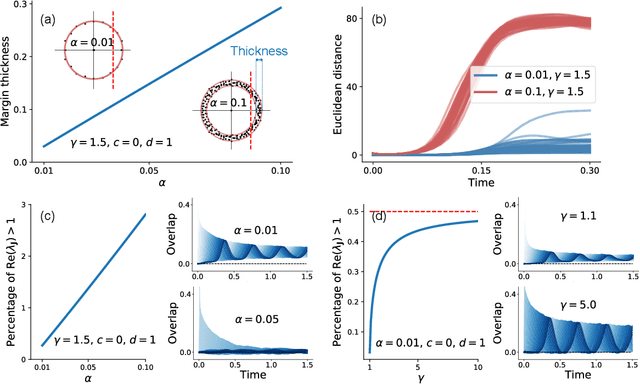
Neural networks with recurrent asymmetric couplings are important to understand how episodic memories are encoded in the brain. Here, we integrate the experimental observation of wide synaptic integration window into our model of sequence retrieval in the continuous time dynamics. The model with non-normal neuron-interactions is theoretically studied by deriving a random matrix theory of the Jacobian matrix in neural dynamics. The spectra bears several distinct features, such as breaking rotational symmetry about the origin, and the emergence of nested voids within the spectrum boundary. The spectral density is thus highly non-uniformly distributed in the complex plane. The random matrix theory also predicts a transition to chaos. In particular, the edge of chaos provides computational benefits for the sequential retrieval of memories. Our work provides a systematic study of time-lagged correlations with arbitrary time delays, and thus can inspire future studies of a broad class of memory models, and even big data analysis of biological time series.
A comparative study of deep learning methods for building footprints detection using high spatial resolution aerial images
Mar 16, 2021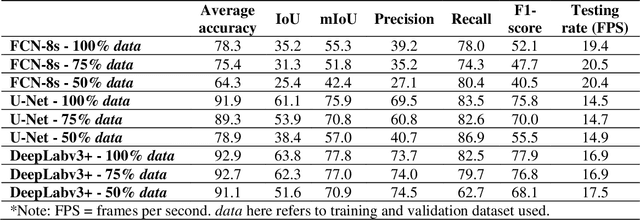

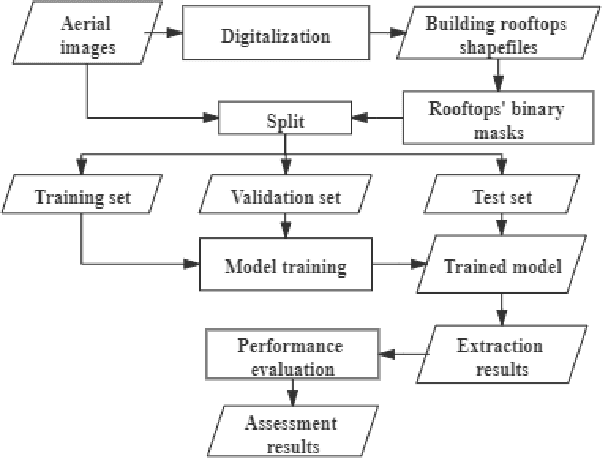
Building footprints data is of importance in several urban applications and natural disaster management. In contrast to traditional surveying and mapping, using high spatial resolution aerial images, deep learning-based building footprints extraction methods can extract building footprints accurately and efficiently. With rapidly development of deep learning methods, it is hard for novice to harness the powerful tools in building footprints extraction. The paper aims at providing the whole process of building footprints extraction from high spatial resolution images using deep learning-based methods. In addition, we also compare the commonly used methods, including Fully Convolutional Networks (FCN)-8s, U-Net and DeepLabv3+. At the end of the work, we change the data size used in models training to explore the influence of data size to the performance of the algorithms. The experiments show that, in different data size, DeepLabv3+ is the best algorithm among them with the highest accuracy and moderate efficiency; FCN-8s has the worst accuracy and highest efficiency; U-Net shows the moderate accuracy and lowest efficiency. In addition, with more training data, algorithms converged faster with higher accuracy in extraction results.
Relationship between manifold smoothness and adversarial vulnerability in deep learning with local errors
Jul 04, 2020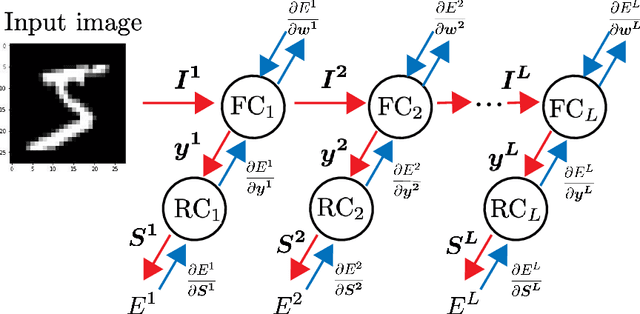
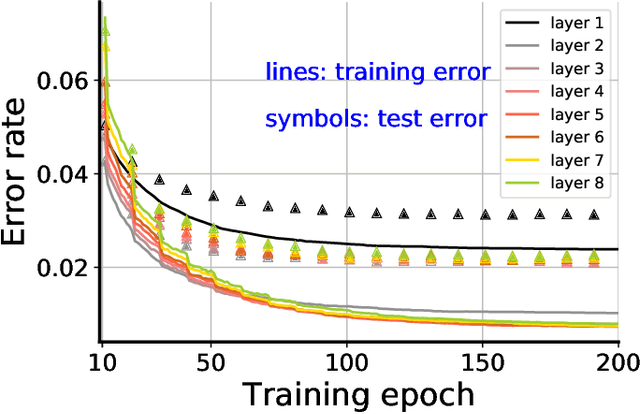
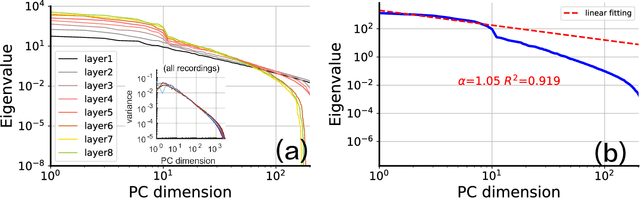
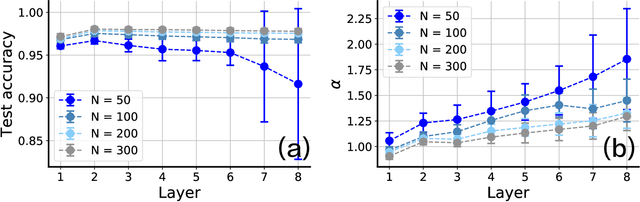
Artificial neural networks can achieve impressive performances, and even outperform humans in some specific tasks. Nevertheless, unlike biological brains, the artificial neural networks suffer from tiny perturbations in sensory input, under various kinds of adversarial attacks. It is therefore necessary to study the origin of the adversarial vulnerability. Here, we establish a fundamental relationship between geometry of hidden representations (manifold perspective) and the generalization capability of the deep networks. For this purpose, we choose a deep neural network trained by local errors, and then analyze emergent properties of trained networks through the manifold dimensionality, manifold smoothness, and the generalization capability. To explore effects of adversarial examples, we consider independent Gaussian noise attacks and fast-gradient-sign-method (FGSM) attacks. Our study reveals that a high generalization accuracy requires a relatively fast power-law decay of the eigen-spectrum of hidden representations. Under Gaussian attacks, the relationship between generalization accuracy and power-law exponent is monotonic, while a non-monotonic behavior is observed for FGSM attacks. Our empirical study provides a route towards a final mechanistic interpretation of adversarial vulnerability under adversarial attacks.