 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelationship between manifold smoothness and adversarial vulnerability in deep learning with local errors
Paper and Code
Jul 04, 2020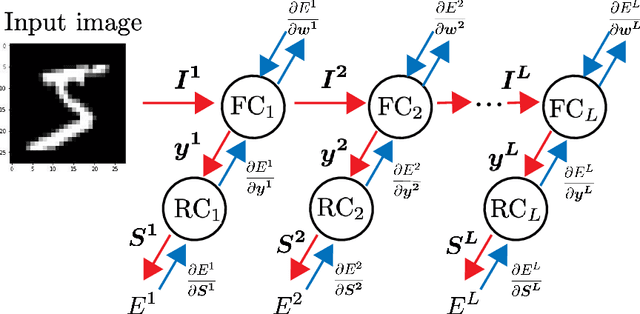
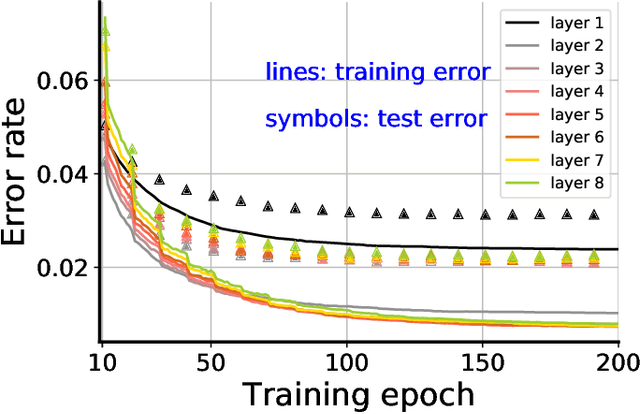
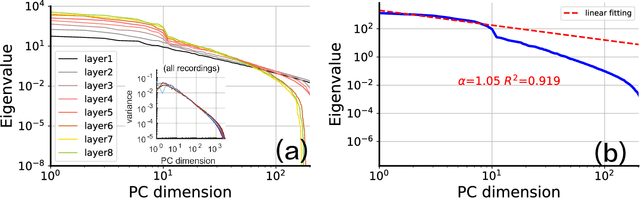
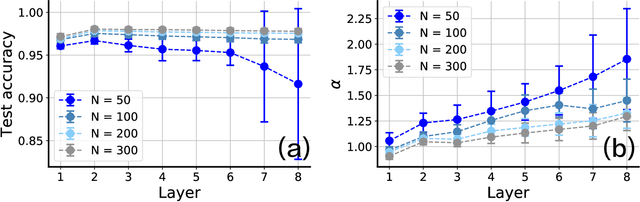
Artificial neural networks can achieve impressive performances, and even outperform humans in some specific tasks. Nevertheless, unlike biological brains, the artificial neural networks suffer from tiny perturbations in sensory input, under various kinds of adversarial attacks. It is therefore necessary to study the origin of the adversarial vulnerability. Here, we establish a fundamental relationship between geometry of hidden representations (manifold perspective) and the generalization capability of the deep networks. For this purpose, we choose a deep neural network trained by local errors, and then analyze emergent properties of trained networks through the manifold dimensionality, manifold smoothness, and the generalization capability. To explore effects of adversarial examples, we consider independent Gaussian noise attacks and fast-gradient-sign-method (FGSM) attacks. Our study reveals that a high generalization accuracy requires a relatively fast power-law decay of the eigen-spectrum of hidden representations. Under Gaussian attacks, the relationship between generalization accuracy and power-law exponent is monotonic, while a non-monotonic behavior is observed for FGSM attacks. Our empirical study provides a route towards a final mechanistic interpretation of adversarial vulnerability under adversarial attacks.