 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmni-Perception Policy Optimization for Multimodal Emotion Reasoning
Jun 24, 2026We find that current emotion-oriented Omni-MLLMs still lack reliable omni-modal perception: they (i) underutilize multimodal cues in their reasoning trajectories and (ii) exhibit unfaithful behavior, often hallucinating modality-specific statements from other modalities. Building on these insights, we propose OPPO (Omni-Perception Policy Optimization), a reinforcement learning framework that explicitly optimizes multimodal perception. First, an Omni-Perception Reward decomposes ground-truth reasoning into fine-grained visual, acoustic, and emotion cues and rewards trajectories that semantically recover these cues. Second, an Omni-Perception Loss compares the policy under full and unimodally masked inputs, applying a KL penalty only to modality-specific evidence tokens to suppress cross-modal hallucination. We further introduce MEP-Bench, a diagnostic benchmark that quantifies utilization and faithfulness. Experiments show that OPPO achieves state-of-the-art performance on MER-UniBench and MME-Emotion, while substantially improving utilization and faithfulness scores on MEP-Bench, highlighting the importance of sufficient and faithful omni perception for multimodal emotion reasoning.
InterSketch: An Interleaved Reasoning Model with Self-correcting Visual Sketch and Stepwise Reward
May 26, 2026While vision-language models (VLMs) have exhibited multi-turn visual reasoning capabilities, their reasoning trajectories remain relatively shallow and are dominated by a text-centric paradigm, limiting their applicability to complex visual challenges. In contrast, human-like thought typically involves long-horizon reasoning with an interleaved visual-textual chain-of-thought (VT-CoT). To bridge this gap, we introduce InterSketch, an interleaved reasoning model to enhance the VT-CoT capability via self-correcting and stepwise reward mechanisms. InterSketch dynamically generates intermediate visual sketches using external tools and interleaves them with textual reasoning, enabling effective perception and logical reasoning over long-horizon visual understanding tasks. Specifically, in the first cold-start stage, we propose a synthesized high-quality interleaved VT-CoT dataset and include a reflection mechanism to enable the model's capability in multi-turn interleaved reasoning and self-correction. In the subsequent reinforcement learning (RL) stage, we design a stepwise reward mechanism to mitigate the sparsity of reward signals inherent in end-only supervision over long-horizon reasoning. Extensive experiments on visual reasoning benchmarks demonstrate the effectiveness of InterSketch, even outperforming proprietary models such as Gemini-3-Pro.
SenseNova-U1: Unifying Multimodal Understanding and Generation with NEO-unify Architecture
May 12, 2026Recent large vision-language models (VLMs) remain fundamentally constrained by a persistent dichotomy: understanding and generation are treated as distinct problems, leading to fragmented architectures, cascaded pipelines, and misaligned representation spaces. We argue that this divide is not merely an engineering artifact, but a structural limitation that hinders the emergence of native multimodal intelligence. Hence, we introduce SenseNova-U1, a native unified multimodal paradigm built upon NEO-unify, in which understanding and generation evolve as synergistic views of a single underlying process. We launch two native unified variants, SenseNova-U1-8B-MoT and SenseNova-U1-A3B-MoT, built on dense (8B) and mixture-of-experts (30B-A3B) understanding baselines, respectively. Designed from first principles, they rival top-tier understanding-only VLMs across text understanding, vision-language perception, knowledge reasoning, agentic decision-making, and spatial intelligence. Meanwhile, they deliver strong semantic consistency and visual fidelity, excelling in conventional or knowledge-intensive any-to-image (X2I) synthesis, complex text-rich infographic generation, and interleaved vision-language generation, with or without think patterns. Beyond performance, we show detailed model design, data preprocessing, pre-/post-training, and inference strategies to support community research. Last but not least, preliminary evidence demonstrates that our models extend beyond perception and generation, performing strongly in vision-language-action (VLA) and world model (WM) scenarios. This points toward a broader roadmap where models do not translate between modalities, but think and act across them in a native manner. Multimodal AI is no longer about connecting separate systems, but about building a unified one and trusting the necessary capabilities to emerge from within.
V-ABS: Action-Observer Driven Beam Search for Dynamic Visual Reasoning
May 11, 2026Multimodal large language models (MLLMs) have achieved remarkable success in general perception, yet complex multi-step visual reasoning remains a persistent challenge. Although recent agentic approaches incorporate tool use, they often neglect critical execution feedback. Consequently, they suffer from the imagination-action-observer (IAO) bias, a misalignment between prior imagination and observer feedback that undermines reasoning stability and optimality. To bridge this gap, we introduce V-ABS, an action-observer driven beam search framework that enables deliberate reasoning through thinker-actor-observer iterations. We also propose an entropy-based adaptive weighting algorithm to mitigate the IAO bias by dynamically balancing the confidence scores between the policy priors and the observational feedback. Moreover, we construct a large-scale supervised fine-tuning (SFT) dataset comprising over 80k samples to guide the model to assign higher prior confidence to correct action paths. Extensive experiments across eight diverse benchmarks show that V-ABS achieves state-of-the-art performance, delivering an average improvement of 19.7% on the Qwen3-VL-8B baseline and consistent gains across both open-source and proprietary models.
SenseNova-MARS: Empowering Multimodal Agentic Reasoning and Search via Reinforcement Learning
Dec 30, 2025While Vision-Language Models (VLMs) can solve complex tasks through agentic reasoning, their capabilities remain largely constrained to text-oriented chain-of-thought or isolated tool invocation. They fail to exhibit the human-like proficiency required to seamlessly interleave dynamic tool manipulation with continuous reasoning, particularly in knowledge-intensive and visually complex scenarios that demand coordinated external tools such as search and image cropping. In this work, we introduce SenseNova-MARS, a novel Multimodal Agentic Reasoning and Search framework that empowers VLMs with interleaved visual reasoning and tool-use capabilities via reinforcement learning (RL). Specifically, SenseNova-MARS dynamically integrates the image search, text search, and image crop tools to tackle fine-grained and knowledge-intensive visual understanding challenges. In the RL stage, we propose the Batch-Normalized Group Sequence Policy Optimization (BN-GSPO) algorithm to improve the training stability and advance the model's ability to invoke tools and reason effectively. To comprehensively evaluate the agentic VLMs on complex visual tasks, we introduce the HR-MMSearch benchmark, the first search-oriented benchmark composed of high-resolution images with knowledge-intensive and search-driven questions. Experiments demonstrate that SenseNova-MARS achieves state-of-the-art performance on open-source search and fine-grained image understanding benchmarks. Specifically, on search-oriented benchmarks, SenseNova-MARS-8B scores 67.84 on MMSearch and 41.64 on HR-MMSearch, surpassing proprietary models such as Gemini-3-Flash and GPT-5. SenseNova-MARS represents a promising step toward agentic VLMs by providing effective and robust tool-use capabilities. To facilitate further research in this field, we will release all code, models, and datasets.
How Far Are We to GPT-4V? Closing the Gap to Commercial Multimodal Models with Open-Source Suites
Apr 29, 2024



In this report, we introduce InternVL 1.5, an open-source multimodal large language model (MLLM) to bridge the capability gap between open-source and proprietary commercial models in multimodal understanding. We introduce three simple improvements: (1) Strong Vision Encoder: we explored a continuous learning strategy for the large-scale vision foundation model -- InternViT-6B, boosting its visual understanding capabilities, and making it can be transferred and reused in different LLMs. (2) Dynamic High-Resolution: we divide images into tiles ranging from 1 to 40 of 448$\times$448 pixels according to the aspect ratio and resolution of the input images, which supports up to 4K resolution input. (3) High-Quality Bilingual Dataset: we carefully collected a high-quality bilingual dataset that covers common scenes, document images, and annotated them with English and Chinese question-answer pairs, significantly enhancing performance in OCR- and Chinese-related tasks. We evaluate InternVL 1.5 through a series of benchmarks and comparative studies. Compared to both open-source and proprietary models, InternVL 1.5 shows competitive performance, achieving state-of-the-art results in 8 of 18 benchmarks. Code has been released at https://github.com/OpenGVLab/InternVL.
DriveMLM: Aligning Multi-Modal Large Language Models with Behavioral Planning States for Autonomous Driving
Dec 25, 2023

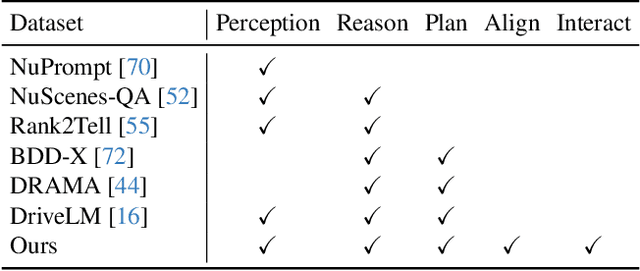
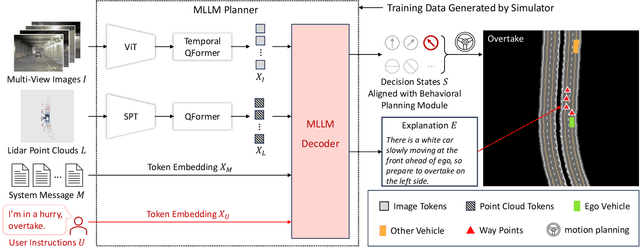
Large language models (LLMs) have opened up new possibilities for intelligent agents, endowing them with human-like thinking and cognitive abilities. In this work, we delve into the potential of large language models (LLMs) in autonomous driving (AD). We introduce DriveMLM, an LLM-based AD framework that can perform close-loop autonomous driving in realistic simulators. To this end, (1) we bridge the gap between the language decisions and the vehicle control commands by standardizing the decision states according to the off-the-shelf motion planning module. (2) We employ a multi-modal LLM (MLLM) to model the behavior planning module of a module AD system, which uses driving rules, user commands, and inputs from various sensors (e.g., camera, lidar) as input and makes driving decisions and provide explanations; This model can plug-and-play in existing AD systems such as Apollo for close-loop driving. (3) We design an effective data engine to collect a dataset that includes decision state and corresponding explanation annotation for model training and evaluation. We conduct extensive experiments and show that our model achieves 76.1 driving score on the CARLA Town05 Long, and surpasses the Apollo baseline by 4.7 points under the same settings, demonstrating the effectiveness of our model. We hope this work can serve as a baseline for autonomous driving with LLMs. Code and models shall be released at https://github.com/OpenGVLab/DriveMLM.
Scene as Occupancy
Jun 06, 2023Human driver can easily describe the complex traffic scene by visual system. Such an ability of precise perception is essential for driver's planning. To achieve this, a geometry-aware representation that quantizes the physical 3D scene into structured grid map with semantic labels per cell, termed as 3D Occupancy, would be desirable. Compared to the form of bounding box, a key insight behind occupancy is that it could capture the fine-grained details of critical obstacles in the scene, and thereby facilitate subsequent tasks. Prior or concurrent literature mainly concentrate on a single scene completion task, where we might argue that the potential of this occupancy representation might obsess broader impact. In this paper, we propose OccNet, a multi-view vision-centric pipeline with a cascade and temporal voxel decoder to reconstruct 3D occupancy. At the core of OccNet is a general occupancy embedding to represent 3D physical world. Such a descriptor could be applied towards a wide span of driving tasks, including detection, segmentation and planning. To validate the effectiveness of this new representation and our proposed algorithm, we propose OpenOcc, the first dense high-quality 3D occupancy benchmark built on top of nuScenes. Empirical experiments show that there are evident performance gain across multiple tasks, e.g., motion planning could witness a collision rate reduction by 15%-58%, demonstrating the superiority of our method.
3D Data Augmentation for Driving Scenes on Camera
Mar 18, 2023



Driving scenes are extremely diverse and complicated that it is impossible to collect all cases with human effort alone. While data augmentation is an effective technique to enrich the training data, existing methods for camera data in autonomous driving applications are confined to the 2D image plane, which may not optimally increase data diversity in 3D real-world scenarios. To this end, we propose a 3D data augmentation approach termed Drive-3DAug, aiming at augmenting the driving scenes on camera in the 3D space. We first utilize Neural Radiance Field (NeRF) to reconstruct the 3D models of background and foreground objects. Then, augmented driving scenes can be obtained by placing the 3D objects with adapted location and orientation at the pre-defined valid region of backgrounds. As such, the training database could be effectively scaled up. However, the 3D object modeling is constrained to the image quality and the limited viewpoints. To overcome these problems, we modify the original NeRF by introducing a geometric rectified loss and a symmetric-aware training strategy. We evaluate our method for the camera-only monocular 3D detection task on the Waymo and nuScences datasets. The proposed data augmentation approach contributes to a gain of 1.7% and 1.4% in terms of detection accuracy, on Waymo and nuScences respectively. Furthermore, the constructed 3D models serve as digital driving assets and could be recycled for different detectors or other 3D perception tasks.