 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Pixels to Words -- Towards Native Vision-Language Primitives at Scale
Oct 16, 2025The edifice of native Vision-Language Models (VLMs) has emerged as a rising contender to typical modular VLMs, shaped by evolving model architectures and training paradigms. Yet, two lingering clouds cast shadows over its widespread exploration and promotion: (-) What fundamental constraints set native VLMs apart from modular ones, and to what extent can these barriers be overcome? (-) How to make research in native VLMs more accessible and democratized, thereby accelerating progress in the field. In this paper, we clarify these challenges and outline guiding principles for constructing native VLMs. Specifically, one native VLM primitive should: (i) effectively align pixel and word representations within a shared semantic space; (ii) seamlessly integrate the strengths of formerly separate vision and language modules; (iii) inherently embody various cross-modal properties that support unified vision-language encoding, aligning, and reasoning. Hence, we launch NEO, a novel family of native VLMs built from first principles, capable of rivaling top-tier modular counterparts across diverse real-world scenarios. With only 390M image-text examples, NEO efficiently develops visual perception from scratch while mitigating vision-language conflicts inside a dense and monolithic model crafted from our elaborate primitives. We position NEO as a cornerstone for scalable and powerful native VLMs, paired with a rich set of reusable components that foster a cost-effective and extensible ecosystem. Our code and models are publicly available at: https://github.com/EvolvingLMMs-Lab/NEO.
DriveMLM: Aligning Multi-Modal Large Language Models with Behavioral Planning States for Autonomous Driving
Dec 25, 2023

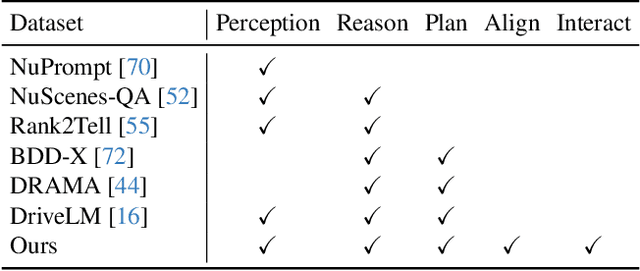
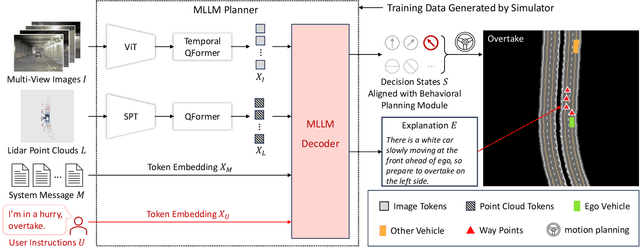
Large language models (LLMs) have opened up new possibilities for intelligent agents, endowing them with human-like thinking and cognitive abilities. In this work, we delve into the potential of large language models (LLMs) in autonomous driving (AD). We introduce DriveMLM, an LLM-based AD framework that can perform close-loop autonomous driving in realistic simulators. To this end, (1) we bridge the gap between the language decisions and the vehicle control commands by standardizing the decision states according to the off-the-shelf motion planning module. (2) We employ a multi-modal LLM (MLLM) to model the behavior planning module of a module AD system, which uses driving rules, user commands, and inputs from various sensors (e.g., camera, lidar) as input and makes driving decisions and provide explanations; This model can plug-and-play in existing AD systems such as Apollo for close-loop driving. (3) We design an effective data engine to collect a dataset that includes decision state and corresponding explanation annotation for model training and evaluation. We conduct extensive experiments and show that our model achieves 76.1 driving score on the CARLA Town05 Long, and surpasses the Apollo baseline by 4.7 points under the same settings, demonstrating the effectiveness of our model. We hope this work can serve as a baseline for autonomous driving with LLMs. Code and models shall be released at https://github.com/OpenGVLab/DriveMLM.
Scene as Occupancy
Jun 06, 2023Human driver can easily describe the complex traffic scene by visual system. Such an ability of precise perception is essential for driver's planning. To achieve this, a geometry-aware representation that quantizes the physical 3D scene into structured grid map with semantic labels per cell, termed as 3D Occupancy, would be desirable. Compared to the form of bounding box, a key insight behind occupancy is that it could capture the fine-grained details of critical obstacles in the scene, and thereby facilitate subsequent tasks. Prior or concurrent literature mainly concentrate on a single scene completion task, where we might argue that the potential of this occupancy representation might obsess broader impact. In this paper, we propose OccNet, a multi-view vision-centric pipeline with a cascade and temporal voxel decoder to reconstruct 3D occupancy. At the core of OccNet is a general occupancy embedding to represent 3D physical world. Such a descriptor could be applied towards a wide span of driving tasks, including detection, segmentation and planning. To validate the effectiveness of this new representation and our proposed algorithm, we propose OpenOcc, the first dense high-quality 3D occupancy benchmark built on top of nuScenes. Empirical experiments show that there are evident performance gain across multiple tasks, e.g., motion planning could witness a collision rate reduction by 15%-58%, demonstrating the superiority of our method.