 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeISE: An Execution-Grounded Recipe for Multi-Turn OS-Agent Trajectories
Jun 09, 2026Training capable OS agents requires data that simultaneously captures structured user intents, multi-turn task delegation, and grounded tool execution--properties absent from existing datasets. We propose ISE (Intent -> Simulate -> Execute), a three-stage synthesis paradigm that addresses these gaps jointly. Stage 1 constructs roughly 50000 structured intents via a 4D framework (Persona x Domain x Task x Complexity); after deduplication the pool contains 43956 unique intents and attains a Vendi Score of 61.57 over the entire pool on mpnet-base-v2 embeddings (cosine kernel, q=1). Stage 2 drives multi-turn user-agent interaction through a role-locked user simulator that grounds each user turn in actual execution outcomes, producing 23132 complete trajectories averaging 8.12 user turns and 68.24 total dialogue turns. Stage 3 runs every tool call inside a live, isolated OS workspace, generating authentic failure-recovery dynamics instead of simulated responses. Fine-tuning on ISETrace improves ClawEval pass@1 from 19.3 to 37.7 using Qwen3-8B on agent tool-use tasks with a standard protocol. This result outperforms zero-shot GPT-4o and the larger Qwen3-32B base model which is four times bigger. An ablation on Stage 2 proves multi-turn simulation brings a large portion of the performance gain. We release all source code and dataset at https://github.com/Valiere01/ISE-Trace.
ICA: Information-Aware Credit Assignment for Visually Grounded Long-Horizon Information-Seeking Agents
Feb 11, 2026Despite the strong performance achieved by reinforcement learning-trained information-seeking agents, learning in open-ended web environments remains severely constrained by low signal-to-noise feedback. Text-based parsers often discard layout semantics and introduce unstructured noise, while long-horizon training typically relies on sparse outcome rewards that obscure which retrieval actions actually matter. We propose a visual-native search framework that represents webpages as visual snapshots, allowing agents to leverage layout cues to quickly localize salient evidence and suppress distractors. To learn effectively from these high-dimensional observations, we introduce Information-Aware Credit Assignment (ICA), a post-hoc method that estimates each retrieved snapshot's contribution to the final outcome via posterior analysis and propagates dense learning signals back to key search turns. Integrated with a GRPO-based training pipeline, our approach consistently outperforms text-based baselines on diverse information-seeking benchmarks, providing evidence that visual snapshot grounding with information-level credit assignment alleviates the credit-assignment bottleneck in open-ended web environments. The code and datasets will be released in https://github.com/pc-inno/ICA_MM_deepsearch.git.
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Apr 15, 2025We introduce InternVL3, a significant advancement in the InternVL series featuring a native multimodal pre-training paradigm. Rather than adapting a text-only large language model (LLM) into a multimodal large language model (MLLM) that supports visual inputs, InternVL3 jointly acquires multimodal and linguistic capabilities from both diverse multimodal data and pure-text corpora during a single pre-training stage. This unified training paradigm effectively addresses the complexities and alignment challenges commonly encountered in conventional post-hoc training pipelines for MLLMs. To further improve performance and scalability, InternVL3 incorporates variable visual position encoding (V2PE) to support extended multimodal contexts, employs advanced post-training techniques such as supervised fine-tuning (SFT) and mixed preference optimization (MPO), and adopts test-time scaling strategies alongside an optimized training infrastructure. Extensive empirical evaluations demonstrate that InternVL3 delivers superior performance across a wide range of multi-modal tasks. In particular, InternVL3-78B achieves a score of 72.2 on the MMMU benchmark, setting a new state-of-the-art among open-source MLLMs. Its capabilities remain highly competitive with leading proprietary models, including ChatGPT-4o, Claude 3.5 Sonnet, and Gemini 2.5 Pro, while also maintaining strong pure-language proficiency. In pursuit of open-science principles, we will publicly release both the training data and model weights to foster further research and development in next-generation MLLMs.
Expanding Performance Boundaries of Open-Source Multimodal Models with Model, Data, and Test-Time Scaling
Dec 06, 2024



We introduce InternVL 2.5, an advanced multimodal large language model (MLLM) series that builds upon InternVL 2.0, maintaining its core model architecture while introducing significant enhancements in training and testing strategies as well as data quality. In this work, we delve into the relationship between model scaling and performance, systematically exploring the performance trends in vision encoders, language models, dataset sizes, and test-time configurations. Through extensive evaluations on a wide range of benchmarks, including multi-discipline reasoning, document understanding, multi-image / video understanding, real-world comprehension, multimodal hallucination detection, visual grounding, multilingual capabilities, and pure language processing, InternVL 2.5 exhibits competitive performance, rivaling leading commercial models such as GPT-4o and Claude-3.5-Sonnet. Notably, our model is the first open-source MLLMs to surpass 70% on the MMMU benchmark, achieving a 3.7-point improvement through Chain-of-Thought (CoT) reasoning and showcasing strong potential for test-time scaling. We hope this model contributes to the open-source community by setting new standards for developing and applying multimodal AI systems. HuggingFace demo see https://huggingface.co/spaces/OpenGVLab/InternVL
How Far Are We to GPT-4V? Closing the Gap to Commercial Multimodal Models with Open-Source Suites
Apr 29, 2024



In this report, we introduce InternVL 1.5, an open-source multimodal large language model (MLLM) to bridge the capability gap between open-source and proprietary commercial models in multimodal understanding. We introduce three simple improvements: (1) Strong Vision Encoder: we explored a continuous learning strategy for the large-scale vision foundation model -- InternViT-6B, boosting its visual understanding capabilities, and making it can be transferred and reused in different LLMs. (2) Dynamic High-Resolution: we divide images into tiles ranging from 1 to 40 of 448$\times$448 pixels according to the aspect ratio and resolution of the input images, which supports up to 4K resolution input. (3) High-Quality Bilingual Dataset: we carefully collected a high-quality bilingual dataset that covers common scenes, document images, and annotated them with English and Chinese question-answer pairs, significantly enhancing performance in OCR- and Chinese-related tasks. We evaluate InternVL 1.5 through a series of benchmarks and comparative studies. Compared to both open-source and proprietary models, InternVL 1.5 shows competitive performance, achieving state-of-the-art results in 8 of 18 benchmarks. Code has been released at https://github.com/OpenGVLab/InternVL.
Efficient Deformable ConvNets: Rethinking Dynamic and Sparse Operator for Vision Applications
Jan 11, 2024
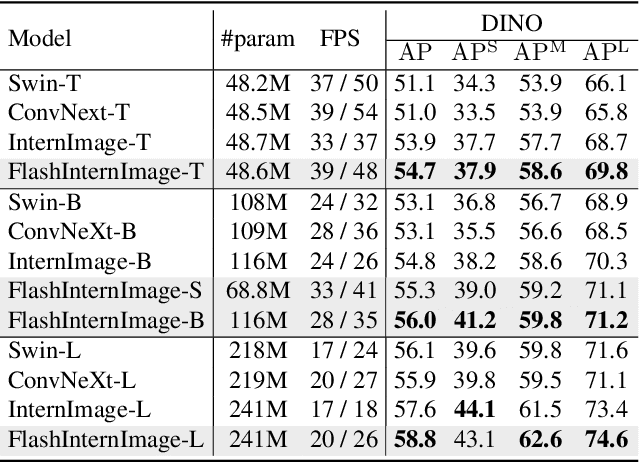

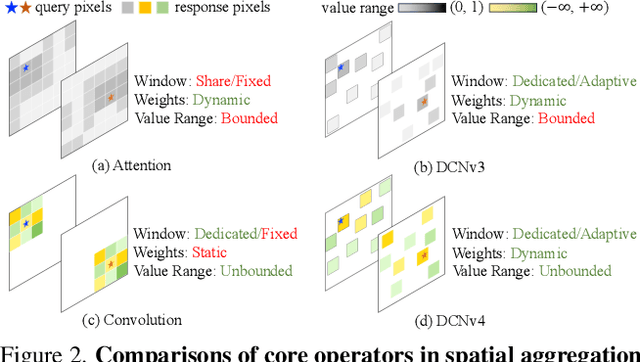
We introduce Deformable Convolution v4 (DCNv4), a highly efficient and effective operator designed for a broad spectrum of vision applications. DCNv4 addresses the limitations of its predecessor, DCNv3, with two key enhancements: 1. removing softmax normalization in spatial aggregation to enhance its dynamic property and expressive power and 2. optimizing memory access to minimize redundant operations for speedup. These improvements result in a significantly faster convergence compared to DCNv3 and a substantial increase in processing speed, with DCNv4 achieving more than three times the forward speed. DCNv4 demonstrates exceptional performance across various tasks, including image classification, instance and semantic segmentation, and notably, image generation. When integrated into generative models like U-Net in the latent diffusion model, DCNv4 outperforms its baseline, underscoring its possibility to enhance generative models. In practical applications, replacing DCNv3 with DCNv4 in the InternImage model to create FlashInternImage results in up to 80% speed increase and further performance improvement without further modifications. The advancements in speed and efficiency of DCNv4, combined with its robust performance across diverse vision tasks, show its potential as a foundational building block for future vision models.
An Efficient FPGA-based Accelerator for Deep Forest
Nov 04, 2022Deep Forest is a prominent machine learning algorithm known for its high accuracy in forecasting. Compared with deep neural networks, Deep Forest has almost no multiplication operations and has better performance on small datasets. However, due to the deep structure and large forest quantity, it suffers from large amounts of calculation and memory consumption. In this paper, an efficient hardware accelerator is proposed for deep forest models, which is also the first work to implement Deep Forest on FPGA. Firstly, a delicate node computing unit (NCU) is designed to improve inference speed. Secondly, based on NCU, an efficient architecture and an adaptive dataflow are proposed, in order to alleviate the problem of node computing imbalance in the classification process. Moreover, an optimized storage scheme in this design also improves hardware utilization and power efficiency. The proposed design is implemented on an FPGA board, Intel Stratix V, and it is evaluated by two typical datasets, ADULT and Face Mask Detection. The experimental results show that the proposed design can achieve around 40x speedup compared to that on a 40 cores high performance x86 CPU.