 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePAG: Multi-Turn Reinforced LLM Self-Correction with Policy as Generative Verifier
Jun 12, 2025Large Language Models (LLMs) have demonstrated impressive capabilities in complex reasoning tasks, yet they still struggle to reliably verify the correctness of their own outputs. Existing solutions to this verification challenge often depend on separate verifier models or require multi-stage self-correction training pipelines, which limit scalability. In this paper, we propose Policy as Generative Verifier (PAG), a simple and effective framework that empowers LLMs to self-correct by alternating between policy and verifier roles within a unified multi-turn reinforcement learning (RL) paradigm. Distinct from prior approaches that always generate a second attempt regardless of model confidence, PAG introduces a selective revision mechanism: the model revises its answer only when its own generative verification step detects an error. This verify-then-revise workflow not only alleviates model collapse but also jointly enhances both reasoning and verification abilities. Extensive experiments across diverse reasoning benchmarks highlight PAG's dual advancements: as a policy, it enhances direct generation and self-correction accuracy; as a verifier, its self-verification outperforms self-consistency.
Seed1.5-VL Technical Report
May 11, 2025



We present Seed1.5-VL, a vision-language foundation model designed to advance general-purpose multimodal understanding and reasoning. Seed1.5-VL is composed with a 532M-parameter vision encoder and a Mixture-of-Experts (MoE) LLM of 20B active parameters. Despite its relatively compact architecture, it delivers strong performance across a wide spectrum of public VLM benchmarks and internal evaluation suites, achieving the state-of-the-art performance on 38 out of 60 public benchmarks. Moreover, in agent-centric tasks such as GUI control and gameplay, Seed1.5-VL outperforms leading multimodal systems, including OpenAI CUA and Claude 3.7. Beyond visual and video understanding, it also demonstrates strong reasoning abilities, making it particularly effective for multimodal reasoning challenges such as visual puzzles. We believe these capabilities will empower broader applications across diverse tasks. In this report, we mainly provide a comprehensive review of our experiences in building Seed1.5-VL across model design, data construction, and training at various stages, hoping that this report can inspire further research. Seed1.5-VL is now accessible at https://www.volcengine.com/ (Volcano Engine Model ID: doubao-1-5-thinking-vision-pro-250428)
LangBridge: Interpreting Image as a Combination of Language Embeddings
Mar 26, 2025



Recent years have witnessed remarkable advances in Large Vision-Language Models (LVLMs), which have achieved human-level performance across various complex vision-language tasks. Following LLaVA's paradigm, mainstream LVLMs typically employ a shallow MLP for visual-language alignment through a two-stage training process: pretraining for cross-modal alignment followed by instruction tuning. While this approach has proven effective, the underlying mechanisms of how MLPs bridge the modality gap remain poorly understood. Although some research has explored how LLMs process transformed visual tokens, few studies have investigated the fundamental alignment mechanism. Furthermore, the MLP adapter requires retraining whenever switching LLM backbones. To address these limitations, we first investigate the working principles of MLP adapters and discover that they learn to project visual embeddings into subspaces spanned by corresponding text embeddings progressively. Based on this insight, we propose LangBridge, a novel adapter that explicitly maps visual tokens to linear combinations of LLM vocabulary embeddings. This innovative design enables pretraining-free adapter transfer across different LLMs while maintaining performance. Our experimental results demonstrate that a LangBridge adapter pre-trained on Qwen2-0.5B can be directly applied to larger models such as LLaMA3-8B or Qwen2.5-14B while maintaining competitive performance. Overall, LangBridge enables interpretable vision-language alignment by grounding visual representations in LLM vocab embedding, while its plug-and-play design ensures efficient reuse across multiple LLMs with nearly no performance degradation. See our project page at https://jiaqiliao77.github.io/LangBridge.github.io/
Dita: Scaling Diffusion Transformer for Generalist Vision-Language-Action Policy
Mar 25, 2025While recent vision-language-action models trained on diverse robot datasets exhibit promising generalization capabilities with limited in-domain data, their reliance on compact action heads to predict discretized or continuous actions constrains adaptability to heterogeneous action spaces. We present Dita, a scalable framework that leverages Transformer architectures to directly denoise continuous action sequences through a unified multimodal diffusion process. Departing from prior methods that condition denoising on fused embeddings via shallow networks, Dita employs in-context conditioning -- enabling fine-grained alignment between denoised actions and raw visual tokens from historical observations. This design explicitly models action deltas and environmental nuances. By scaling the diffusion action denoiser alongside the Transformer's scalability, Dita effectively integrates cross-embodiment datasets across diverse camera perspectives, observation scenes, tasks, and action spaces. Such synergy enhances robustness against various variances and facilitates the successful execution of long-horizon tasks. Evaluations across extensive benchmarks demonstrate state-of-the-art or comparative performance in simulation. Notably, Dita achieves robust real-world adaptation to environmental variances and complex long-horizon tasks through 10-shot finetuning, using only third-person camera inputs. The architecture establishes a versatile, lightweight and open-source baseline for generalist robot policy learning. Project Page: https://robodita.github.io.
HoloDrive: Holistic 2D-3D Multi-Modal Street Scene Generation for Autonomous Driving
Dec 03, 2024



Generative models have significantly improved the generation and prediction quality on either camera images or LiDAR point clouds for autonomous driving. However, a real-world autonomous driving system uses multiple kinds of input modality, usually cameras and LiDARs, where they contain complementary information for generation, while existing generation methods ignore this crucial feature, resulting in the generated results only covering separate 2D or 3D information. In order to fill the gap in 2D-3D multi-modal joint generation for autonomous driving, in this paper, we propose our framework, \emph{HoloDrive}, to jointly generate the camera images and LiDAR point clouds. We employ BEV-to-Camera and Camera-to-BEV transform modules between heterogeneous generative models, and introduce a depth prediction branch in the 2D generative model to disambiguate the un-projecting from image space to BEV space, then extend the method to predict the future by adding temporal structure and carefully designed progressive training. Further, we conduct experiments on single frame generation and world model benchmarks, and demonstrate our method leads to significant performance gains over SOTA methods in terms of generation metrics.
Diffusion Transformer Policy
Oct 21, 2024



Recent large visual-language action models pretrained on diverse robot datasets have demonstrated the potential for generalizing to new environments with a few in-domain data. However, those approaches usually predict discretized or continuous actions by a small action head, which limits the ability in handling diverse action spaces. In contrast, we model the continuous action with a large multi-modal diffusion transformer, dubbed as Diffusion Transformer Policy, in which we directly denoise action chunks by a large transformer model rather than a small action head. By leveraging the scaling capability of transformers, the proposed approach can effectively model continuous end-effector actions across large diverse robot datasets, and achieve better generalization performance. Extensive experiments demonstrate Diffusion Transformer Policy pretrained on diverse robot data can generalize to different embodiments, including simulation environments like Maniskill2 and Calvin, as well as the real-world Franka arm. Specifically, without bells and whistles, the proposed approach achieves state-of-the-art performance with only a single third-view camera stream in the Calvin novel task setting (ABC->D), improving the average number of tasks completed in a row of 5 to 3.6, and the pretraining stage significantly facilitates the success sequence length on the Calvin by over 1.2. The code will be publicly available.
big.LITTLE Vision Transformer for Efficient Visual Recognition
Oct 14, 2024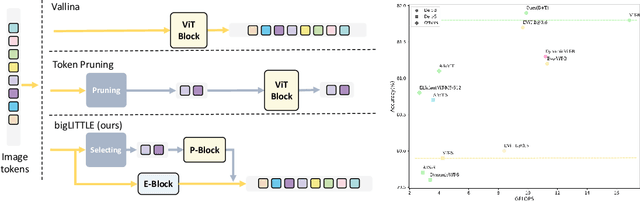
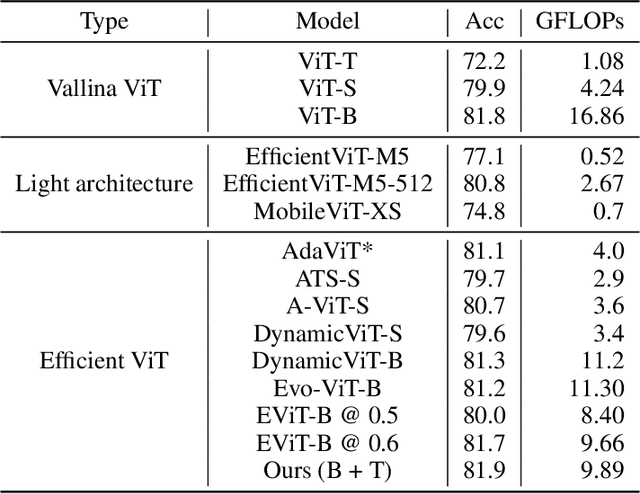
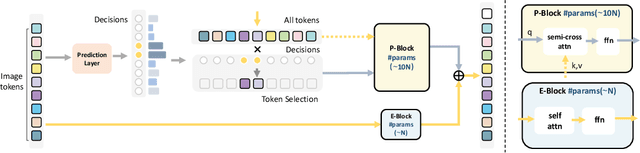

In this paper, we introduce the big.LITTLE Vision Transformer, an innovative architecture aimed at achieving efficient visual recognition. This dual-transformer system is composed of two distinct blocks: the big performance block, characterized by its high capacity and substantial computational demands, and the LITTLE efficiency block, designed for speed with lower capacity. The key innovation of our approach lies in its dynamic inference mechanism. When processing an image, our system determines the importance of each token and allocates them accordingly: essential tokens are processed by the high-performance big model, while less critical tokens are handled by the more efficient little model. This selective processing significantly reduces computational load without sacrificing the overall performance of the model, as it ensures that detailed analysis is reserved for the most important information. To validate the effectiveness of our big.LITTLE Vision Transformer, we conducted comprehensive experiments on image classification and segment anything task. Our results demonstrate that the big.LITTLE architecture not only maintains high accuracy but also achieves substantial computational savings. Specifically, our approach enables the efficient handling of large-scale visual recognition tasks by dynamically balancing the trade-offs between performance and efficiency. The success of our method underscores the potential of hybrid models in optimizing both computation and performance in visual recognition tasks, paving the way for more practical and scalable deployment of advanced neural networks in real-world applications.
PooDLe: Pooled and dense self-supervised learning from naturalistic videos
Aug 20, 2024



Self-supervised learning has driven significant progress in learning from single-subject, iconic images. However, there are still unanswered questions about the use of minimally-curated, naturalistic video data, which contain dense scenes with many independent objects, imbalanced class distributions, and varying object sizes. In this paper, we propose a novel approach that combines an invariance-based SSL objective on pooled representations with a dense SSL objective that enforces equivariance to optical flow warping. Our findings indicate that a unified objective applied at multiple feature scales is essential for learning effective image representations from high-resolution, naturalistic videos. We validate our approach on the BDD100K driving video dataset and the Walking Tours first-person video dataset, demonstrating its ability to capture spatial understanding from a dense objective and semantic understanding via a pooled representation objective.
MM-Interleaved: Interleaved Image-Text Generative Modeling via Multi-modal Feature Synchronizer
Jan 18, 2024

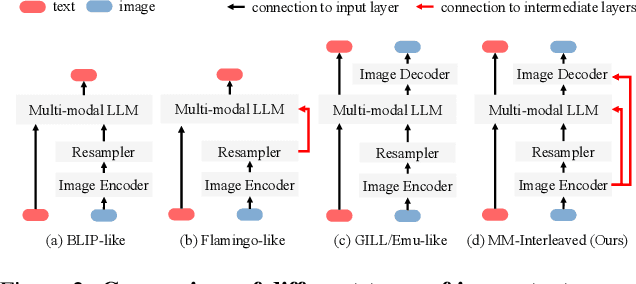

Developing generative models for interleaved image-text data has both research and practical value. It requires models to understand the interleaved sequences and subsequently generate images and text. However, existing attempts are limited by the issue that the fixed number of visual tokens cannot efficiently capture image details, which is particularly problematic in the multi-image scenarios. To address this, this paper presents MM-Interleaved, an end-to-end generative model for interleaved image-text data. It introduces a multi-scale and multi-image feature synchronizer module, allowing direct access to fine-grained image features in the previous context during the generation process. MM-Interleaved is end-to-end pre-trained on both paired and interleaved image-text corpora. It is further enhanced through a supervised fine-tuning phase, wherein the model improves its ability to follow complex multi-modal instructions. Experiments demonstrate the versatility of MM-Interleaved in recognizing visual details following multi-modal instructions and generating consistent images following both textual and visual conditions. Code and models are available at \url{https://github.com/OpenGVLab/MM-Interleaved}.
Efficient Deformable ConvNets: Rethinking Dynamic and Sparse Operator for Vision Applications
Jan 11, 2024
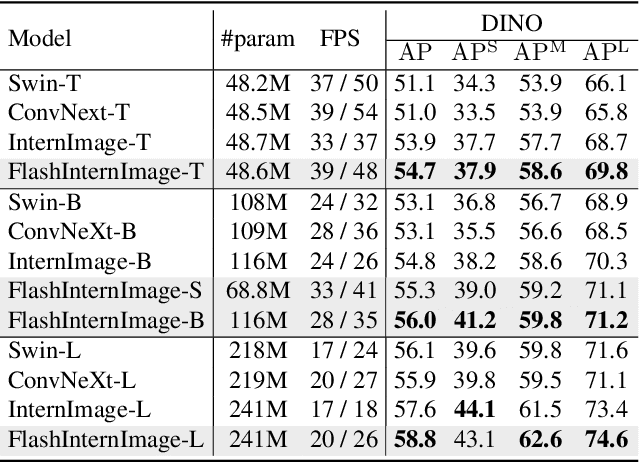

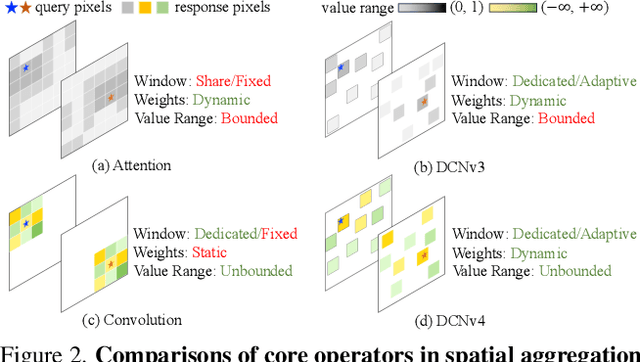
We introduce Deformable Convolution v4 (DCNv4), a highly efficient and effective operator designed for a broad spectrum of vision applications. DCNv4 addresses the limitations of its predecessor, DCNv3, with two key enhancements: 1. removing softmax normalization in spatial aggregation to enhance its dynamic property and expressive power and 2. optimizing memory access to minimize redundant operations for speedup. These improvements result in a significantly faster convergence compared to DCNv3 and a substantial increase in processing speed, with DCNv4 achieving more than three times the forward speed. DCNv4 demonstrates exceptional performance across various tasks, including image classification, instance and semantic segmentation, and notably, image generation. When integrated into generative models like U-Net in the latent diffusion model, DCNv4 outperforms its baseline, underscoring its possibility to enhance generative models. In practical applications, replacing DCNv3 with DCNv4 in the InternImage model to create FlashInternImage results in up to 80% speed increase and further performance improvement without further modifications. The advancements in speed and efficiency of DCNv4, combined with its robust performance across diverse vision tasks, show its potential as a foundational building block for future vision models.