 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscrete JEPA: Learning Discrete Token Representations without Reconstruction
Jun 17, 2025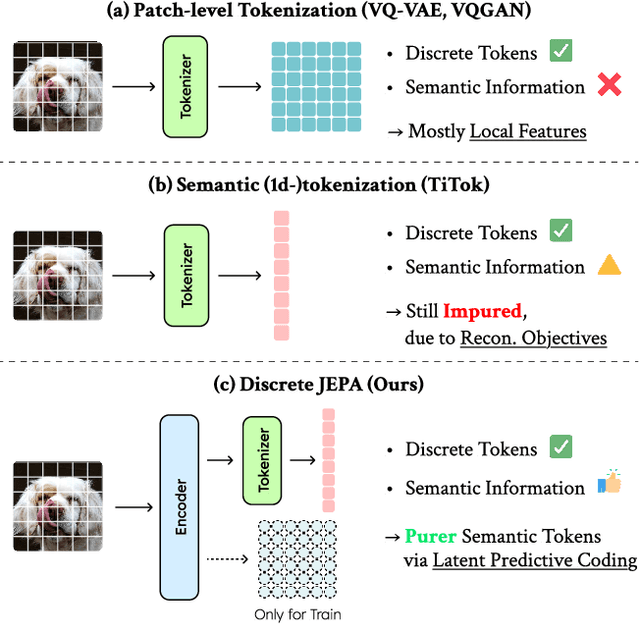
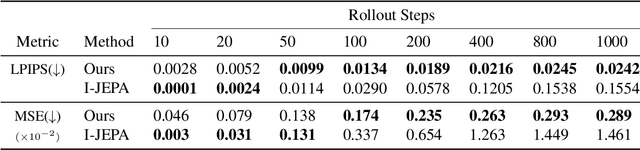
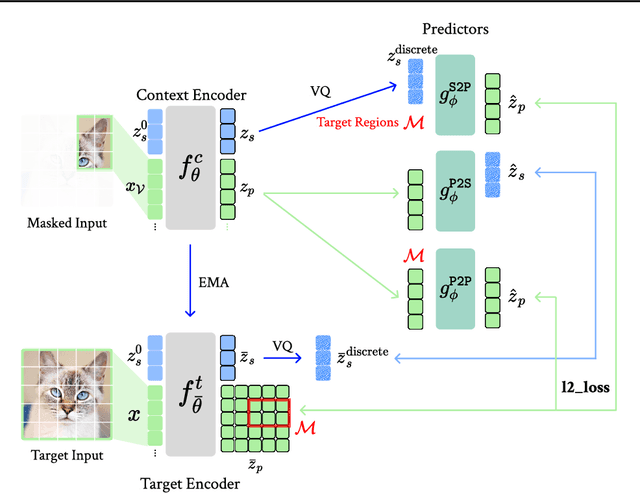
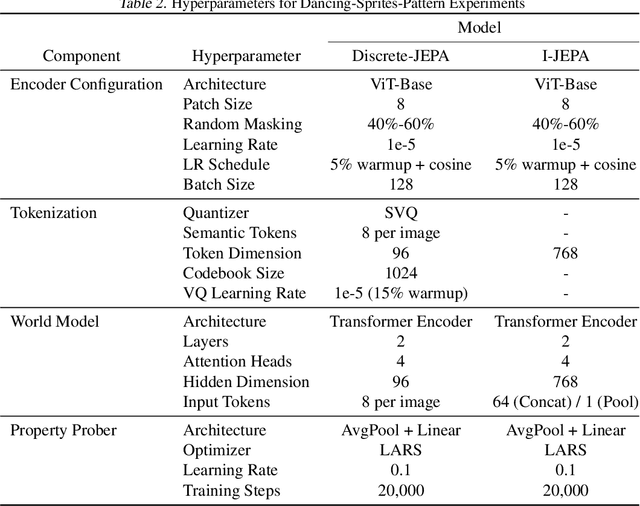
The cornerstone of cognitive intelligence lies in extracting hidden patterns from observations and leveraging these principles to systematically predict future outcomes. However, current image tokenization methods demonstrate significant limitations in tasks requiring symbolic abstraction and logical reasoning capabilities essential for systematic inference. To address this challenge, we propose Discrete-JEPA, extending the latent predictive coding framework with semantic tokenization and novel complementary objectives to create robust tokenization for symbolic reasoning tasks. Discrete-JEPA dramatically outperforms baselines on visual symbolic prediction tasks, while striking visual evidence reveals the spontaneous emergence of deliberate systematic patterns within the learned semantic token space. Though an initial model, our approach promises a significant impact for advancing Symbolic world modeling and planning capabilities in artificial intelligence systems.
Replay Can Provably Increase Forgetting
Jun 04, 2025Continual learning seeks to enable machine learning systems to solve an increasing corpus of tasks sequentially. A critical challenge for continual learning is forgetting, where the performance on previously learned tasks decreases as new tasks are introduced. One of the commonly used techniques to mitigate forgetting, sample replay, has been shown empirically to reduce forgetting by retaining some examples from old tasks and including them in new training episodes. In this work, we provide a theoretical analysis of sample replay in an over-parameterized continual linear regression setting, where each task is given by a linear subspace and with enough replay samples, one would be able to eliminate forgetting. Our analysis focuses on sample replay and highlights the role of the replayed samples and the relationship between task subspaces. Surprisingly, we find that, even in a noiseless setting, forgetting can be non-monotonic with respect to the number of replay samples. We present tasks where replay can be harmful with respect to worst-case settings, and also in distributional settings where replay of randomly selected samples increases forgetting in expectation. We also give empirical evidence that harmful replay is not limited to training with linear models by showing similar behavior for a neural networks equipped with SGD. Through experiments on a commonly used benchmark, we provide additional evidence that, even in seemingly benign scenarios, performance of the replay heavily depends on the choice of replay samples and the relationship between tasks.
Memory Storyboard: Leveraging Temporal Segmentation for Streaming Self-Supervised Learning from Egocentric Videos
Jan 21, 2025



Self-supervised learning holds the promise to learn good representations from real-world continuous uncurated data streams. However, most existing works in visual self-supervised learning focus on static images or artificial data streams. Towards exploring a more realistic learning substrate, we investigate streaming self-supervised learning from long-form real-world egocentric video streams. Inspired by the event segmentation mechanism in human perception and memory, we propose "Memory Storyboard" that groups recent past frames into temporal segments for more effective summarization of the past visual streams for memory replay. To accommodate efficient temporal segmentation, we propose a two-tier memory hierarchy: the recent past is stored in a short-term memory, and the storyboard temporal segments are then transferred to a long-term memory. Experiments on real-world egocentric video datasets including SAYCam and KrishnaCam show that contrastive learning objectives on top of storyboard frames result in semantically meaningful representations which outperform those produced by state-of-the-art unsupervised continual learning methods.
A General Framework for Inference-time Scaling and Steering of Diffusion Models
Jan 16, 2025Diffusion models produce impressive results in modalities ranging from images and video to protein design and text. However, generating samples with user-specified properties remains a challenge. Recent research proposes fine-tuning models to maximize rewards that capture desired properties, but these methods require expensive training and are prone to mode collapse. In this work, we propose Feynman Kac (FK) steering, an inference-time framework for steering diffusion models with reward functions. FK steering works by sampling a system of multiple interacting diffusion processes, called particles, and resampling particles at intermediate steps based on scores computed using functions called potentials. Potentials are defined using rewards for intermediate states and are selected such that a high value indicates that the particle will yield a high-reward sample. We explore various choices of potentials, intermediate rewards, and samplers. We evaluate FK steering on text-to-image and text diffusion models. For steering text-to-image models with a human preference reward, we find that FK steering a 0.8B parameter model outperforms a 2.6B parameter fine-tuned model on prompt fidelity, with faster sampling and no training. For steering text diffusion models with rewards for text quality and specific text attributes, we find that FK steering generates lower perplexity, more linguistically acceptable outputs and enables gradient-free control of attributes like toxicity. Our results demonstrate that inference-time scaling and steering of diffusion models, even with off-the-shelf rewards, can provide significant sample quality gains and controllability benefits. Code is available at https://github.com/zacharyhorvitz/Fk-Diffusion-Steering .
Are LLMs Prescient? A Continuous Evaluation using Daily News as the Oracle
Nov 13, 2024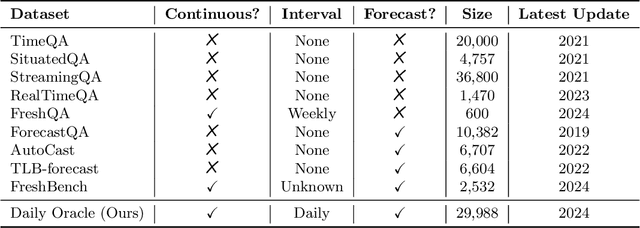
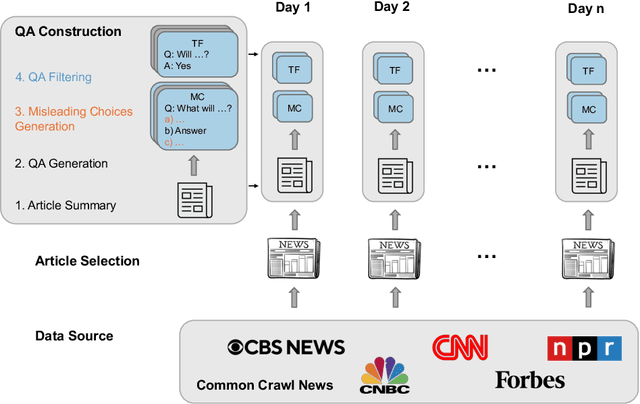
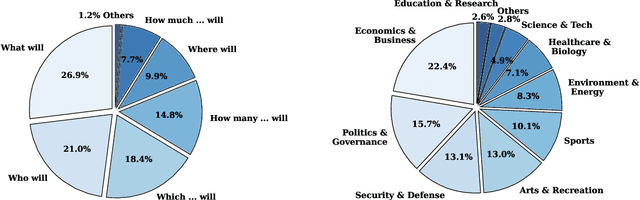
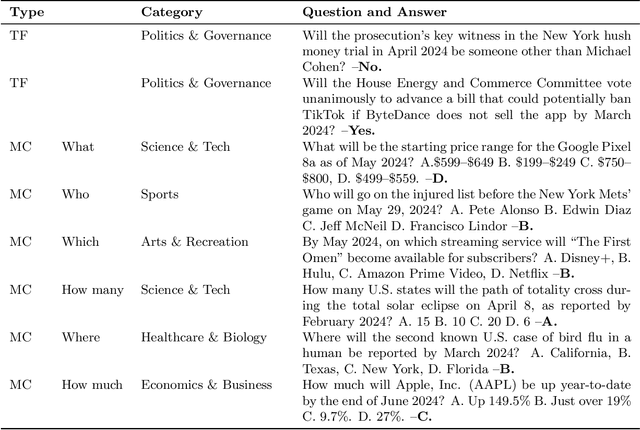
Many existing evaluation benchmarks for Large Language Models (LLMs) quickly become outdated due to the emergence of new models and training data. These benchmarks also fall short in assessing how LLM performance changes over time, as they consist of static questions without a temporal dimension. To address these limitations, we propose using future event prediction as a continuous evaluation method to assess LLMs' temporal generalization and forecasting abilities. Our benchmark, Daily Oracle, automatically generates question-answer (QA) pairs from daily news, challenging LLMs to predict "future" event outcomes. Our findings reveal that as pre-training data becomes outdated, LLM performance degrades over time. While Retrieval Augmented Generation (RAG) has the potential to enhance prediction accuracy, the performance degradation pattern persists, highlighting the need for continuous model updates.
PooDLe: Pooled and dense self-supervised learning from naturalistic videos
Aug 20, 2024



Self-supervised learning has driven significant progress in learning from single-subject, iconic images. However, there are still unanswered questions about the use of minimally-curated, naturalistic video data, which contain dense scenes with many independent objects, imbalanced class distributions, and varying object sizes. In this paper, we propose a novel approach that combines an invariance-based SSL objective on pooled representations with a dense SSL objective that enforces equivariance to optical flow warping. Our findings indicate that a unified objective applied at multiple feature scales is essential for learning effective image representations from high-resolution, naturalistic videos. We validate our approach on the BDD100K driving video dataset and the Walking Tours first-person video dataset, demonstrating its ability to capture spatial understanding from a dense objective and semantic understanding via a pooled representation objective.
ProCreate, Don't Reproduce! Propulsive Energy Diffusion for Creative Generation
Aug 06, 2024
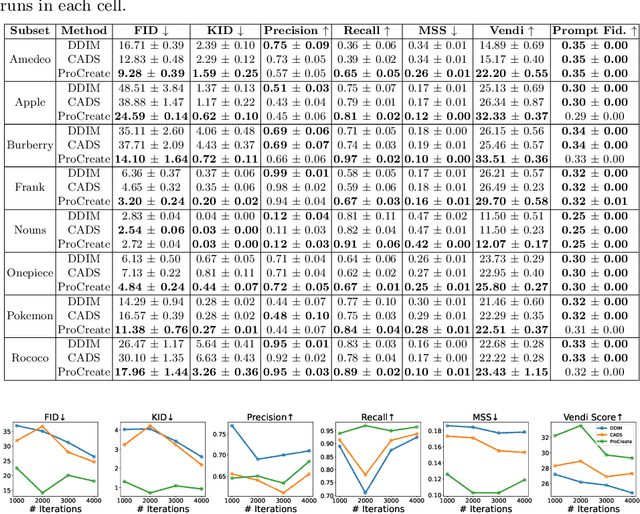
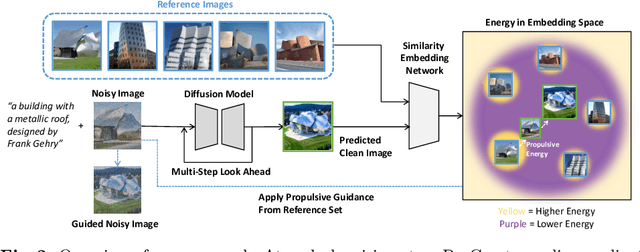
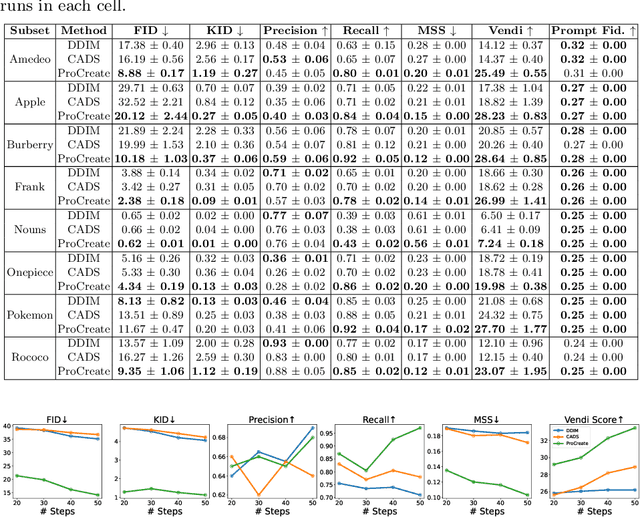
In this paper, we propose ProCreate, a simple and easy-to-implement method to improve sample diversity and creativity of diffusion-based image generative models and to prevent training data reproduction. ProCreate operates on a set of reference images and actively propels the generated image embedding away from the reference embeddings during the generation process. We propose FSCG-8 (Few-Shot Creative Generation 8), a few-shot creative generation dataset on eight different categories -- encompassing different concepts, styles, and settings -- in which ProCreate achieves the highest sample diversity and fidelity. Furthermore, we show that ProCreate is effective at preventing replicating training data in a large-scale evaluation using training text prompts. Code and FSCG-8 are available at https://github.com/Agentic-Learning-AI-Lab/procreate-diffusion-public. The project page is available at https://procreate-diffusion.github.io.
Integrating Present and Past in Unsupervised Continual Learning
Apr 29, 2024



We formulate a unifying framework for unsupervised continual learning (UCL), which disentangles learning objectives that are specific to the present and the past data, encompassing stability, plasticity, and cross-task consolidation. The framework reveals that many existing UCL approaches overlook cross-task consolidation and try to balance plasticity and stability in a shared embedding space. This results in worse performance due to a lack of within-task data diversity and reduced effectiveness in learning the current task. Our method, Osiris, which explicitly optimizes all three objectives on separate embedding spaces, achieves state-of-the-art performance on all benchmarks, including two novel benchmarks proposed in this paper featuring semantically structured task sequences. Compared to standard benchmarks, these two structured benchmarks more closely resemble visual signals received by humans and animals when navigating real-world environments. Finally, we show some preliminary evidence that continual models can benefit from such realistic learning scenarios.
CoLLEGe: Concept Embedding Generation for Large Language Models
Mar 22, 2024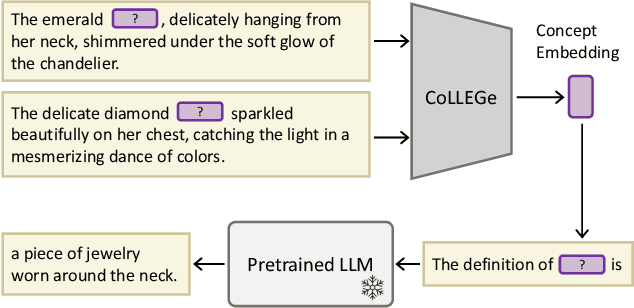

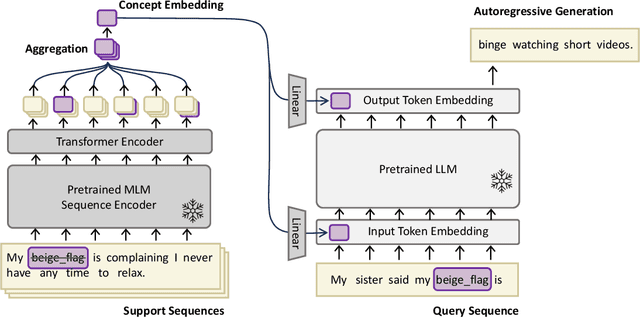

Current language models are unable to quickly learn new concepts on the fly, often requiring a more involved finetuning process to learn robustly. Prompting in-context is not robust to context distractions, and often fails to confer much information about the new concepts. Classic methods for few-shot word learning in NLP, relying on global word vectors, are less applicable to large language models. In this paper, we introduce a novel approach named CoLLEGe (Concept Learning with Language Embedding Generation) to modernize few-shot concept learning. CoLLEGe is a meta-learning framework capable of generating flexible embeddings for new concepts using a small number of example sentences or definitions. Our primary meta-learning objective is simply to facilitate a language model to make next word predictions in forthcoming sentences, making it compatible with language model pretraining. We design a series of tasks to test new concept learning in challenging real-world scenarios, including new word acquisition, definition inference, and verbal reasoning, and demonstrate that our method succeeds in each setting without task-specific training.
Reawakening knowledge: Anticipatory recovery from catastrophic interference via structured training
Mar 14, 2024



We explore the training dynamics of neural networks in a structured non-IID setting where documents are presented cyclically in a fixed, repeated sequence. Typically, networks suffer from catastrophic interference when training on a sequence of documents; however, we discover a curious and remarkable property of LLMs fine-tuned sequentially in this setting: they exhibit anticipatory behavior, recovering from the forgetting on documents before encountering them again. The behavior emerges and becomes more robust as the architecture scales up its number of parameters. Through comprehensive experiments and visualizations, we uncover new insights into training over-parameterized networks in structured environments.