 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA General Framework for Inference-time Scaling and Steering of Diffusion Models
Jan 16, 2025



Diffusion models produce impressive results in modalities ranging from images and video to protein design and text. However, generating samples with user-specified properties remains a challenge. Recent research proposes fine-tuning models to maximize rewards that capture desired properties, but these methods require expensive training and are prone to mode collapse. In this work, we propose Feynman Kac (FK) steering, an inference-time framework for steering diffusion models with reward functions. FK steering works by sampling a system of multiple interacting diffusion processes, called particles, and resampling particles at intermediate steps based on scores computed using functions called potentials. Potentials are defined using rewards for intermediate states and are selected such that a high value indicates that the particle will yield a high-reward sample. We explore various choices of potentials, intermediate rewards, and samplers. We evaluate FK steering on text-to-image and text diffusion models. For steering text-to-image models with a human preference reward, we find that FK steering a 0.8B parameter model outperforms a 2.6B parameter fine-tuned model on prompt fidelity, with faster sampling and no training. For steering text diffusion models with rewards for text quality and specific text attributes, we find that FK steering generates lower perplexity, more linguistically acceptable outputs and enables gradient-free control of attributes like toxicity. Our results demonstrate that inference-time scaling and steering of diffusion models, even with off-the-shelf rewards, can provide significant sample quality gains and controllability benefits. Code is available at https://github.com/zacharyhorvitz/Fk-Diffusion-Steering .
StyleDistance: Stronger Content-Independent Style Embeddings with Synthetic Parallel Examples
Oct 16, 2024



Style representations aim to embed texts with similar writing styles closely and texts with different styles far apart, regardless of content. However, the contrastive triplets often used for training these representations may vary in both style and content, leading to potential content leakage in the representations. We introduce StyleDistance, a novel approach to training stronger content-independent style embeddings. We use a large language model to create a synthetic dataset of near-exact paraphrases with controlled style variations, and produce positive and negative examples across 40 distinct style features for precise contrastive learning. We assess the quality of our synthetic data and embeddings through human and automatic evaluations. StyleDistance enhances the content-independence of style embeddings, which generalize to real-world benchmarks and outperform leading style representations in downstream applications. Our model can be found at https://huggingface.co/StyleDistance/styledistance .
TinyStyler: Efficient Few-Shot Text Style Transfer with Authorship Embeddings
Jun 21, 2024
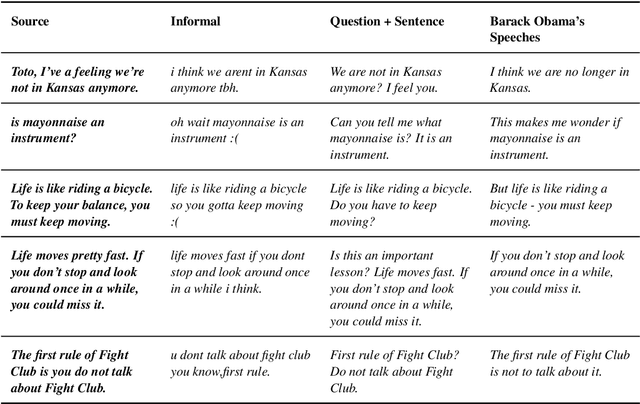
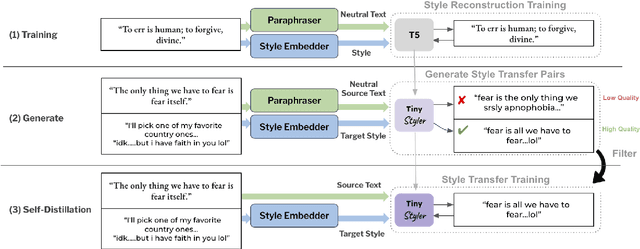
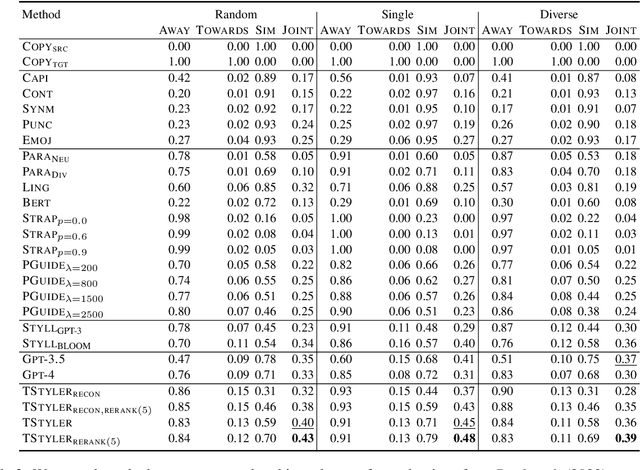
The goal of text style transfer is to transform the style of texts while preserving their original meaning, often with only a few examples of the target style. Existing style transfer methods generally rely on the few-shot capabilities of large language models or on complex controllable text generation approaches that are inefficient and underperform on fluency metrics. We introduce TinyStyler, a lightweight but effective approach, which leverages a small language model (800M params) and pre-trained authorship embeddings to perform efficient, few-shot text style transfer. We evaluate on the challenging task of authorship style transfer and find TinyStyler outperforms strong approaches such as GPT-4. We also evaluate TinyStyler's ability to perform text attribute style transfer (formal $\leftrightarrow$ informal) with automatic and human evaluations and find that the approach outperforms recent controllable text generation methods. Our model has been made publicly available at https://huggingface.co/tinystyler/tinystyler .
Getting Serious about Humor: Crafting Humor Datasets with Unfunny Large Language Models
Feb 23, 2024Humor is a fundamental facet of human cognition and interaction. Yet, despite recent advances in natural language processing, humor detection remains a challenging task that is complicated by the scarcity of datasets that pair humorous texts with similar non-humorous counterparts. In our work, we investigate whether large language models (LLMs), can generate synthetic data for humor detection via editing texts. We benchmark LLMs on an existing human dataset and show that current LLMs display an impressive ability to `unfun' jokes, as judged by humans and as measured on the downstream task of humor detection. We extend our approach to a code-mixed English-Hindi humor dataset, where we find that GPT-4's synthetic data is highly rated by bilingual annotators and provides challenging adversarial examples for humor classifiers.
ParaGuide: Guided Diffusion Paraphrasers for Plug-and-Play Textual Style Transfer
Sep 04, 2023



Textual style transfer is the task of transforming stylistic properties of text while preserving meaning. Target "styles" can be defined in numerous ways, ranging from single attributes (e.g, formality) to authorship (e.g, Shakespeare). Previous unsupervised style-transfer approaches generally rely on significant amounts of labeled data for only a fixed set of styles or require large language models. In contrast, we introduce a novel diffusion-based framework for general-purpose style transfer that can be flexibly adapted to arbitrary target styles at inference time. Our parameter-efficient approach, ParaGuide, leverages paraphrase-conditioned diffusion models alongside gradient-based guidance from both off-the-shelf classifiers and strong existing style embedders to transform the style of text while preserving semantic information. We validate the method on the Enron Email Corpus, with both human and automatic evaluations, and find that it outperforms strong baselines on formality, sentiment, and even authorship style transfer.