 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGetting Serious about Humor: Crafting Humor Datasets with Unfunny Large Language Models
Feb 23, 2024Humor is a fundamental facet of human cognition and interaction. Yet, despite recent advances in natural language processing, humor detection remains a challenging task that is complicated by the scarcity of datasets that pair humorous texts with similar non-humorous counterparts. In our work, we investigate whether large language models (LLMs), can generate synthetic data for humor detection via editing texts. We benchmark LLMs on an existing human dataset and show that current LLMs display an impressive ability to `unfun' jokes, as judged by humans and as measured on the downstream task of humor detection. We extend our approach to a code-mixed English-Hindi humor dataset, where we find that GPT-4's synthetic data is highly rated by bilingual annotators and provides challenging adversarial examples for humor classifiers.
CoRE-CoG: Conversational Recommendation of Entities using Constrained Generation
Nov 14, 2023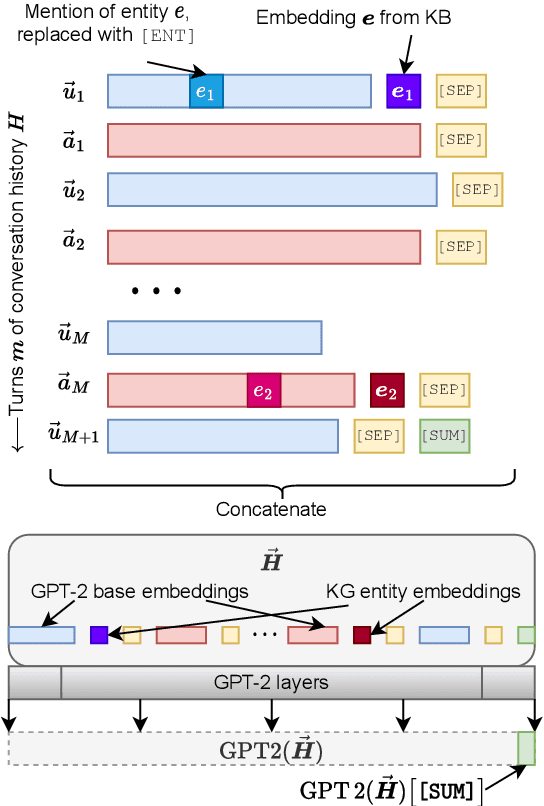



End-to-end conversational recommendation systems (CRS) generate responses by leveraging both dialog history and a knowledge base (KB). A CRS mainly faces three key challenges: (1) at each turn, it must decide if recommending a KB entity is appropriate; if so, it must identify the most relevant KB entity to recommend; and finally, it must recommend the entity in a fluent utterance that is consistent with the conversation history. Recent CRSs do not pay sufficient attention to these desiderata, often generating unfluent responses or not recommending (relevant) entities at the right turn. We introduce a new CRS we call CoRE-CoG. CoRE-CoG addresses the limitations in prior systems by implementing (1) a recommendation trigger that decides if the system utterance should include an entity, (2) a type pruning module that improves the relevance of recommended entities, and (3) a novel constrained response generator to make recommendations while maintaining fluency. Together, these modules ensure simultaneous accurate recommendation decisions and fluent system utterances. Experiments with recent benchmarks show the superiority particularly on conditional generation sub-tasks with close to 10 F1 and 4 Recall@1 percent points gain over baselines.
MMER: Multimodal Multi-task learning for Emotion Recognition in Spoken Utterances
Apr 01, 2022

Emotion Recognition (ER) aims to classify human utterances into different emotion categories. Based on early-fusion and self-attention-based multimodal interaction between text and acoustic modalities, in this paper, we propose a multimodal multitask learning approach for ER from individual utterances in isolation. Experiments on the IEMOCAP benchmark show that our proposed model performs better than our re-implementation of state-of-the-art and achieves better performance than all other unimodal and multimodal approaches in literature. In addition, strong baselines and ablation studies prove the effectiveness of our proposed approach. We make all our codes publicly available on GitHub.
A Discourse Aware Sequence Learning Approach for Emotion Recognition in Conversations
Apr 01, 2022
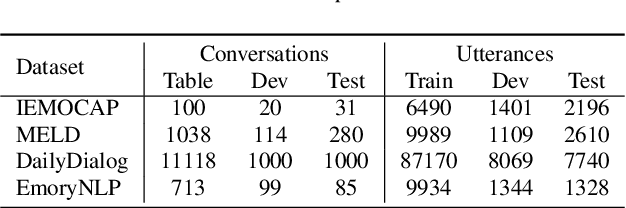
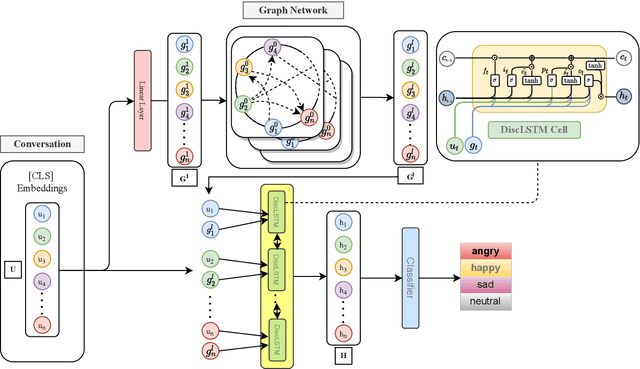
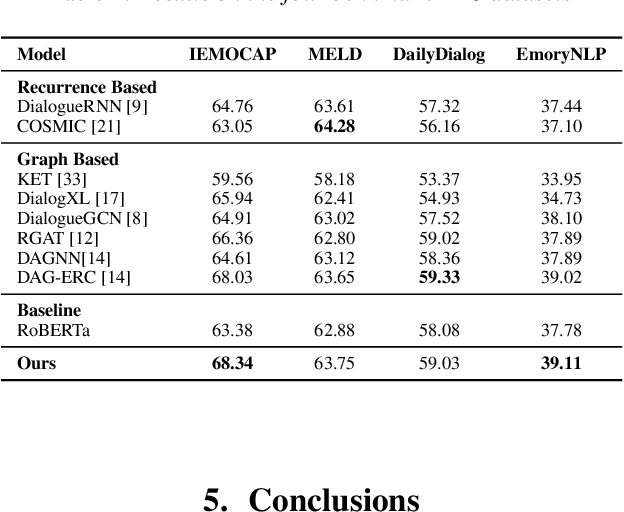
The expression of emotions is a crucial part of daily human communication. Modeling the conversational and sequential context has seen much success and plays a vital role in Emotion Recognition in Conversations (ERC). However, existing approaches either model only one of the two or employ naive late-fusion methodologies to obtain final utterance representations. This paper proposes a novel idea to incorporate both these contexts and better model the intrinsic structure within a conversation. More precisely, we propose a novel architecture boosted by a modified LSTM cell, which we call DiscLSTM, that better captures the interaction between conversational and sequential context. DiscLSTM brings together the best of both worlds and provides a more intuitive and efficient way to model the information flow between individual utterances by better capturing long-distance conversational background through discourse relations and sequential context through recurrence. We conduct experiments on four benchmark datasets for ERC and show that our model achieves performance competitive to state-of-the-art and at times performs better than other graph-based approaches in literature, with a conversational graph that is both sparse and avoids complicated edge relations like much of previous work. We make all our codes publicly available on GitHub.
Misogynistic Meme Detection using Early Fusion Model with Graph Network
Mar 31, 2022


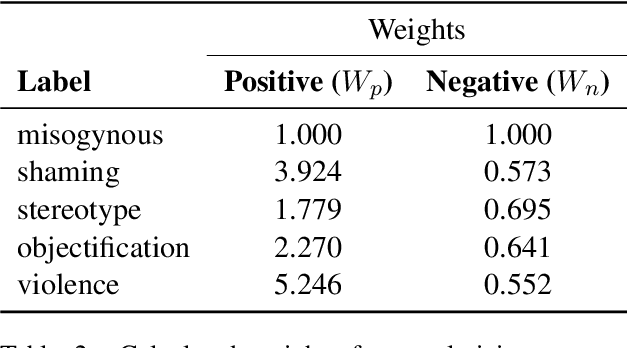
In recent years , there has been an upsurge in a new form of entertainment medium called memes. These memes although seemingly innocuous have transcended onto the boundary of online harassment against women and created an unwanted bias against them . To help alleviate this problem , we propose an early fusion model for prediction and identification of misogynistic memes and its type in this paper for which we participated in SemEval-2022 Task 5 . The model receives as input meme image with its text transcription with a target vector. Given that a key challenge with this task is the combination of different modalities to predict misogyny, our model relies on pretrained contextual representations from different state-of-the-art transformer-based language models and pretrained image pretrained models to get an effective image representation. Our model achieved competitive results on both SubTask-A and SubTask-B with the other competition teams and significantly outperforms the baselines.
Zero Shot Crosslingual Eye-Tracking Data Prediction using Multilingual Transformer Models
Mar 30, 2022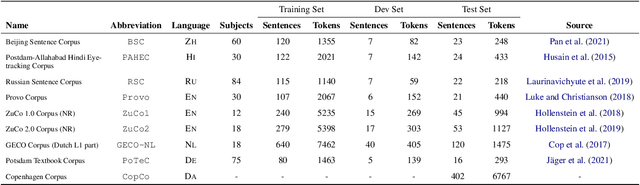



Eye tracking data during reading is a useful source of information to understand the cognitive processes that take place during language comprehension processes. Different languages account for different brain triggers , however there seems to be some uniform indicators. In this paper, we describe our submission to the CMCL 2022 shared task on predicting human reading patterns for multi-lingual dataset. Our model uses text representations from transformers and some hand engineered features with a regression layer on top to predict statistical measures of mean and standard deviation for 2 main eye-tracking features. We train an end to end model to extract meaningful information from different languages and test our model on two seperate datasets. We compare different transformer models and show ablation studies affecting model performance. Our final submission ranked 4th place for SubTask-1 and 1st place for SubTask-2 for the shared task.
IIT_kgp at FinCausal 2020, Shared Task 1: Causality Detection using Sentence Embeddings in Financial Reports
Nov 16, 2020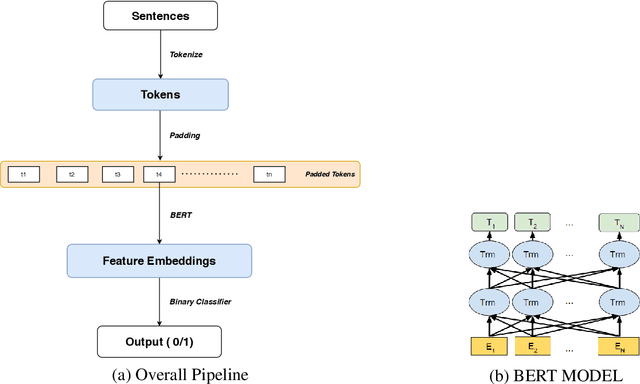
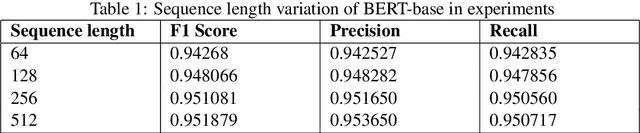
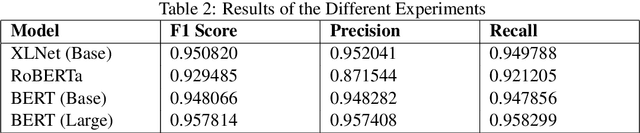
The paper describes the work that the team submitted to FinCausal 2020 Shared Task. This work is associated with the first sub-task of identifying causality in sentences. The various models used in the experiments tried to obtain a latent space representation for each of the sentences. Linear regression was performed on these representations to classify whether the sentence is causal or not. The experiments have shown BERT (Large) performed the best, giving a F1 score of 0.958, in the task of detecting the causality of sentences in financial texts and reports. The class imbalance was dealt with a modified loss function to give a better metric score for the evaluation.