 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Discourse Aware Sequence Learning Approach for Emotion Recognition in Conversations
Paper and Code
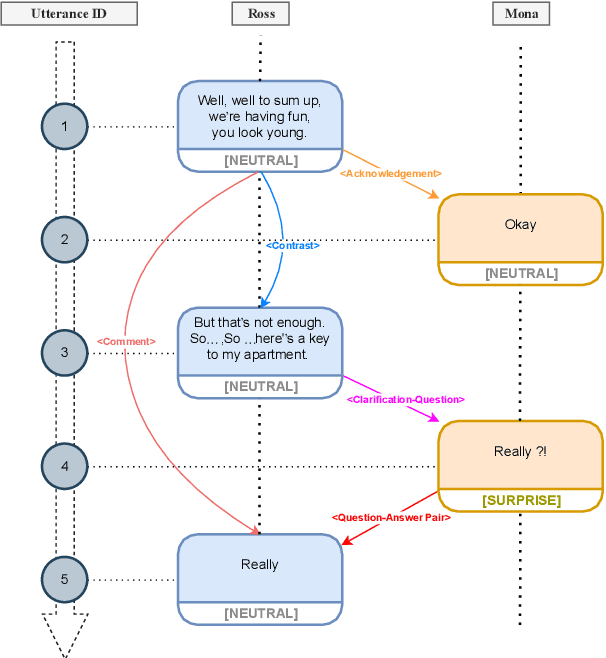
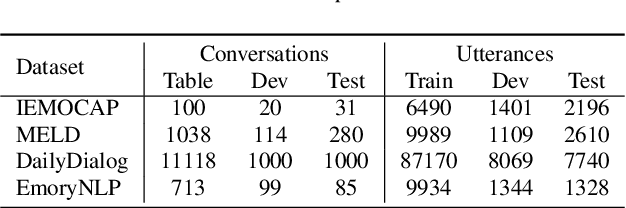
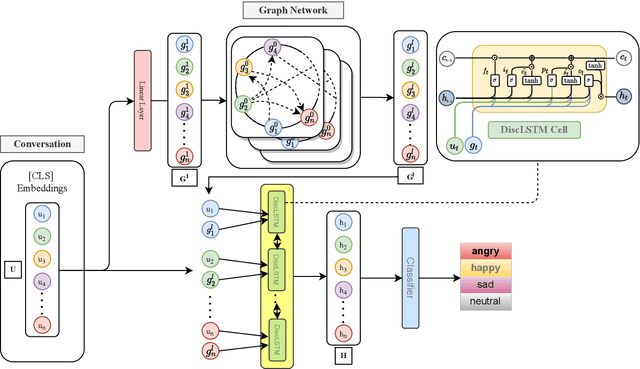
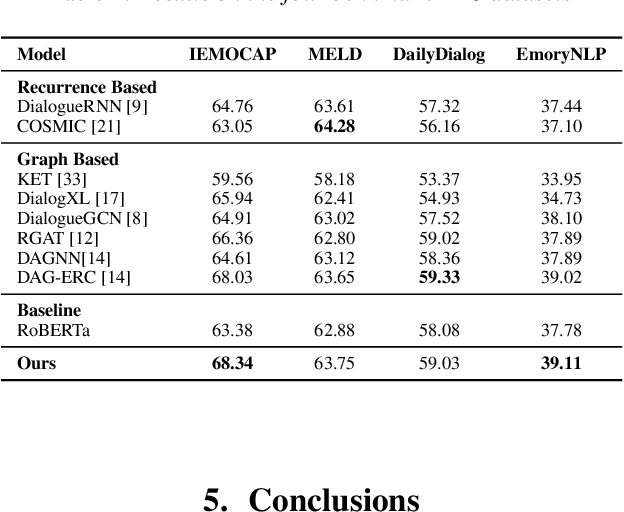
The expression of emotions is a crucial part of daily human communication. Modeling the conversational and sequential context has seen much success and plays a vital role in Emotion Recognition in Conversations (ERC). However, existing approaches either model only one of the two or employ naive late-fusion methodologies to obtain final utterance representations. This paper proposes a novel idea to incorporate both these contexts and better model the intrinsic structure within a conversation. More precisely, we propose a novel architecture boosted by a modified LSTM cell, which we call DiscLSTM, that better captures the interaction between conversational and sequential context. DiscLSTM brings together the best of both worlds and provides a more intuitive and efficient way to model the information flow between individual utterances by better capturing long-distance conversational background through discourse relations and sequential context through recurrence. We conduct experiments on four benchmark datasets for ERC and show that our model achieves performance competitive to state-of-the-art and at times performs better than other graph-based approaches in literature, with a conversational graph that is both sparse and avoids complicated edge relations like much of previous work. We make all our codes publicly available on GitHub.