 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero Shot Crosslingual Eye-Tracking Data Prediction using Multilingual Transformer Models
Paper and Code
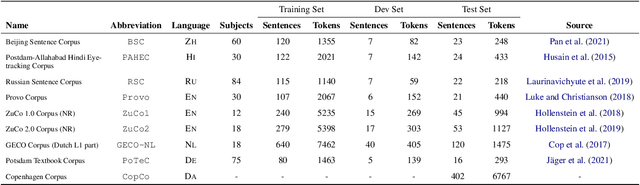



Eye tracking data during reading is a useful source of information to understand the cognitive processes that take place during language comprehension processes. Different languages account for different brain triggers , however there seems to be some uniform indicators. In this paper, we describe our submission to the CMCL 2022 shared task on predicting human reading patterns for multi-lingual dataset. Our model uses text representations from transformers and some hand engineered features with a regression layer on top to predict statistical measures of mean and standard deviation for 2 main eye-tracking features. We train an end to end model to extract meaningful information from different languages and test our model on two seperate datasets. We compare different transformer models and show ablation studies affecting model performance. Our final submission ranked 4th place for SubTask-1 and 1st place for SubTask-2 for the shared task.