Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIIT_kgp at FinCausal 2020, Shared Task 1: Causality Detection using Sentence Embeddings in Financial Reports
Paper and Code
Nov 16, 2020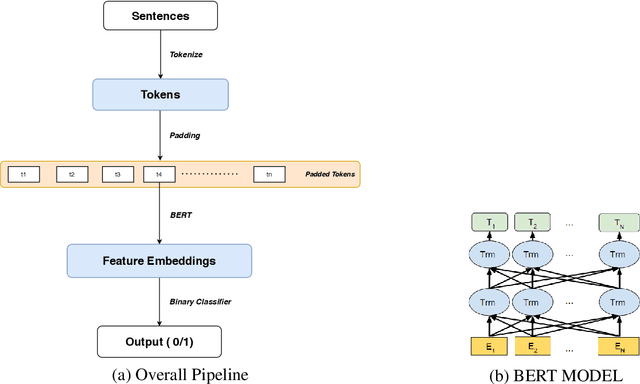
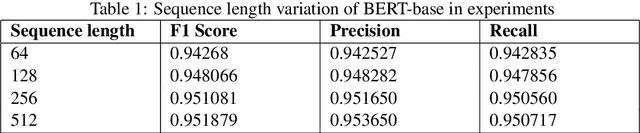
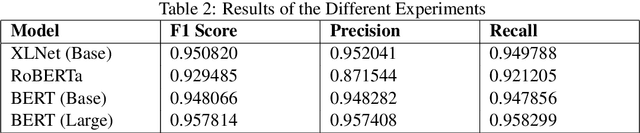
The paper describes the work that the team submitted to FinCausal 2020 Shared Task. This work is associated with the first sub-task of identifying causality in sentences. The various models used in the experiments tried to obtain a latent space representation for each of the sentences. Linear regression was performed on these representations to classify whether the sentence is causal or not. The experiments have shown BERT (Large) performed the best, giving a F1 score of 0.958, in the task of detecting the causality of sentences in financial texts and reports. The class imbalance was dealt with a modified loss function to give a better metric score for the evaluation.
View paper on